
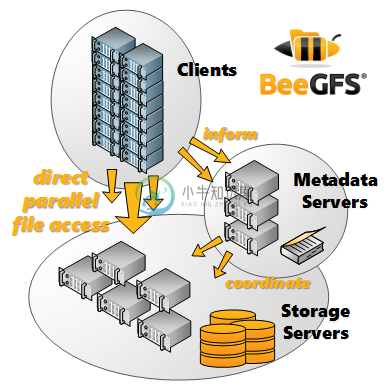
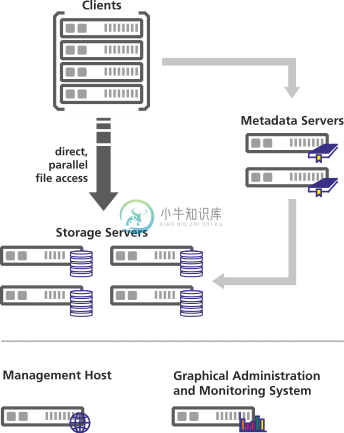
BeeGFS (前身是 FhGFS) 是一个高性能的并行文件系统,使用分布式元数据架构,具备可伸缩和灵活性来满足业务的需求。BeeGFS 是免费的,提供专业的商业服务支持。
BeeGFS (前身是 FhGFS) 是一个领先的并行集群文件系统,开发的重点是性能,易于安装和管理。
-
BeeGFS 的客户端是由一个内核模块和两个系统服务组成的,这里我们主要分析内核模块。内核模块主要实现了一个 Linux 的文件系统,因此注册了一个文件系统类型。因为 BeeGFS 的目录树解析,是在父目录 DEntry 里找子目录或文件 DEntry ,逐级迭代完成的,因此在 Mount 文件系统时,需要从管理节点获取根元数据节点的 ID ,然后再向根元数据节点查询根目录的 DEntry 的信息
-
同步任务初始化 // fhgfs_meta\source\app\App.cpp void App::initComponents(TargetConsistencyState initialConsistencyState) throw(ComponentInitException) { ... this->buddyResyncer = new BuddyResynce
-
BeeGFS 常用于高性能计算中的分布式文件存储,其对巨量小文件的支持相比于其他大多数文件系统而言,要好太多,这里介绍搭建的详细过程。一共使用 3 台服务器,一个磁盘分成两个区(分别用于元数据和数据存储),两个网卡(一个管理网,一个存储网)。 网络配置 网络分配 管理网络用于 SSH 登录等功能,都是千兆口,存储网络用于数据传输,为双万兆口 Mode 6 绑定。 主机名 管理网络 存储网络 服务部
-
元数据根节点的确定和获取 管理节点处理元数据节点的心跳信息时,如果发现目前没有Root节点,则会在已经注册的节点中选择ID最小的那个注册为元数据Root节点(这些信息最后都会保存在磁盘上): // fhgfs_mgmtd\source\components\HeartbeatManager.cpp /** * @param rootIDHint empty string to auto-defin
-
元数据服务是BeeGFS中用来维护文件和目录关系及其属性配置的服务,其多线程epoll设计实现非常高效,主要流程如下: ConnAcceptor(PThread)类(一个线程)负责监听端口,并接受客户端连接,然后把;连接信息(包含接收的套接字)写入管道; StreamListenerV2(PThread)类(多个线程,可配置)从管道读取连接信息,使用epoll轮询接收数据,然后生成Incoming
-
BeeGFS概述 BeeGFS(前身是 FhGFS)是一个高性能的并行文件系统,使用分布式元数据架构,具备可伸缩和灵活性来满足业务的需求。常用于高性能计算中的分布式文件存储,BeeGFS是免费的,提供专业的商业服务支持。 BeeGFS透明地将用户数据分布在多个服务器上。通过增加系统中的服务器和磁盘的数量,可以简单地将文件系统的性能和容量扩展到所需的级别,从小型集群无缝地扩展到具有数
-
1. 配置信息 ① Software 所有节点均为CentOS 7.1的虚拟机。 另外,物理机为百兆网卡,虚拟机为千兆网卡。 ② Host Services BeeGFS-01(192.168.28.165):Management Server BeeGFS-02(192.168.28.166):Metadata Server BeeGFS-03(192.168.28.167):Storage S
