
FUFS 是一款基于linux c语言版fuse 开发的用户空间文件系统,实现了在linux 中对新浪微盘的基本操作。文件系统实现了对新浪微盘API的封装,当文件系统挂载到用户linux 的某个文件夹下,用户只需像普通文件一样操作自己微盘中的目录和文件。
FUFS的实现,通过fuse 来获取用户文件操作的指令,转而通过fufs自行分装的文件操作函数,来实现对新浪微盘里面的文件的操作。 通过libcurl 库,来实现http报文的发送和接受,通过glib库实现fufs 文件系统inode节点的建立,查询,删除,插入。通过json-c库,实现对新浪微盘服务器响应报文的解析。
FUFS实现的功能
1 挂载文件系统到linux 中某个文件

2 查询新浪微盘根目录文件
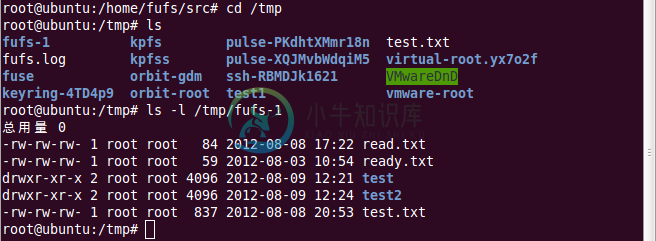
3 查询新浪微盘中某个文件
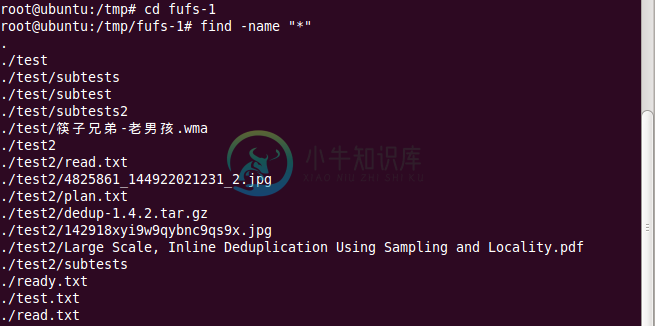
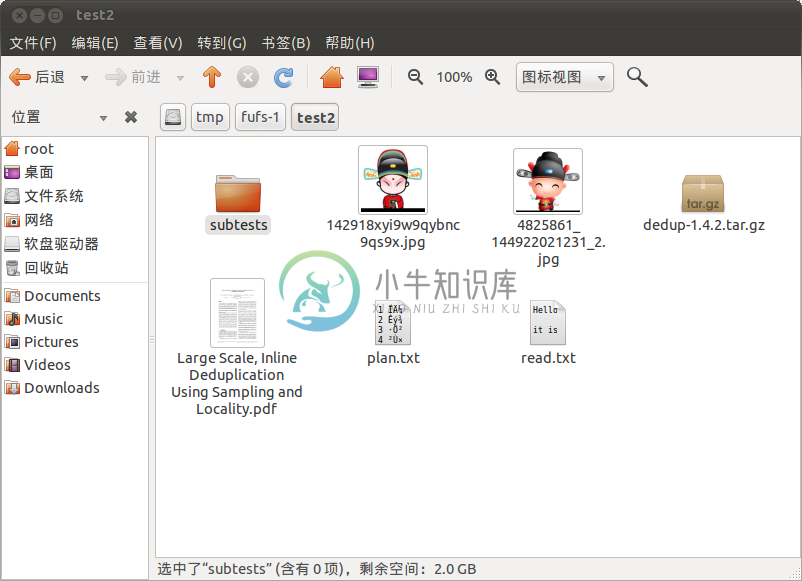
4 各种类型文件thumbnail的显示
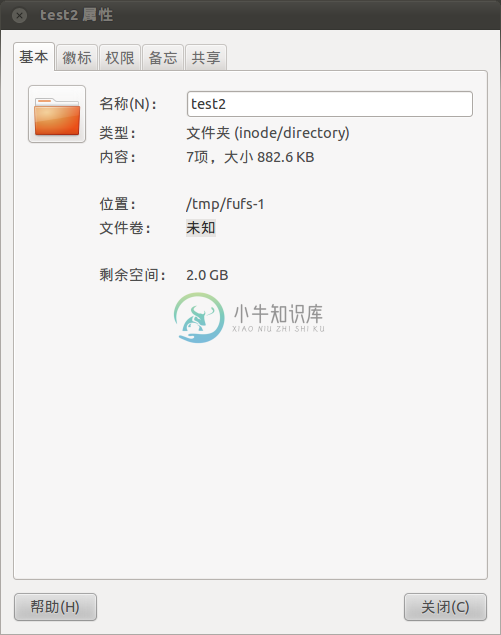
5 文件夹属性的获取
6 新浪微盘里的文件,linux环境读取
