

Plumelog 一个简单易用的java分布式日志组件,码云GVP(最有价值开源项目)
一.系统介绍
-
无入侵的分布式日志系统,基于log4j、log4j2、logback搜集日志,设置链路ID,方便查询关联日志
-
基于elasticsearch作为查询引擎,单机版基于lucene
-
高吞吐,查询效率高,多种集群部署方案,满足各种体量项目需求
-
全程不占应用程序本地磁盘空间,免维护
-
无需修改老项目,引入直接使用
-
支持错误统计,错误报警到企业,钉钉,飞书等
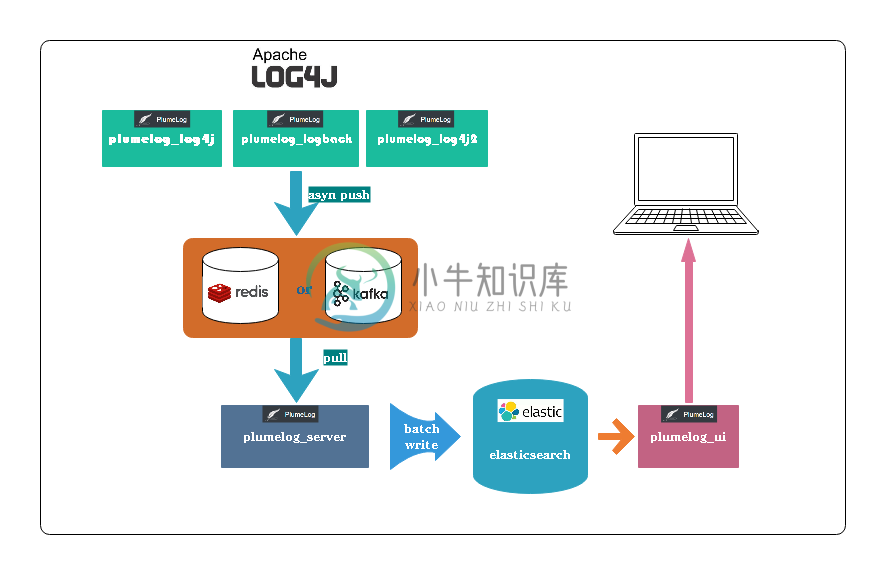
二.架构
-
plumelog-core 核心组件包含日志搜集端,负责搜集日志并推送到kafka,redis等队列
-
plumelog-server 负责把队列中的日志日志异步写入到elasticsearch
-
plumelog-demo 基于springboot的使用案例