-
从 Version 7开始,BeeGFS引入了 beegfs-mon 守护进程,该进程从系统收集统计信息,然后使用时间序列数据库(InfluxDB)向用户提供。为了可视化数据,beegfs-mon 提供了预定义的Grafana面板,用户可以直接使用这些面板,也可以使用任何他们喜欢的工具。 安装 beegfs-mon服务以及Grafana面板都包含在 beegfs-mon安装包中。该安装包在BeeG
-
编译整体模块 需要将gcc版本升级到高版本,支持C++14 yum install libuuid-devel libibverbs-devel librdmacm-devel libattr-devel redhat-rpm-config \ rpm-build xfsprogs-devel zlib-devel ant gcc-c++ gcc \ redhat-lsb-core jav
-
问题内容: 为了下载文件,我正在创建一个urlopen对象(urllib2类)并分块读取它。 我想多次连接到服务器,并在六个不同的会话中下载文件。这样做,下载速度应该会更快。许多下载管理器都具有此功能。 我考虑过在每次会话中指定要下载的文件部分,并以某种方式在同一时间处理所有会话。我不确定如何实现这一目标。 问题答案: 听起来您想使用可用的HTTP Range 风格之一。 编辑 更新的链接以指向w
-
我实例化了一个Hadoop2.4.1集群,并且发现运行的MapReduce应用程序的并行化程度将不同,这取决于输入数据所在的文件系统类型。 使用HDFS,MapReduce作业将生成足够的容器,以最大限度地利用所有可用内存。例如,一个具有172GB内存的3节点集群,每个map任务分配2GB,将创建大约86个应用程序容器。 在不是HDFS的文件系统上(比如NFS或在我的用例中是并行文件系统),Map
-
问题内容: 我有一个大文件,需要阅读并制作字典。我希望尽快。但是我在python中的代码太慢了。这是显示问题的最小示例。 首先制作一些假数据 现在,这里是一个最小的python代码片段,可以读入它并制作一个字典。 时间: 但是,可以更快地读取整个文件,如下所示: 我的CPU有8个核心,是否可以在python中并行化此程序以加快速度? 一种可能是读取大块输入,然后在不同的非重叠子块上并行运行8个进程
-
文件系统是负责文件管理的操作系统的一部分。 它提供了一种机制来存储数据和访问文件内容,包括数据和程序。一些操作系统将所有内容视为Ubuntu文件。 文件系统处理以下问题 - 文件结构 - 前面已经了解可存储文件的各种数据结构。文件系统的任务是保持最佳的文件结构。 恢复可用空间 - 每当文件从硬盘中删除时,磁盘中都会创建一个可用空间。 可能有很多这样的空间需要被恢复,以便将它们重新分配给其他文件。
-
简单的文件读写是通过uv_fs_*函数族和与之相关的uv_fs_t结构体完成的。 note libuv 提供的文件操作和 socket operations 并不相同。套接字操作使用了操作系统本身提供了非阻塞操作,而文件操作内部使用了阻塞函数,但是 libuv 是在线程池中调用这些函数,并在应用程序需要交互时通知在事件循环中注册的监视器。 所有的文件操作函数都有两种形式 - 同步(synchron
-
文件系统提供弹性扩展的高性能文件存储服务,可为公有云上的虚拟机提供共享存储服务。 文件系统提供弹性扩展的高性能文件存储服务,可为公有云上的虚拟机提供共享存储服务。 目前已对接阿里云的NAS文件系统以及华为云的SFS弹性文件服务。 入口:在云管平台单击左上角导航菜单,在弹出的左侧菜单栏中单击 “存储/文件存储/文件系统” 菜单项,进入文件系统页面。 新建文件系统 该功能用于创建文件系统。 在文件系统