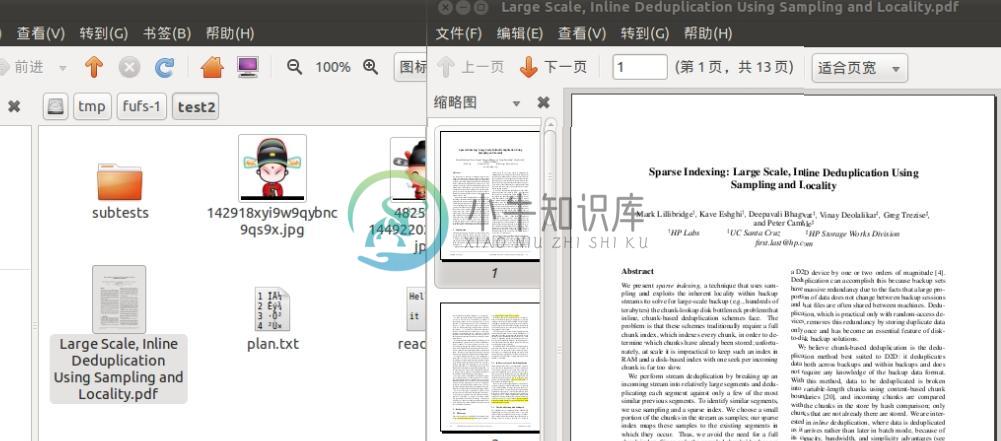
7 新浪微盘文件的读写
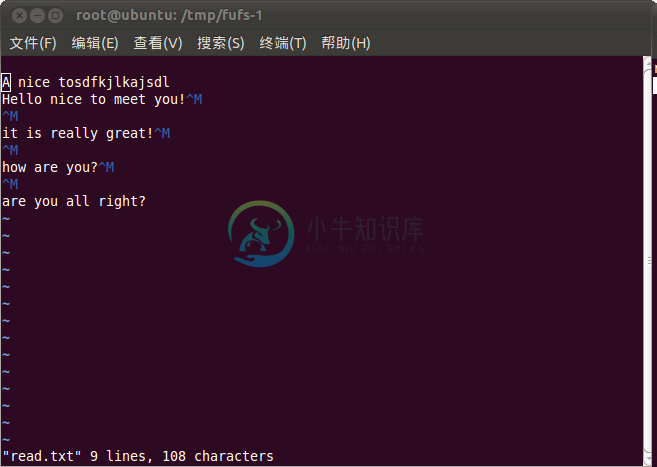
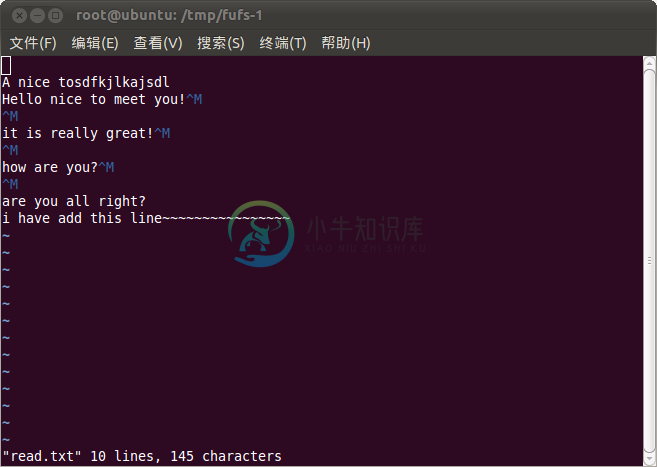
修改后文件
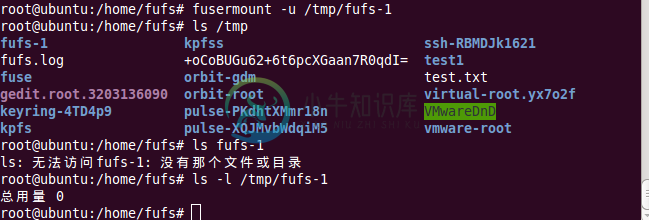
8 文件系统的卸载
注意:
由于新浪微盘API要求,对用户获取的token,必须在10-15分钟之间进行keep_token操作,因此在实现过程中,FUFS
先将获取的token保存在/tmp/token.log文件中,当fufs文件系统完成挂载后,需要运行src目录里面的token_keep_thread
小程序,它通过读取token.log里的token,在用户指定时间里面进行keep_token操作,保证token的有效性。
目前还没有完成的工作
1 文本文件汉字打开时出现乱码。(主要原因是缺少urlencode函数,对从新浪微盘读取数据的解码获取中文)
2 文件重命名,目录重命名 。即fuse里面的rename函数未完成。
感谢:非常感谢kpfs文件系统的作者Tao Yu ,给我实现新浪微盘文件系统FUFS带来了很多灵感和帮助.
