
logkit是七牛Pandora开发的一个通用的日志收集工具,可以将不同数据源的数据方便的发送到Pandora进行数据分析,除了基本的数据发送功能,logkit还有容错、并发、监控、删除等功能。
logkit详细的文档可以参见WIKI页面。
优势
- GO 语言编写,性能优良,资源消耗低,跨平台支持。
- Web 支持,提供 页面 对数据收集、解析、发送过程可视化
- 插件式架构,扩展性强,使用灵活,易于复用。
- 定制化能力强,可以仅使用部分 logkit 包,以此定制专属收集工具。
- 配置简单,易于上手,可通过 页面 进行操作管理。
- 原生中文支持,没有汉化烦恼。
- 功能全面,涵盖了包括 grok 解析、metric 收集、字段变化 (transform) 在内的多种开源软件特点。
- 生态全面,数据发送到七牛的 Pandora 大数据平台支持包括时序数据库、日志检索以及压缩永久存储等多种数据落地方案。
- 数据收集安全稳定,拥有磁盘队列、内存队列、错误重试、压缩传输、限速限流等多种机制,数据发送不重不漏。
- 集群化,可以通过一个logkit 作为master 在 web 管理众多logkit,对整体集群进行管理。
支持的数据源
- File:读取文件中的日志数据,包括csv格式的文件,kafka-rest日志文件,nginx日志文件等,并支持以grok的方式解析日志。
- Elasticsearch:读取ElasticSearch中的数据。
- MongoDB:读取MongoDB中的数据。
- MySQL:读取MySQL中的数据。
- MicroSoft SQL Server:读取Microsoft SQL Server中的数据。
- Postgre SQL:读取 PostgreSQL 中的数据。
- Kafka:读取Kafka中的数据。
- Redis:读取Redis中的数据。
- Socket:读取tcp\udp\unixsocket协议中的数据。
- Http:作为 http 服务端,接受 POST 请求发送过来的数据。
- Script:支持执行脚本,并获得执行结果中的数据。
- Snmp:主动抓取 Snmp 服务中的数据。
工作方式
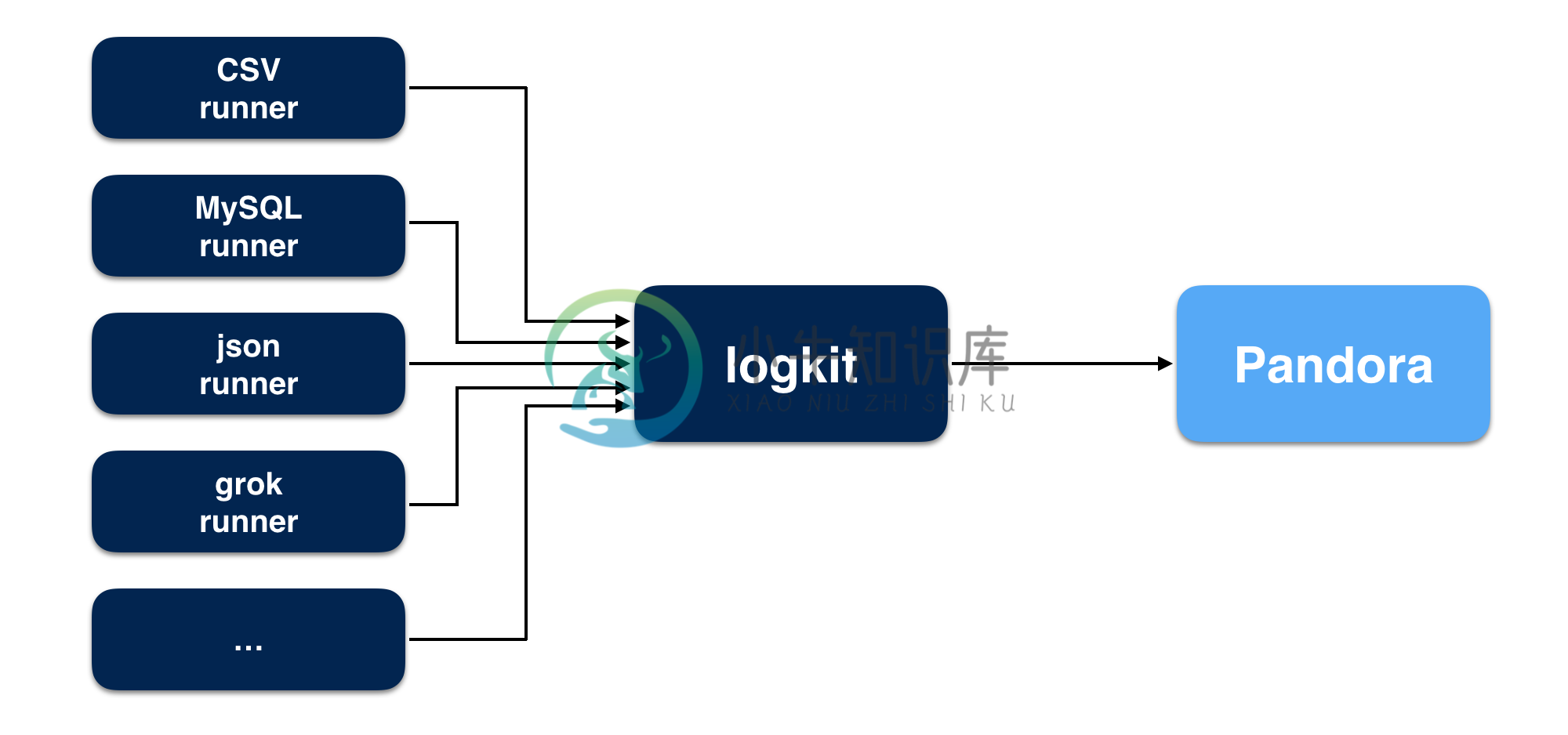
logkit本身支持多种数据源,并且可以同时发送多个数据源的数据到Pandora,每个数据源对应一个逻辑上的runner,一个runner负责一个数据源的数据推送,工作原理如下图所示
-
qti logkit 当前,用于标记XML中的评估,测试和单个问题的最广泛使用的标准是IMS问题与测试互操作性(QTI)。 IMS是与电子学习标准相关的组织(请参阅参考资料中的链接),其标准范围从元数据到传输学习者信息。 QTI标准化了如何在XML中标记问题,将其安排到测试和评估中,添加元数据以及将所有内容打包在ZIP文件中的方法。 常用缩略语 URI:统一资源标识符 XHTML:可扩展超文本标记
-
1. 概述 不论什么一个系统中,日志都是必不可少的。如今Apache提供了两套日志工具,一个就是Log4j。还有一个是本文要给出样例的LogKit。 Log4j和LogKit有非常多类似的地方。比方,Log4j提供5级日志:DEBUG、INFO、WARN、ERROR和FATAL。LogKit也提供5级日志:DEBUG、INFO、WARN、ERROR和FATAL-ERROR。除了级别5的命
-
jmeter 5+版本没有logkit-2.0.jar,所以在配置环境变量的时候可以忽略不用设置,网上很多版本的帖子都是贴来贴去的,没有一个明确的说明,在此记录一下!
-