-
plumelog-lite plumelog的嵌入式集成版本,免部署
三.UI界面
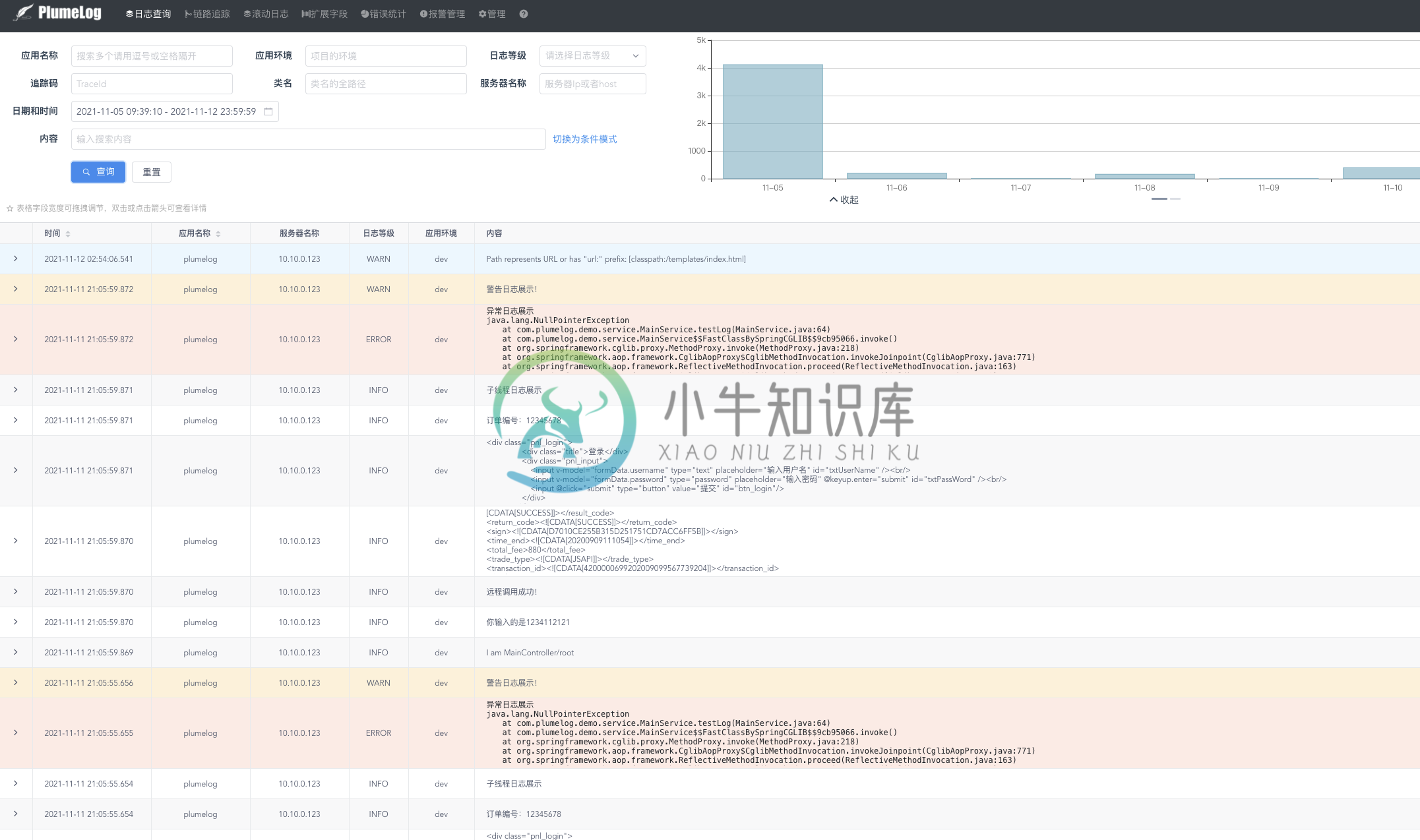
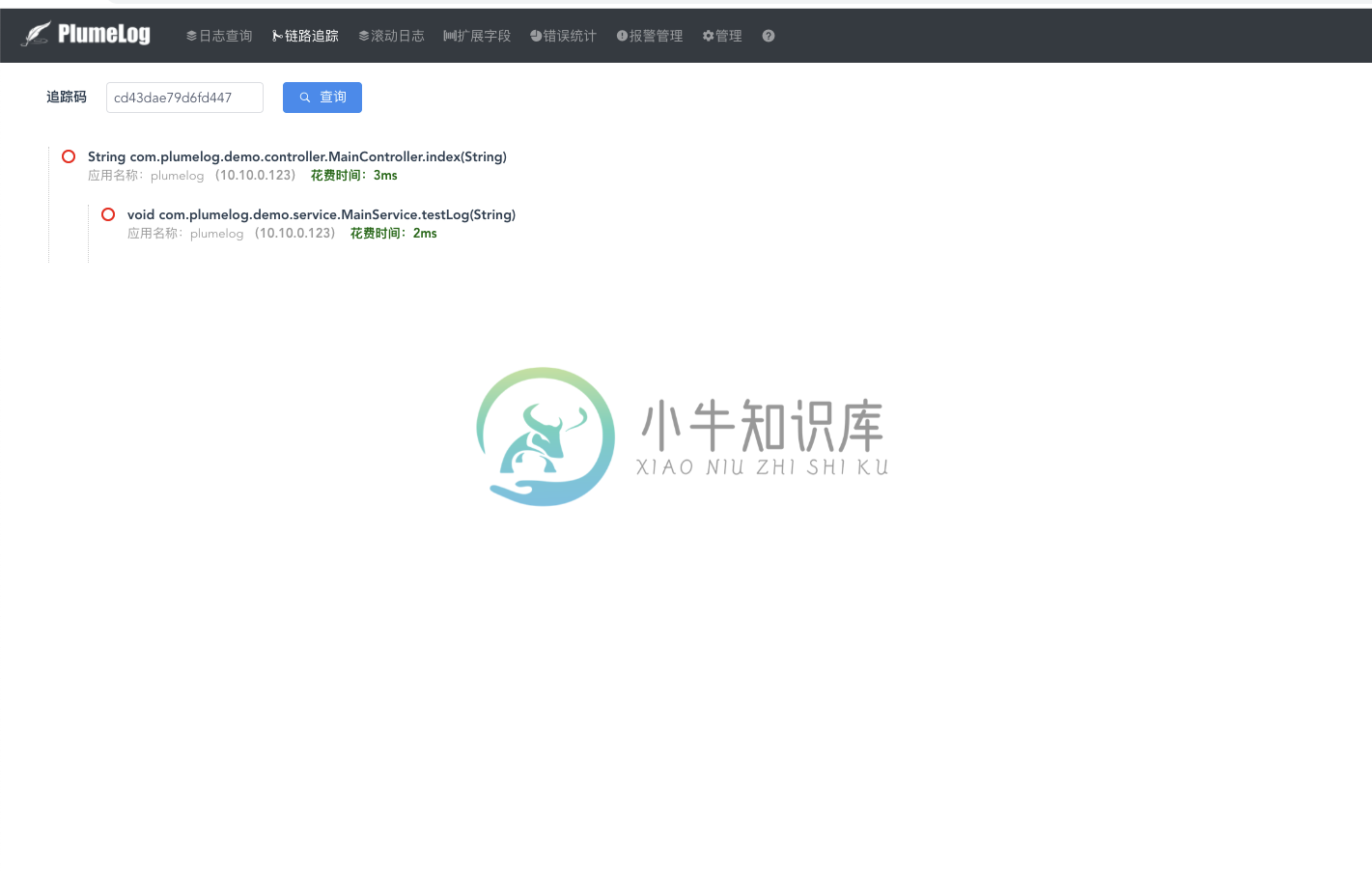
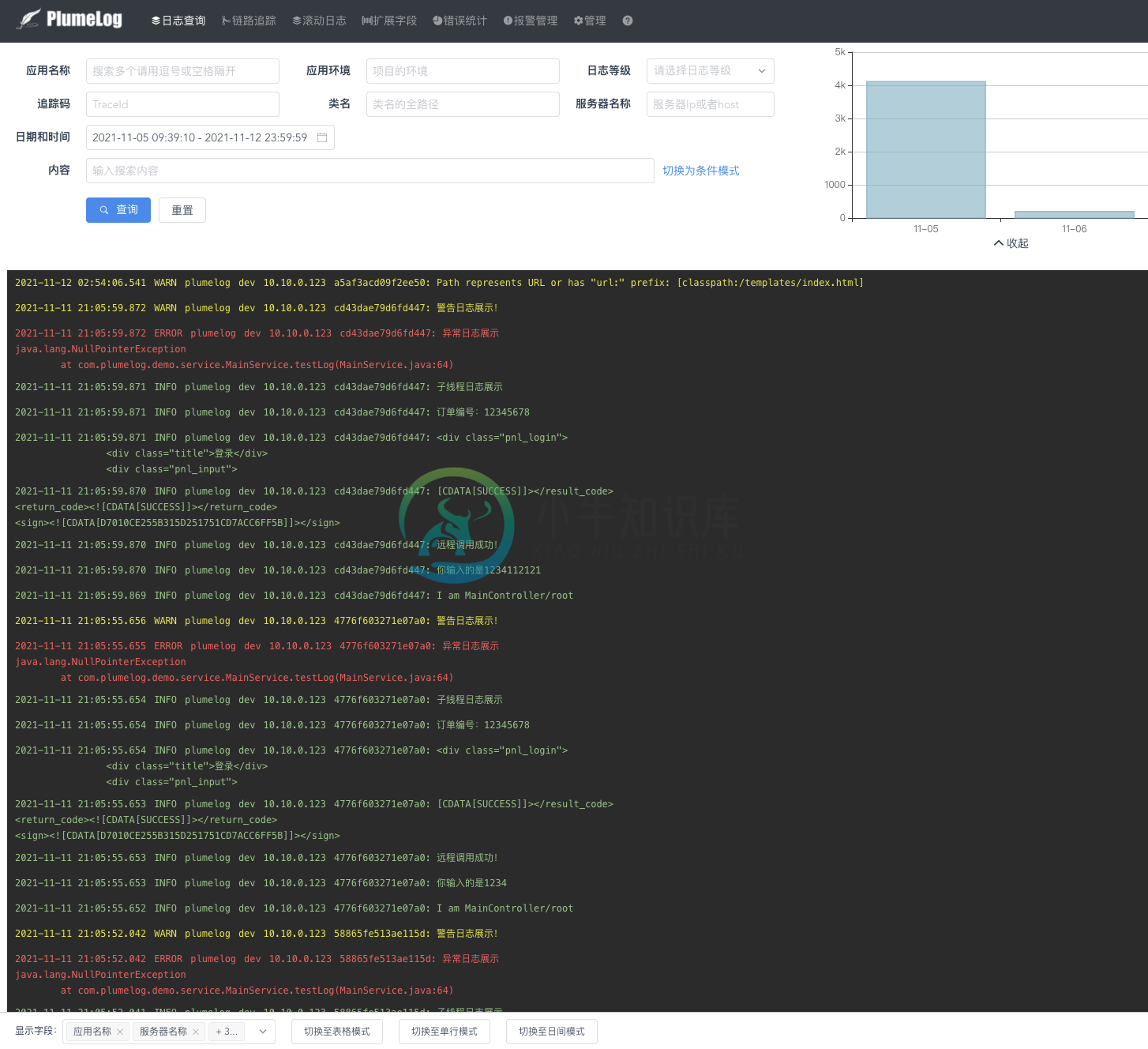

功能演示视频地址 https://v.qq.com/x/page/g3308uxlcnw.html
-
1. 概述 公司使用分布式项目,每天日志量太大,需要用到轻量级的分布式日志系统 PlumeLog。 但是发现该框架有个问题: ES查询结果有最大10000条的限制。(一天生成一个key,几个单体服务的日志都放在ES的同一个key中,所以一天的日志量远远超过了10000条) 2. 解决方案 思路: ES设置key值的时候,在setting中添加配置:max_result_windo
