
Crunch 是一个用 Go 语言开发的基于 Hadoop 的 ETL 和特性抽取工具,特点是速度快。
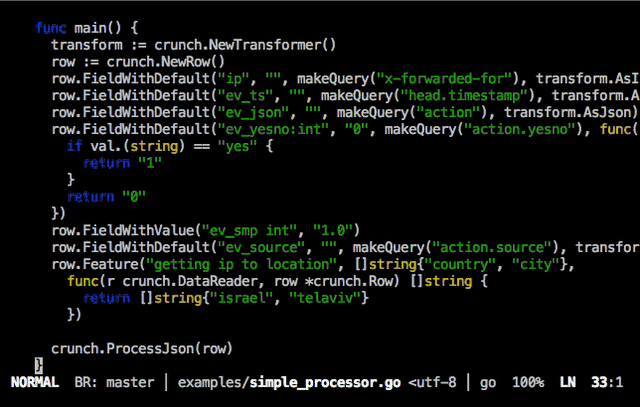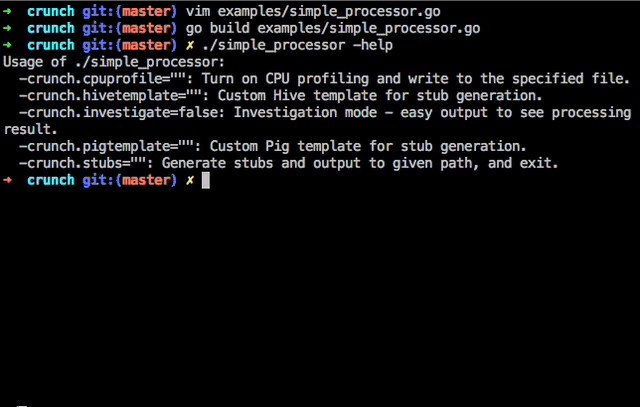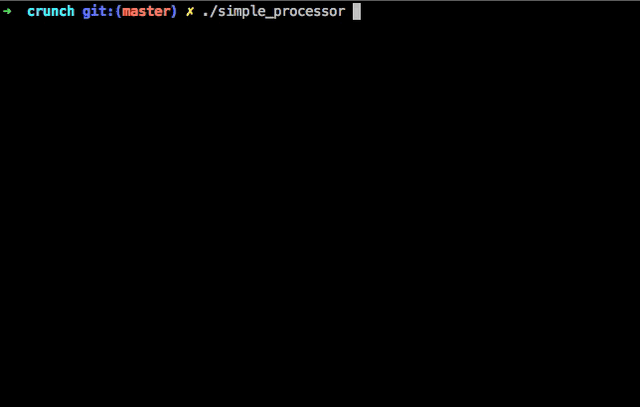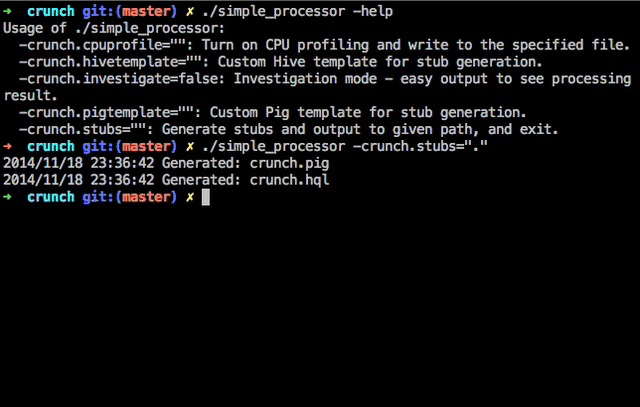
-
目录 Crunch命令格式 Crunch常用选项参数 Crunch使用实例 Crunch命令格式 crunch <min-len> <max-len> [<charset string>] [<options>] 命令参数说明: min-len (必选):字符串的最小长度 max-len (必选):字符串的最大长度 charset string (可
-
1、crunch命令格式 crunch <min-len> <max-len> [<charset string>] [options] 参数: min-len crunch要开始的最小长度字符串。即使不使用参数的值,也需要此选项 max-len crunch要开始的最大长度字符串。即使不使用参数的值,也需要此选项 charset string 在命令行使用crunch你可能必须指定字符集设置
-
示例1: crunch 2 4 #生成最小2位,最大4位,不选字符集默认是26个小写字母 示例2: crunch 1 2 ab #生成最小为1,最大为2 由a b为元素的所有组合 示例3: crunch 1 6 abc\ #生成最小为1,最大为6.由abc和空格为元素的所有组合(\代表空格) 示例4: crunch 3 3 –f /usr/share/crunch/charset.lst mixa
-
1、crunch命令格式 crunch [] [options] 参数: min-len crunch要开始的最小长度字符串。即使不使用参数的值,也需要此选项 max-len crunch要开始的最大长度字符串。即使不使用参数的值,也需要此选项 charset string 在命令行使用crunch你可能必须指定字符集设置,否则将使用缺省的字符集设置。缺省的设置为小写字符集,大写字符集,数字和
-
-b: 指定输出文件的大小kb,mb,gb,kib,mib,gib(前3个是1000,后3个是1024,数字与格式间没有空格) -c: n 指定输出的行数 -p: 指定几个字符进行排序组合 -d: 限制重复字符的数量,例如:-d 3@ 表示最多有连续3个的小写字母相同 -e: 表示生成到该字符停止 -s: 表示从该字符开始生成 -l: 与-t 连用;将@,^%这几个字符实体化,仅代表它们是符号,没
-
目录 1.密码安全 2.漏洞利用 3.不安全的密码 4.密码猜解思路 5. 字典wordlist 5.1 kali字典
-
1 介绍 词频-逆文档频率法(Term frequency-inverse document frequency,TF-IDF)是在文本挖掘中广泛使用的特征向量化方法。 它反映语料中词对文档的重要程度。假设用t表示词,d表示文档,D表示语料。词频TF(t,d)表示词t在文档d中出现的次数。文档频率DF(t,D)表示语料中出现词t的文档的个数。 如果我们仅仅用词频去衡量重要程度,这很容易过分强调
