
Apache DolphinScheduler简介
Apache DolphinScheduler(Incubator,原Easy Scheduler)是一个可视化的分布式大数据工作流任务调度系统,DolphinScheduler 致力于“可视化操作工作流(任务)之间的依赖关系,并可视化监控整个数据处理过程”。DolphinScheduler以有向无环图(DAG)的方式将任务组装起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及Kill任务等操作。

DolphinScheduler的起源 - 需求决定
大数据任务调度需要解决以下痛点,市面上难以找到满足需求的开源大数据调度,这是DolphinScheduler诞生的原因
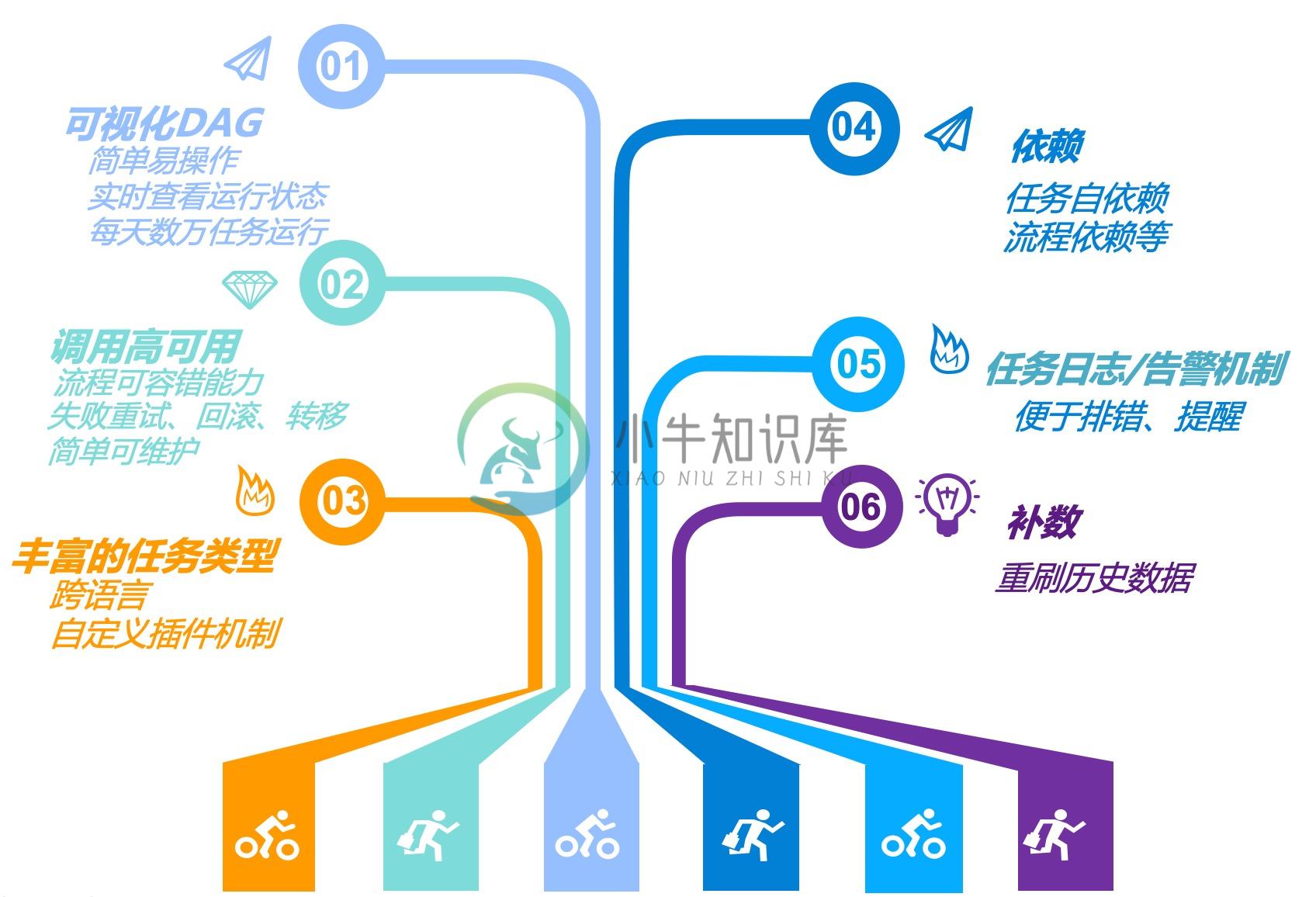
DolphinScheduler设计特点
一个分布式易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。 其主要目标如下:
- 以DAG图的方式将Task按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
- 支持丰富的任务类型:Shell、MR、Spark、SQL(mysql、postgresql、hive、sparksql),Python,Sub_Process、Procedure等
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill任务等操作
- 支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败
- 支持工作流全局参数及节点自定义参数设置
- 支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑
- 支持任务日志在线查看及滚动、在线下载日志等
- 实现集群HA,通过Zookeeper实现Master集群和Worker集群去中心化
- 支持对
Master/Workercpu load,memory,cpu在线查看 - 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计
- 支持补数
- 支持多租户
- 支持国际化
系统部分截图
他们正在使用 DolphinScheduler
目前已经有 1000 多家公司在使用 DolphinScheduler 作为大数据任务调度,部分案例如下(排名不分先后):
奖项




如何加入贡献
欢迎添加微信贡献者:easyworkflow,并告知想贡献即可
获得帮助
-
Apache Dolphinscheduler 最新 3.1.4 概述 Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。 Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解
-
同传统的集中式版本控制系统(CVCS)不同,Git 的分布式特性使得开发者间的协作变得更加灵活多样。 在集中式系统中,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。 而在 Git 中,每个开发者同时扮演着节点和集线器的角色——也就是说,每个开发者既可以将自己的代码贡献到其他的仓库中,同时也能维护自己的公开仓库,让其他人可以在其基础上工作并贡献代码。 由此,Git 的分布式协作可以为
