
toyDB 是用 Rust 编写的分布式 SQL 数据库,作为一个学习项目。大多数组件都是从头开始构建的,包括:
-
用于线性化状态机复制的基于 Raft 的分布式共识引擎。
-
具有基于 MVCC 的快照隔离的符合 ACID 的事务引擎。
-
具有 B+树和日志结构后端的可插拔存储引擎。
-
具有启发式优化和时间旅行支持的基于迭代器的查询引擎。
-
SQL 接口包括投影、过滤器、连接、聚合和事务。
toyDB 不适合在现实世界中使用,但其他学习数据库内部结构的人可能会感兴趣。
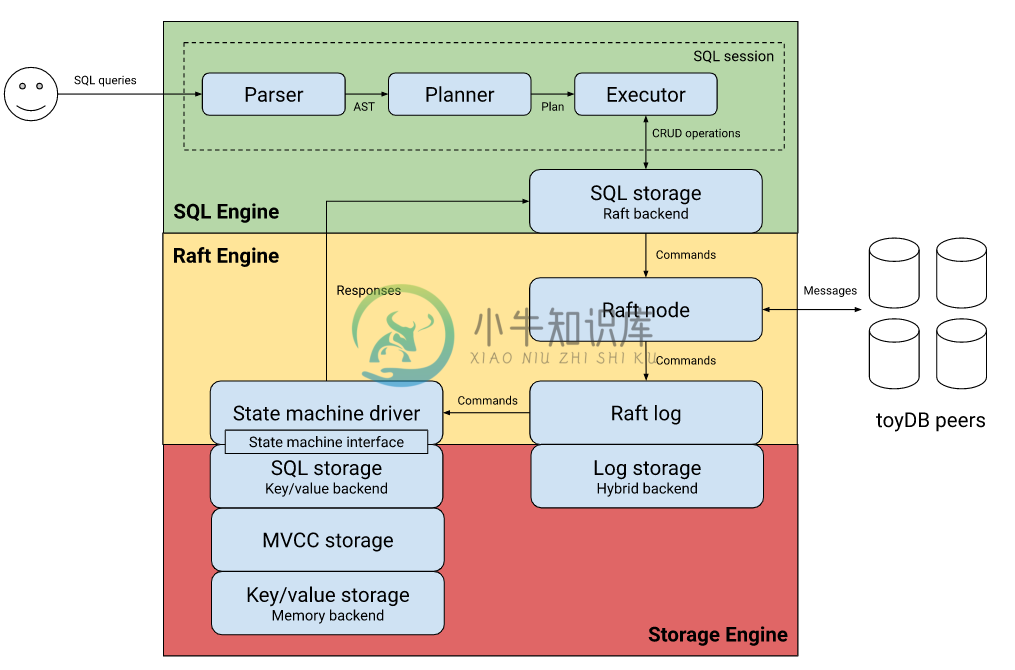
toyDB 的架构对于分布式 SQL 数据库来说是相当典型的:一个由 Raft 集群管理的事务键/值存储,上面有一个 SQL 查询引擎。有关更多详细信息,可参阅 架构指南。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
译者:firdameng 作者:Soumith Chintala 在这个简短的教程中,我们将讨论PyTorch的分布式软件包。 我们将看到如何设置分布式设置,使用不同的通信策略,并查看包的内部部分。 开始 PyTorch中包含的分布式软件包(即torch.distributed)使研究人员和从业人员能够轻松地跨进程和计算机集群并行化他们的计算。 为此,它利用消息传递语义,允许每个进程将数据传递给任
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
分布式程序是那些旨在在计算机网络上运行并且只能通过消息传递协调其活动的程序。 我们可能想要编写分布式应用程序的原因有很多。 这里是其中的一些。 Performance - 我们可以通过安排程序的不同部分在不同的机器上并行运行来使程序更快。 Reliability - 我们可以通过将系统结构化以在多台机器上运行来制造容错系统。 如果一台机器出现故障,我们可以继续使用另一台机器 Scalability
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
本章描述如何编写运行于Erlang节点网络上的分布式Erlang程序。我们描述了用于实现分布式系统的语言原语。Erlang进程可以自然地映射到分布式系统之中;同时,之前章节所介绍的Erlang并发原语和错误检测原语在分布式系统和单节点系统中仍保持原有属性。 动机 我们有很多理由去编写分布式应用,比如: 速度 我们可以把我们的程序切分成能够分别运行于多个不同节点的几个部分。比如,某个编译器可以将一个