-
VectorSlicer是一个转换器,输入一个特征向量输出一个特征向量,它是原特征的一个子集。这在从向量列中抽取特征非常有用。 VectorSlicer接收一个拥有特定索引的特征列,它的输出是一个新的特征列,它的值通过输入的索引来选择。有两种类型的索引: 1、整数索引表示进入向量的索引,调用setIndices() 2、字符串索引表示进入向量的特征列的名称,调用setNames()。这种情况需
-
规则化器缩放单个样本让其拥有单位$L^{p}$范数。这是文本分类和聚类常用的操作。例如,两个$L^{2}$规则化的TFIDF向量的点乘就是两个向量的cosine相似度。 Normalizer实现VectorTransformer,将一个向量规则化为转换的向量,或者将一个RDD规则化为另一个RDD。下面是一个规则化的例子。 import org.apache.spark.SparkConte
-
CountVectorizer和CountVectorizerModel的目的是帮助我们将文本文档集转换为词频(token counts)向量。 当事先没有可用的词典时,CountVectorizer可以被当做一个Estimator去抽取词汇,并且生成CountVectorizerModel。 这个模型通过词汇集为文档生成一个稀疏的表示,这个表示可以作为其它算法的输入,比如LDA。 在训练
-
Word2Vector将词转换成分布式向量。分布式表示的主要优势是相似的词在向量空间距离较近,这使我们更容易泛化新的模式并且使模型估计更加健壮。 分布式的向量表示在许多自然语言处理应用(如命名实体识别、消歧、词法分析、机器翻译)中非常有用。 1 模型 在MLlib中,Word2Vector使用skip-gram模型来实现。skip-gram的训练目标是学习词向量表示,这个表示可以很好的预测
-
问题 在解析获得一个Document实例对象,并查找到一些元素之后,你希望取得在这些元素中的数据。 方法 要取得一个属性的值,可以使用Node.attr(String key) 方法 对于一个元素中的文本,可以使用Element.text()方法 对于要取得元素或属性中的HTML内容,可以使用Element.html(), 或Node.outerHtml()方法 示例: String html =
-
问题内容: 我想要一些属性,可以在Spring bean中通过@Value引用,只能依赖于其他属性来创建。特别是我有一个属性,它描述目录的文件系统位置。 按照约定,该目录中有一个文件,始终称为 myfile.txt 。 现在,我想通过我的bean内的@Value注释访问目录和文件。有时我想以String形式访问它们,有时以java.io.Files形式访问它们,有时以org.springframe
-
我试图在我的应用程序中读取一些蓝牙特性。现在我有一个问题,在我的Gatt服务器特性改变后该怎么办。起初,我试图使用一个线程来重新触发读取特性,一次又一次,就像这样: 但问题是,数据似乎在某一点上被破坏(就像我总是从我的MCU端将相同的数据写入特征)。 允许读取像这样的可读取数据吗?有没有什么建议的方法可以一直读取可读取的数据?还是在我的应用程序端更新? 如果你需要任何额外的代码,请告诉我。