-
你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令。你现在可以学习如何利用 Git 提供的一些分布式工作流程了。 这一章中,你将会学习如何作为贡献者或整合者,在一个分布式协作的环境中使用 Git。 你会学习为一个项目成功地贡献代码,并接触一些最佳实践方式,让你和项目的维护者能轻松地完成这个过程。另外,你也会学到如何管理有很多
-
假设Alice现在开始了一个新项目,在/home/alice/project建了一个新的git 仓库(repository);另外Bob的工作目录也在同一台机器,他要提交代码。 Bob 执行了这样的命令: $ git clone /home/alice/project myrepo 这就建了一个新的叫"myrepo"的目录,这个目录里包含了一份Alice的仓库的 克隆(clone). 这份克隆和
-
简介 在过去,开发者必须在服务器上为每个任务生成单独的 Cron 项目。而令人头疼的是任务调度不受源代码控制,而且必须通过 SSH 连接到服务器上来增加 Cron 项目。 Laravel 的命令调度程序允许你在 Laravel 中对命令调度进行清晰流畅的定义。并且在使用调度程序时,只需要在服务器上增加一条 Cron 项目即可。调度是在 app/Console/Kernel.php 文件的 sche
-
基本任务调度 方案1: 通过 @Cron 注解,这个需要依赖 cron4j 框架: //1分钟执行一次 @Cron("*/1 * * * *") public class MyTask implements Runnable { @Override public void run() { System.out.println("task running...");
-
我有一些任务的持续时间是已知的整数长度。任务之间也有依赖关系。我也有任意数量的员工可以安排这些任务。 我想为他们找到一个最佳的时间表,首先我要最小化所有任务执行的总长度,其次我想在一个之前运行过大多数依赖项的工作人员身上安排任务,第三我想最小化所需的工作人员数量。 因此,如果任务具有依赖项A、B和C,并且worker1运行A和B,worker2运行C,那么我更希望将新任务添加到worker1。 我
-
我在Openshift集群上安装了一个Spring Cloud数据流。我尝试注册一个应用程序,然后创建一个任务,一切都很好,但当我试图安排任务时,我遇到了以下异常: 我不知道这是什么意思,我是Dataflow的新手。我不明白为什么他试图使用Maven而不是kubernetes部署器,也不明白为什么我会出现这个错误。有人能再给我解释一下吗? 顺便说一句,我将这些应用程序注册为docker容器。
-
在这最后一章中,我们将回到:kv应用程序,给它添加一个路由层,使之可以根据桶的名字,在各个节点间分发请求。 路由层会接收一个如下形式的路由表: [{?a..?m, :"foo@computer-name"}, {?n..?z, :"bar@computer-name"}] 路由者(负责转发请求的角色,可能是个节点)将根据桶名字的第一个字节查这个路由表, 然后根据路由表所示将用户对桶的请求发给相应