-
我正在分布式模式下运行 Kafka 连接(在 3 节点群集上)。 VM1 中的一个连接器生成的日志是否与 VM2 和 VM3 相同? 在3个虚拟机上运行的连接器是S3接收器连接器,它们运行在同一个端口8080上,属于同一个组。
-
本章介绍如何使用Zipkin或Jaeger收集启用了Istio的应用程序的调用链信息。 完成本章后,你可以理解有关应用程序的所有假设以及如何使其参与跟踪,无论您使用何种语言/框架/平台构建应用程序。 BookInfo示例用来作为此任务的示例应用程序。 环境准备 参照安装指南的说明安装Istio。 如果您在安装过程中未启动Zipkin或Jaeger插件,则可以运行以下命令启动: 启动Zipkin:
-
任何我们可以实现的解决方案或模式?
-
zebra-client和zebra-cat-client的版本保持同步,不会单独发布版本。 zebra-dao版本单库维护。 推荐版本 zebra-client : 2.9.1 zebra-cat-client : 2.9.1 zebra-dao : 0.2.1 最新版本 zebra-client : 2.9.1 zebra-cat-client : 2.9.1 zebra-dao : 0.2.
-
日志组件接口 宏定义 #define LOG_E(...) ulog_e(LOG_TAG, __VA_ARGS__) 错误级别日志 #define LOG_W(...) ulog_w(LOG_TAG, __VA_ARGS__) 警告级别日志 #define LOG_I(...) ulog_i(LOG_TAG, __VA_ARGS__) 提示级别日志 #de
-
apache kafka文档提到以下内容: 如果所有使用者实例具有相同的使用者组,那么记录将有效地在使用者实例上进行负载平衡。 如果所有的使用者实例都有不同的使用者组,那么每个记录都将广播给所有的使用者进程。