
Taier是袋鼠云数栈大数据家族的开源项目之一 ,它是一个分布式可视化的DAG任务调度系统,旨在降低ETL开发成本、提高大数据平台稳定性,让大数据开发人员可以在Taier直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
一、架构设计和功能详解
在架构设计与功能特点上,Taier整体架构是使用插件式的开发模式,在任务开发下面有调度模块和各项组件,也包括数栈开源家族的Chunjun等等。
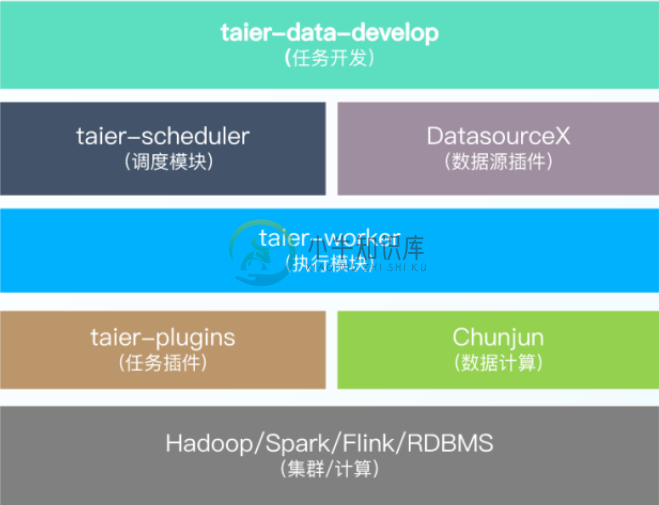
(一)Taier功能特点
Taier的功能特点有下面几个比较重要的方面:
1.任务类型:Spark SQL、数据同步(流计算任务);
2.控制台:包括队列管理、资源管理、多集群管理等;
3.运维中心:比如任务管理、周期调度、补数据等;
4.插件化开发:具体包括 taier-plugin、、DatasourceX、Chunjun等几个插件。

(二)Taier功能特征
随着不断更新完善,现在的Taier已经具有以下的几种特性:
1、拓展性
-
单点故障:去中心化的分布式模式
-
高可用方式:Zookeeper
-
过载处理∶分布式节点+两级存储策略+队列机制。每个节点都可以处理任务调度与提交;任务多时会优先缓存在内存队列,超出可配置的队列最大数量值后会全部落数据库;任务处理以队列方式消费,队列异步从数据库获取可执行实例
-
实战检验:得到数百家企业客户生产环境实战检验
2、易用性
-
支持大数据作业Spark、Flink的调度;
-
支持众多的任务类型,目前支持Spark SQL、Chunjun
-
可视化工作流配置︰支持封装工作流、支持单任务运行,不必封装工作流、支持拖拽模式绘制;
-
DAG监控界面:运维中心、支持集群资源查看,了解当前集群资源的剩余情况、支持对调度队列中的任务批量停止、任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然;
-
调度时间配置:可视化配置;
-
多集群连接:支持一套调度系统连接多套Hadoop集群。
3、多版本引擎
-
支持Spark 、Flink等引擎的多个版本共存,例如可同时支持Flink1.10、Flink1.12(后续开源)
-
Kerberos支持Spark、Flink
-
丰富,支持3种时间基准,且可以灵活设置输出格式。