如果有什么问题需要交流,或许你想帮助完善FUFS文件系统,你可以发我邮件。
我的邮箱地址:handsomestone@gmail.com
-
=================================================================== _____ _____ _____ | | | | | | | | / | | | | | | | | | | | _ | | | | | | | | _ | | | || | | | ___| | || _/ || |___ / fufs is a filesy
-
1 使用ubuntu 10.10 需要更新源 由于教育网 还是用中科大的吧 /etc/apt/sources.list (完全覆盖这个文件的内容) deb http://debian.ustc.edu.cn/ubuntu/ natty main multiverse restricted universe deb http://debian.ustc.edu.cn/ubuntu/
-
Ceph v0.55 及后续版本默认开启了 cephx 认证。从用户空间( FUSE )挂载一 Ceph 文件系统前,确保客户端主机有一份 Ceph 配置副本、和具备 Ceph 元数据服务器能力的密钥环。 在客户端主机上,把监视器主机上的 Ceph 配置文件拷贝到 /etc/ceph/ 目录下。 sudo mkdir -p /etc/ceph sudo scp {user}@{server-mac
-
在HDFS的上下文中,我们有Namenode和Datanode,说Namenode存储了文件系统名称空间是什么意思? 还有,我们为datanode指定的目录(在hdfs-core.xml中)是唯一可以存储数据的地方,还是我们可以指定任何其他目录来保存数据?
-
所有的用户空间事件都以process开头。你可以通过进程ID指定要检测的进程,也可以通过可执行文件名的路径名指定。SystemTap会查看系统的PATH环境变量,所以你既可以使用绝对路径,也可以使用在命令行中运行可执行文件时所用的名字。 由于SystemTap静态分析放置探针的位置时离不开调试信息,一些用户空间事件需要给定PID或可执行文件的路径(以下将两者统称为PATH)。不过大多数proces
-
问题内容: 我阅读了LKD 1中的一些段落,但 我无法理解以下内容: 从用户空间访问系统调用 通常,C库提供对系统调用的支持。用户应用程序可以从标准标头中提取函数原型,并与C库链接以使用您的系统调用(或库例程,后者又使用syscall调用)。但是,如果您只是编写了系统调用,则怀疑glibc是否已支持它! 幸运的是,Linux提供了一组宏,用于包装对系统调用的访问。它设置寄存器内容并发出陷阱指令。这
-
问题内容: 一般情况是,我们有一个服务器集群,并且我们想使用Docker在服务器集群之上建立虚拟集群。 为此,我们为不同的服务(Hadoop,Spark等)创建了Dockerfile。 但是,关于Hadoop HDFS服务,我们面临这样一种情况,即Docker容器可用的磁盘空间等于服务器可用的磁盘空间。我们希望限制每个容器的可用磁盘空间,以便我们可以动态生成具有一定存储大小的附加数据节点,以构成H
-
问题内容: 我在Linux上使用Python 2.6。最快的方法是什么: 确定哪个分区包含给定的目录或文件? 例如,假设已安装在和上。我想从琴弦中取出那副。 然后,获取给定分区的使用情况统计信息?例如,给定我想要获得分区的大小和可用的可用空间(以字节为单位或大约以兆字节为单位)。 问题答案: 如果您只需要设备上的可用空间,请参阅下面的使用答案。 如果您还需要与文件关联的设备名称和安装点,则应调用外