
fq 是一个用于检查二进制数据的工具和解析器。
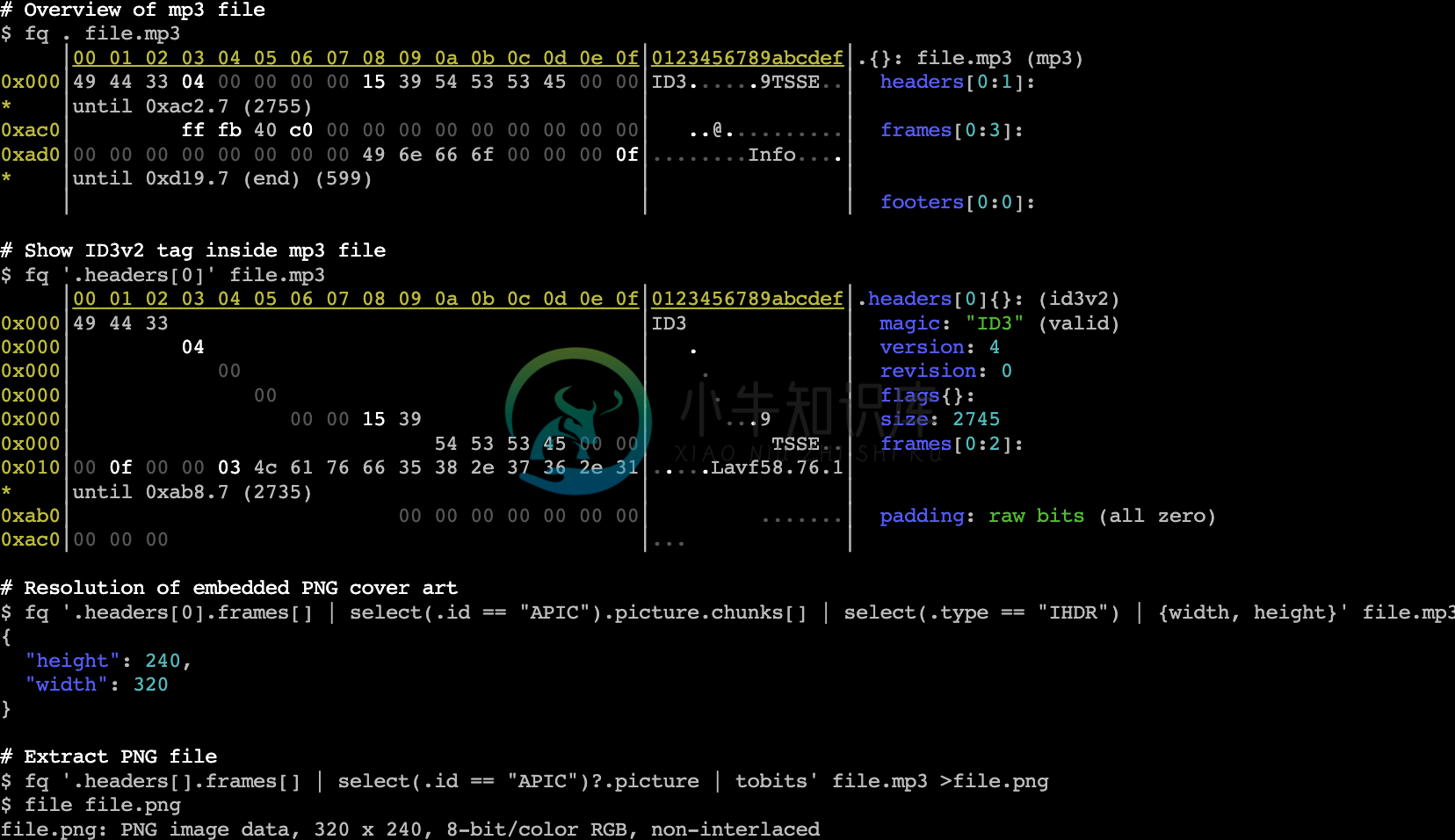
在大多数情况下,fq 的工作方式与 jq 相同,但它不是读取 JSON,而是读取二进制数据。结果是一个 JSON 兼容的结构,其中每个值都有一个位范围、符号解释并知道如何以有用的方式呈现。
目标
- 使二进制格式可访问和可查询
- 嵌套格式和面向位的解码
- 快速而舒适的 CLI 工具
- 位和字节转换和转换
- 程序员的计算器
用法
基本用法是fq . file
安装
下载适用于各个平台的发行版,将其解压缩并将可执行文件移动到PATHetc.