4、拓展性
-
设计之处就考虑分布式模式,目前支持整体Taier 水平扩容方式;调度能力也随集群线性增长。
二、Taier重要概念
下面从原理和操作层面给大家进一步介绍Taier,还有一些具体概念的解释。
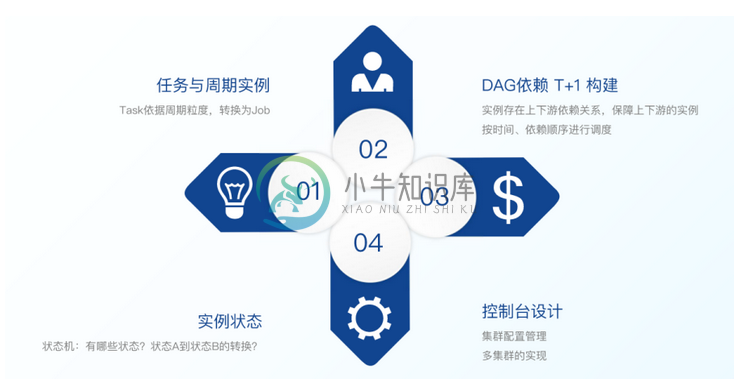
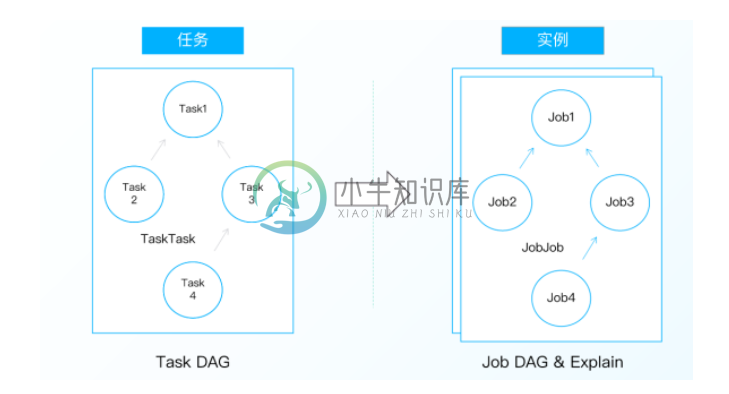
(一)任务与实例
方便起见,数栈在Taier中提出“任务”和“实例”两个概念,例如数据开发的数据同步这项工作称之为“任务”,而已经提交并且配置了周期属性的任就称之为“实例”。
(二)实例具体操作
在Taier中,实例有这几种构建的方式:
1.基于Zookeeper选举Master节点参与Job 实例构建,T+1构建JobGraph
2. JobGraph构建前check &clean DirtyData
3.依据Task、TaskTask的数据(JobGraph)生成Job .JobJob实例数据
4.Master节点控制实例数据的负载均衡持久化入数据库
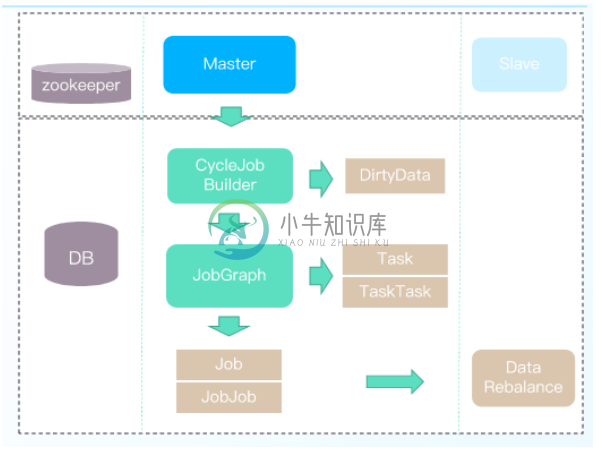
构建完毕后,实例处理的几种方式如下图所示:
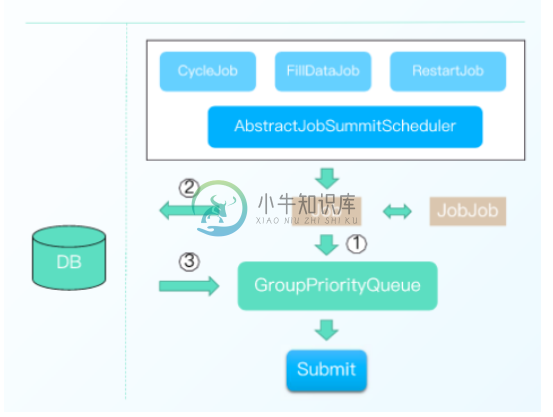
其中:
1.三种任务类型:周期任务、补数据任务、重跑任务,统一调度方式
2. Job 优先入队列(1),队列容量不足入DB (2)
3.当队列容量空余时,异步线程从DB加载数据入队列(3)
4. Job出队列后进行任务提交
处理完成后,实例提交我们也做了思考,具体设计:
1.内存优先级队列,控制Job有序执行
2.多线程并发提交(可配置)
3. Job 执行超时判断(可配置)
4. Job资源不足/失败重试进入延迟队列(可配置)﹔避免长时间占用提交权
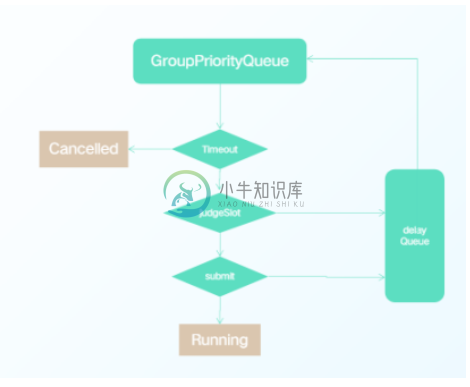
Taier 的实例状态大家主要应该关注标志停止的几个,具体有下面几种:
1. WaitEngine:内存队列中的Job、内存容量不足存储在DB中的Job(默认500 )
2. Lacking:资源不足暂时等待的Job(默认2min)
3. Restarting:失败重试的Job(默认2min )
4. Finshed、Failed、Canceled、Killed:结束状态