找到解压后的jmeter的lib包下的log4j-core.jar包,用这个包配置环境变量.然后启动jmeter.bat的时候用管理员的身份启动.
-
1. 概述 不论什么一个系统中,日志都是必不可少的。如今Apache提供了两套日志工具,一个就是Log4j。还有一个是本文要给出样例的LogKit。 Log4j和LogKit有非常多类似的地方。比方,Log4j提供5级日志:DEBUG、INFO、WARN、ERROR和FATAL。LogKit也提供5级日志:DEBUG、INFO、WARN、ERROR和FATAL-ERROR。除了级别5的命
-
目的:Logkit+influxdb+grafana 环境对被测试程序进程流量的监控 系统环境: 被测试环境 windows 2008 / 2012 监控系统: ubuntu 18.04 在被测试系统安装 Logkit,通过图形界面进行配置。 安装influxdb 在监控主机上,开启admin 管理,配置访问ip与端口。 暂时遇到问题,logkit显示已将数据发送到influxdb数据库,在inf
-
系统与程序的运行日志对排查问题以及实现一些自动化操作可能非常有用。本文将简要说明收集 TiDB 及相关组件日志的方法。 TiDB 与 Kubernetes 组件运行日志 通过 TiDB Operator 部署的 TiDB 各组件默认将日志输出在容器的 stdout 和 stderr 中。对于 Kubernetes 而言,这些日志会被存放在宿主机的 /var/log/containers 目录下,并
-
前言 在进行日志收集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发现,Logstash是基于JDK的,在没有产生日志的情况单纯启动Logstash就大概要消耗500M内存,在每个Pod中都启动一个日志收集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用Filebeat替代,经测试单独启动Filebeat容器大约会消
-
我有一个关于2.9版本的log4j2的问题。基本上,我想做的与这里描述的相同(log4j),只有2.9:示例log4j v1. x 我需要一个可以在类中的任何方法中调用的记录器。这是从某个起点递归地收集所有后续日志。该集合应该能够在以后以任何形式读出。 在表单中设置结束后,集合中应包括以下日志: 开始 谢谢你的帮助
-
前面的课程中和大家一起学习了 Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集。 介绍 应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的。而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中。对于容器化应用程序来说则更简单,只需要将日志信息写入到 s
-
本章展示如何配置Istio来自动收集mesh中服务的遥测数据。 在本章末尾,将为mesh中的服务调用启用新的metric和新的日志流。 BookInfo应用将作为介绍本章内容的示例应用。 开始之前 在集群中安装Istio并部署一个应用程序。 本章假设Mixer使用默认配置(--configDefaultNamespace=istio-system)。 如果使用不同的值,则更新这个任务中的配置和命令
-
我是Hadoop的新手,正在学习apache Flume。我在Virtualbox上安装了CDH 4.7。以下命令将输出顶部 cputime。如何使用 Apache flume 将以下命令的日志数据输出传输到我的 HDFS?如何创建水槽配置文件?