
编写嵌套的SQL查询

我有3个表作为学生数据,包括学生的数据,科目表的数据提供的所有科目和分数,学生获得的每一个科目的分数。通过StudentId标记到StudentData表的表映射,通过SubjectId标记到Subjects表的表映射
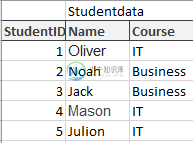
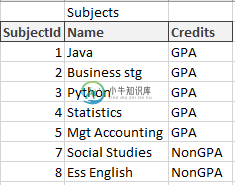
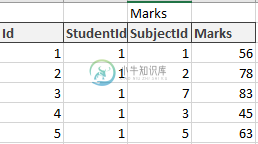
我想做的是选择每个科目的最高分数和学生的名字,如下所示

所以我写了一个甲骨文PL / SQL查询如下,
select MAX(marks)
from
(select Marks ,subjects.name as SJN ,studentdata.name
from (studentdata inner Join marks On studentdata.studentid = marks.studentid)
Inner Join subjects On subjects.subjectid = marks.subjectid)
where SJN in (select name from subjects);
但它只给出了一个结果。请帮助我开发一个查询来获取我的预期结果集。
共有3个答案

首先想到的是:选择每个科目的最佳分数,然后选择该科目中具有该分数的学生:
select s.name as subject, m.marks, sd.name as studentname
from marks m
join studentdata sd on sd.studentid = m.studentid
join subjects s on s.subjectid = m.subjectid
where (m.subjectid, m.marks) in
(
select subjectid, max(marks)
from marks
group by subjetid
);
如您所见,我们从标记中选择两次。这可以通过窗口函数来避免:
select s.name as subject, m.marks, sd.name as studentname
from
(
select
subjectid,
marks,
max(marks) over (partition by subjectid) as max_marks
from marks
) m
join studentdata sd on sd.studentid = m.studentid
join subjects s on s.subjectid = m.subjectid
where m.marks = m.max_marks;
另一个选择是加入并检查主题是否没有更好的标记:
select s.name as subject, m.marks, sd.name as studentname
from marks m
join studentdata sd on sd.studentid = m.studentid
join subjects s on s.subjectid = m.subjectid
where not exists
(
select null
from marks m2
where m2.subjectid = m.subjectid
and m2.marks > m.marks
);
这些选项中哪一个是最好的,我不知道。选择您认为最易读的那个。无论您选择哪种查询,此索引都应有助于 DBMS 快速找到最高分:
create index idx on marks(subjectid, marks);

您可以按如下方式使用分析函数ROW_NUMBER:
SELECT SJN, MARKS, STUNAME FROM
(SELECT
MARKS.MARKS,
SUBJECTS.NAME AS SJN,
STUDENTDATA.NAME AS STUNAME,
ROW_NUMBER() OVER (PARTITION BY SUBJECTS.SUBJECTID
ORDER BY MARKS.MARKS DESC NULLS LAST) AS RN
FROM
STUDENTDATA
INNER JOIN MARKS ON STUDENTDATA.STUDENTID = MARKS.STUDENTID
INNER JOIN SUBJECTS ON SUBJECTS.SUBJECTID = MARKS.SUBJECTID)
WHERE RN = 1;

类似这样的?第1 - 26行代表样本数据(不需要输入);您需要的查询从第28行开始。
SQL> with
2 -- sample data
3 studentdata (studentid, name, course) as
4 (select 1, 'olivier', 'it' from dual union all
5 select 2, 'noah', 'business' from dual union all
6 select 3, 'jack', 'business' from dual union all
7 select 4, 'mason', 'it' from dual union all
8 select 5, 'julion', 'it' from dual),
9 subjects (subjectid, name) as
10 (select 1, 'java' from dual union all
11 select 2, 'business stg' from dual union all
12 select 3, 'python' from dual union all
13 select 4, 'statistics' from dual union all
14 select 5, 'mgt accounting' from dual union all
15 select 7, 'social studies' from dual union all
16 select 8, 'ess english' from dual),
17 marks (id, studentid, subjectid, marks) as
18 (select 1, 1, 1, 56 from dual union all
19 select 2, 1, 2, 78 from dual union all
20 select 3, 1, 7, 83 from dual union all
21 select 4, 1, 3, 45 from dual union all
22 select 5, 1, 5, 63 from dual union all
23 --
24 select 6, 2, 1, 99 from dual union all
25 select 7, 3, 2, 10 from dual union all
26 select 8, 4, 7, 83 from dual)
27 --
28 select b.name subject, s.name student, m.marks
29 from marks m join subjects b on b.subjectid = m.subjectid
30 join studentdata s on s.studentid = m.studentid
31 where m.marks = (select max(m1.marks)
32 from marks m1
33 where m1.subjectid = m.subjectid
34 )
35 order by b.name, s.name;
SUBJECT STUDENT MARKS
-------------- ------- ----------
business stg olivier 78
java noah 99
mgt accounting olivier 63
python olivier 45
social studies mason 83
social studies olivier 83
6 rows selected.
SQL>
-
问题内容: 我有一个数据库,并且使用查询来生成一个中间表,如下所示: 我想为a <avg(a)的用户计算b的标准偏差 我以这种方式计算avg(a),并且效果很好: 但是查询: 返回一个错误,更准确地说,我被告知无法识别avg中的“ a”(选择a from …)。这使我感到非常困惑,因为它可以在上一个查询中使用。 如果有人可以帮助我,我将不胜感激。 编辑: 我将查询结果存储到临时表中以生成中间表,但
-
我想知道JPQL是否可以嵌套查询。我正在学习Spring Data JPA,我也上传了几个相关的问题。 如果MySQL中有以下sql,我如何生成JPQL: 我有两个实体。 上面的实体有一个@OneTo多集合,集合实体在下面。 我想得到不到10个孩子的作弊实体。
-
我有一个sql查询: 这就产生了: Hibernate:选择this_.pName为y0_,this_.kNum为y1_,count(distinct this_.agentg)为y2_from Test_CPView this_where(低(this_.pName+“~”+this_.kNum)like?或低(this_.pName+“~”+this_.kNum)like?或低(this_.p
-
问题内容: 表格1: 表2: 我只需要在值TABLE1。“ SALE_SUM_PIECES”小于TABLE2中“ PIECES”的总和时减去on的值。例如:的值就是。现在,我需要检查SUM的值在哪一行。在下面的示例中,TABLE2中的第一行无效,因为7大于6。但是TABLE2中的第二行是有效的,因为row1中“块”的总和并且TABLE2中的row2即6 + 10 = 16大于7。因此,我需要从第二
-
问题内容: 这是我在elasticsearch中存储在索引上的数据类型。我必须找到包含主要成分牛肉(且重量小于1000)和成分-(辣椒粉且重量小于250),(橄榄油和重量小于300)以及所有其他成分类似的食谱。 索引的映射是 我的查询是 但这给了Null。有人可以帮我吗?我认为我没有正确使用嵌套查询 问题答案: 试试这个:
-
问题内容: 我想使用ES进行图书搜索。因此,我决定将作者姓名和标题(作为嵌套文档)放入索引,如下所示: 我不明白的是:如何构造搜索查询,以便在搜索“一二”时仅找到第二本书,而在搜索“二三”时什么也找不到,而在搜索“一”时所有图书呢? 问题答案: 也许是这样的? 该查询基本上说一个文件必须有and 。您可以轻松地重新配置该查询。例如,如果您只想搜索作者,请删除嵌套部分。如果您想要另一本书,请更改嵌套