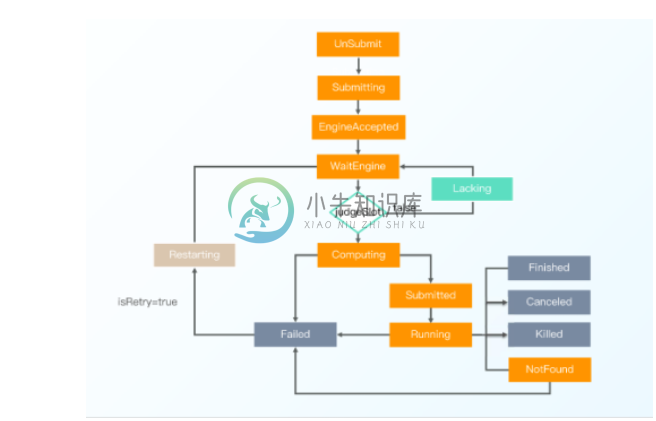
Taier的整个控制台设计分为公共组件、调度组件、存储组件和计划组件。通过一个租户ID,拿到这个集群下common, YARN-conf等的四个配置信息,组成包含一个任务插件所有信息的pluginlnfo。将它解析之后,一些资源初始化上传,以便我们缓存对应的客户端。
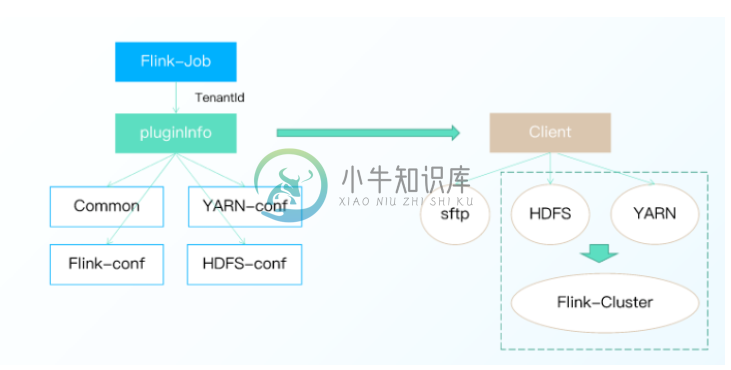
Taier Client Plugin这里,要快速开发一个插件要注意以下几点:
-
一种任务类型对应一个插件,即一个jar包
-
自定义类加载器(Classloader) 破坏双亲委派优先加载( Child-First)插件
-
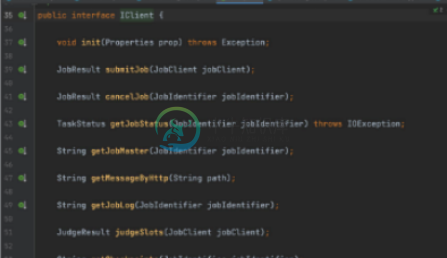
插件实现IClient接口方法
-
SPI: 在classpath 下的META-INF/services/目录下,创建以接口IClient 全限定名命名的文件,内容是上一步中实现类的全限定名
-
简介 如今,数字化转型已成为全球浪潮,大数据平台建设成为新时代必不可少的基础设施。随着数字化转型的深入,很多企业在建设数据中台过程中,将涉及大量数据采集、处理、计算等方面的工作,需求的不断叠加,出现了单个系统难以满足复杂业务的情况,迫切需要一种兼容多个子系统互相协作的任务调度系统协调,正是基于这种背景,Taier分布式DAG任务调度系统应运而生。 Taier是一个开箱即用的分布式可视化的DAG任务
-
我们很高兴向大家宣布,2023年4月14日,Taier 正式发布 1.4 版本。自2022年2月份 Taier 正式开源以来,收到了很多开发者和行业用户的积极评价,在诸多生产环境中已得到充分应用。Taier 1.4版本正是吸收了各类实践经验及大家的建议,进行了此次迭代优化。 本次更新不仅包含了性能优化和稳定性的提升,还新增了各类任务类型、完善大量任务功能,优化使用场景,持续增强开源产品化技术能力和
-
简介 在过去,开发者必须在服务器上为每个任务生成单独的 Cron 项目。而令人头疼的是任务调度不受源代码控制,而且必须通过 SSH 连接到服务器上来增加 Cron 项目。 Laravel 的命令调度程序允许你在 Laravel 中对命令调度进行清晰流畅的定义。并且在使用调度程序时,只需要在服务器上增加一条 Cron 项目即可。调度是在 app/Console/Kernel.php 文件的 sche
