
QuickLZ 是一个号称世界压缩速度最快的压缩库,并且也是个开源的压缩库,其遵守 GPL 1, 2 或 3协议。
在QuickLZ的官网上有个关于QuickLZ的测试:
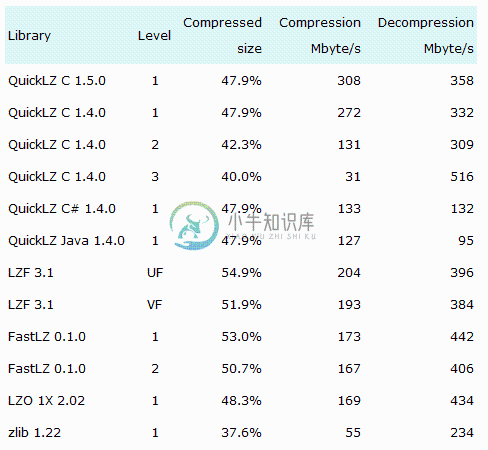
QuickLZ有个前端程序叫qpress,可以在QuickLZ的官网上下载下来进行测试。
-
QuickLZ 是一个号称世界压缩速度最快的压缩库,并且也是个开源的压缩库,其遵守 GPL 1, 2 或 3协议。 在QuickLZ的官网上有个关于QuickLZ的测试: Library Level Compressed size Compression Mbyte/s Decompression Mbyte/s QuickLZ C 1.5.0 1 47.9% 308 358 Qu
-
[TOC] 简述 有一个需求是这样的,写的一个程序内置了一个很大的文件(实际就是抓取epsg.io的内容里面的epsg.io.json),这个文件筛选缩减后还有12MB,如果直接内置到程序中,编译后的程序就很大了。 因为这个程序是一个动态库,而使用upx压缩过的动态库有时候会有一些异常问题出现,所以不考虑使用upx进行压缩。 看到了quicklz后,感觉这是个好东西,于是就用这个来进行压缩,把压缩
-
QuickLZ 是一个号称世界压缩速度最快的压缩库,并且也是个开源的压缩库,其遵守GPL 1, 2 或 3协议。 在QuickLZ的官网上有个关于QuickLZ的测试: Library Level Compressed size Compression Mbyte/s Decompression Mbyte/s QuickLZ C 1.5.0 1 47.9% 308 358 QuickLZ C 1
-
以前对压缩算法一无所知,只是知道哈弗曼编码能做这种事情,但是感觉这样的方法奇慢无比。昨天下午看了下号称世界上最快的压缩算法Quicklz,对压缩的基本思路有了一定的了解。一般的压缩程序的要求读入文件之后以便压缩一边输出,而不是去先分析整个文件中的情况之后才做决定采取哪种算法。 Quicklz也不例外也是争取利用文件中重复出现的字节来进行压缩,管理结构如下: 在压缩的过程中不断地读入3个字节,然后根
-
翻译自quicklz c手册 /// 压缩函数: size_t qlz_compress( const void *source, char *destination, size_t size, qlz_state_compress *state_compress) source,源字符地址 destination,压缩后的数据存储起始地址,其大小至少为size+400字节 size,需要压
-
1、ZIP、 GZIP 计算机文件压缩算法,JDK中java.util.zip.*中实现。主要包括ZipInputStream/ ZipOutputStream、GZipInputStream/ ZipOutputStream。 2、QuickLZ是一个号称世界压缩速度最快的压缩库,并且也是个开源的压缩库,其遵守 GPL 1, 2 或 3协议。 3、Snappy是一个 C++的用来压缩和解压缩的
-
quicklz源码 // Fast data compression library // Copyright (C) 2006-2011 Lasse Mikkel Reinhold // lar@quicklz.com // // QuickLZ can be used for free under the GPL 1, 2 or 3 license (where anything // re
-
之前对quicklz算法有一定了解,知道其对单个消息包压缩比几乎没有甚至为负值(之前未测试,只是理论猜测), 故采用聚集压缩(N个消息的字节流的某一部分压缩),这样可有效减少压缩函数的调用次数,减少开销。 今天给as3搞了个客户端网络库,调试的时候验证了以前的猜测(其对单个消息包压缩比几乎没有甚至为负值),样本数据很简单,几乎无重复的字符串,大概1K多,少了几十字节。 若一个服
-
根据Princeton booksite,带有路径压缩的加权快速联合将10^9联合对10^9对象的操作时间从一年减少到大约6秒。这个数字是怎么得出的?当我在10^8操作中运行下面的代码时,我的运行时间是61s。
-
本文向大家介绍JNI方法实现图片压缩(压缩率极高),包括了JNI方法实现图片压缩(压缩率极高)的使用技巧和注意事项,需要的朋友参考一下 前言 直接使用项目或直接复制libs中的so库到项目中即可(当前只构建了armeabi),需要其他ABI可检下项目另外使用CMake构建即可。 结果预览: 效果图.png jni_278KB.png quality_484KB.png sample_199KB
-
有一种“带路径压缩的加权快速联合”算法。 代码: 问题: > 路径压缩是如何工作的意味着我们只到达节点的第二个祖先,而不是根。 包含从 到 整数。如何帮助我们知道集合中元素的数量? 有人能帮我澄清一下吗?
-
我正在为联合/查找结构实现快速联合算法。在“Java中的算法”一书网站上给出的实现中,普林斯顿实现在实现路径压缩(在方法中)时无法保持树的大小不变。这不应该对算法产生不利影响吗?还是我错过了什么?另外,如果我是对的,我们将如何修改大小数组?
-
斐波那契的这种实现很容易理解,但速度很慢: 斐波那契的实现很难理解,但速度非常快。它在我的笔记本电脑上立即计算出第100,000个斐波那契数。 关于后一种实现,这里发生了什么魔力,它是如何工作的?
-
我正在学习联合/查找结构的“加权快速联合与路径压缩”算法。普林斯顿edu网站详细解释了该算法。这是Java的实现: 但就像网站提到它的性能一样: 定理:从空数据结构开始,任何 M 并集序列和对 N 个对象的查找操作都需要 O(N M lg* N) 时间。 证明非常困难。 但是算法仍然很简单! 但我仍然很好奇迭代对数lg*n是如何产生的。它是如何推导出来的?有人可以证明它或只是以直观的方式解释它吗?