
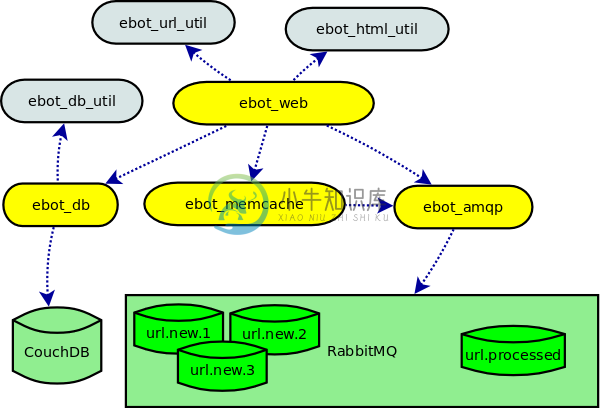
Ebot 是一个用 ErLang 语言开发的可伸缩的分布式网页爬虫,URLs 被保存在数据库中可通过 RESTful 的 HTTP 请求来查询。
-
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
主要内容:导入所需模块,拼接URL地址,向URL发送请求,保存为本地文件,函数式编程修改程序本节讲解第一个 Python 爬虫实战案例:抓取您想要的网页,并将其保存至本地计算机。 首先我们对要编写的爬虫程序进行简单地分析,该程序可分为以下三个部分: 拼接 url 地址 发送请求 将照片保存至本地 明确逻辑后,我们就可以正式编写爬虫程序了。 导入所需模块 本节内容使用 urllib 库来编写爬虫,下面导入程序所用模块: 拼接URL地址 定义 URL 变量,拼接 url 地址。代码如下所示:
-
本文向大家介绍基于C#实现网页爬虫,包括了基于C#实现网页爬虫的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了基于C#实现网页爬虫的详细代码,供大家参考,具体内容如下 HTTP请求工具类: 功能: 1、获取网页html 2、下载网络图片 多线程爬取网页代码: 截图: 以上就是本文的全部内容,希望对大家的学习有所帮助。
-
本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
本文向大家介绍Python制作简单的网页爬虫,包括了Python制作简单的网页爬虫的使用技巧和注意事项,需要的朋友参考一下 1.准备工作: 工欲善其事必先利其器,因此我们有必要在进行Coding前先配置一个适合我们自己的开发环境,我搭建的开发环境是: 操作系统:Ubuntu 14.04 LTS Python版本:2.7.6 代码编辑器:Sublime Text 3.0 这次的网络爬虫需求背景我打算