-
基本任务调度 方案1: 通过 @Cron 注解,这个需要依赖 cron4j 框架: //1分钟执行一次 @Cron("*/1 * * * *") public class MyTask implements Runnable { @Override public void run() { System.out.println("task running...");
-
我有一些任务的持续时间是已知的整数长度。任务之间也有依赖关系。我也有任意数量的员工可以安排这些任务。 我想为他们找到一个最佳的时间表,首先我要最小化所有任务执行的总长度,其次我想在一个之前运行过大多数依赖项的工作人员身上安排任务,第三我想最小化所需的工作人员数量。 因此,如果任务具有依赖项A、B和C,并且worker1运行A和B,worker2运行C,那么我更希望将新任务添加到worker1。 我
-
在处理一组数据时,您通常想做的第一件事就是了解变量的分布情况。本教程的这一章将简要介绍seaborn中用于检查单变量和双变量分布的一些工具。 您可能还需要查看[categorical.html](categorical.html #categical-tutorial)章节中的函数示例,这些函数可以轻松地比较变量在其他变量级别上的分布。 import seaborn as sns import m
-
在这最后一章中,我们将回到:kv应用程序,给它添加一个路由层,使之可以根据桶的名字,在各个节点间分发请求。 路由层会接收一个如下形式的路由表: [{?a..?m, :"foo@computer-name"}, {?n..?z, :"bar@computer-name"}] 路由者(负责转发请求的角色,可能是个节点)将根据桶名字的第一个字节查这个路由表, 然后根据路由表所示将用户对桶的请求发给相应
-
统计分析是了解数据集中的变量如何相互关联以及这些关系如何依赖于其他变量的过程。可视化是此过程的核心组件,这是因为当数据被恰当地可视化时,人的视觉系统可以看到指示关系的趋势和模式。 我们将在本教程中讨论三个seaborn函数。我们最常用的是relplot()。这是一个relplot()将FacetGrid 与两个 axes-level 函数组合在一起: scatterplot() (kind="sc