Homebrew
# install latest release
brew install wader/tap/fq
从源代码构建
确保你已经安装了 Go 1.17 或更高版本。
要直接从 git 存储库安装,请执行以下操作:
# build and install latest release go install github.com/wader/fq@latest # or build and install latest master go install github.com/wader/fq@master # copy binary to $PATH if needed cp "$(go env GOPATH)/bin/fq" /usr/local/bin
从源目录构建和运行测试:
make test fq # copy binary to $PATH if needed cp fq /usr/local/bin
支持的格式
aac_frame, adts, adts_frame, apev2, av1_ccr, av1_frame, av1_obu, avc_annexb, avc_au, avc_dcr, avc_nalu, avc_pps, avc_sei, avc_sps, bzip2, dns, dns, fmeta_frame, fmeta_frame, fmeta_frame, fmeta_frame, fmeta_frame, fmeta1lacp, fmeta_frame, fc_datablock, flaccp, fmeta_frame, fmetalacp, fmeta_frame, fmetalacp, fmeta_frame flac_streaminfo, gif, gzip, hevc_annexb, hevc_au, hevc_dcr, hevc_nalu, icc_profile, icmp, id3v1, id3v11, id3v2, ipv4_packet, jpeg, json, matroska, mp3, mp3_frame,mpegtegs,mpegt_frame,mpegs_mpegs,mpegs_mpegs_mpegs ogg, ogg_page, opus_packet, pcap, pcapng, png, protobuf, protobuf_widevine, pssh_playready, raw, sll2_packet, sll_packet, tar, tcp_segment, tiff, udp_datagram, vorbis_comment, vcc_comment, vcc_comment, vcc_comment, vcc_comment, vcp8, vcp8, vcp9, vc_frame,
-
在介绍FQ入队列操作之前,先看一下流量的识别部分。 1 流量识别 对于一些协议报文,比如HSR(High-availability Seamless Redundancy)、IGMP和HDLC等,其将priority字段设置为了TC_PRIO_CONTROL,对于此类报文,FQ使用一个内部特定的流处理(q->internal)。 static struct fq_flow *fq_classify
-
FQ队列中对发送时间未到的流结构单独存放在delayed红黑树中,这样的流结构即不在new_flow链表,也不在old_flow链表,其next指针执行一个特定的值:throttled。内核函数通过检查流结构的next指针,来判断流是否处于throttled状态。 new_flow链表中的流结构的优先级高于old_flows中的流。 /* special value to mark a detac
-
fq_codel这个新的机制进入内核已经有一段时间了,主要是在Linux的Wi-Fi子系统中使用。但是目前好像并没有像样的中文的介绍。正好之前参与开源组织合作开发Airtime fairness(ATF)的时候,有比较深入的去了解它的大致原理,这里试着缕一缕它的大致逻辑。 目录 I. fq-codel 的由来 II. fq-codel的基本原理 I. fq-codel 的由来 如果不做些searc
-
shenwei爪哥开发的处理Fasta/Fastq文件的万能工具。之前处理fq/fa文件时花时间写的一些脚本发现在seqkit里直接能一行命令就解决。实在是提升效率,整合流程中十分好的工具。本文是对Seqkit官方介绍(https://bioinf.shenwei.me/seqkit/usage/)的学习,参考学习的过程中可以对照着官方文档中的例子进行操作学习。 熟练的运用关键还是需要多练习,搭建
-
忙活了很久,组装基因组我发现还是有点不对劲我决定从头开始 我的HIFI数据是bam格式,今天遇到一个行家,大佬问我的bam是subreadsbam 还是ccsbam。这个问题难到我了,从老板那里拿到数据的时候我也没看名字,文件名里面也没有写。我草草给大佬截完图之后大佬说这是CCSbam,直接转fq就行,用bamTofq。我测试了一下! bamToFastq [OPTIONS] -i <BAM> -
-
1、fq文件格式 fastq格式是一种包含质量值的序列文件,一般用来存储原始测序数据。下面是fastq格式常见的序列格式。 @FCD056DACXX:3:1101:2163:1959#TCGCCGTG/1 TCCGATAACGCTCAACCAGAGGGCTGCCAGCTCCGATCGGCAGTTGCAACCCATTGGCCGTCTGAGCCAGCAACCCCGGA + gggiiiiiiiii
-
问题内容: 我正在编写一些代码来与Redmine交互,并且作为过程的一部分,我需要上传一些文件,但是我不确定如何从包含二进制文件的python发出POST请求。 我正在尝试模仿这里的命令: 在python中(如下),但它似乎不起作用。我不确定问题是否与编码文件有关,或者标题是否有问题。 我可以访问服务器,它看起来像是编码错误: 问题答案: 基本上您所做的是正确的。查看链接到的redmine文档,U
-
我正在编写一些与redmine接口的代码,并且我需要上传一些文件作为过程的一部分,但是我不确定如何从包含二进制文件的python发出POST请求。 我尝试在这里模拟命令: 在python中(如下),但它似乎不起作用。我不确定这个问题是否与文件编码有关,或者标题是否有问题。 我可以访问服务器,它看起来像一个编码错误:
-
本章将会讨论一个常见任务:解析(parsing)二进制文件。选这个任务有两个目的。 第一个确实是想谈谈解析过程,但更重要的目标是谈谈程序组织、重构和消除样板代码 (boilerplate code:通常指不重要,但没它又不行的代码)。 我们将会展示如何清理冗余代码,并为第十四章讨论 Monad 做点准备。 我们将要用到的文件格式来自于 netpbm 库,它包含一组用来处理位图图像的程序及文件格式,
-
问题内容: 已关闭 。这个问题需要更加集中。它当前不接受答案。 想改善这个问题吗? 更新问题,使其仅通过编辑此帖子来关注一个问题。 2年前关闭。 如何在MySQL中存储二进制数据? 问题答案: phpguy的答案是正确的,但我认为那里的其他细节存在很多混乱。 基本答案是在数据类型/属性域中。 BLOB 是Binary Large Object的缩写,该列数据类型专用于处理二进制数据。 请参见MyS
-
问题内容: 有没有一种类型或方式以二进制级别在oracle中存储数据。我对表中的dml和pl / sql的操作都感兴趣。 当前所有二进制元素都以varchar2(1000)=‘11111 …0000.1111’的形式存储,但是操作和数据存储量很大,因此需要一些优化解决方案。如果此数据可以二进制格式存储,则将需要1000/8字节(具有>700mn条记录) 可能的解决方案是对这些操作使用某种Java
-
用途: 在字符串与二进制数据之间相互转换 打包和拆包 import struct import binascii values = (1, 'ab'.encode('utf-8'), 2.7) s = struct.Struct('I 2s f') packed_data = s.pack(*values) print('Original values:', values) print('Fo