
aswan 是陌陌开发的风控系统静态规则引擎,零基础简易便捷的配置多种复杂规则,实时高效管控用户异常行为。
架构介绍
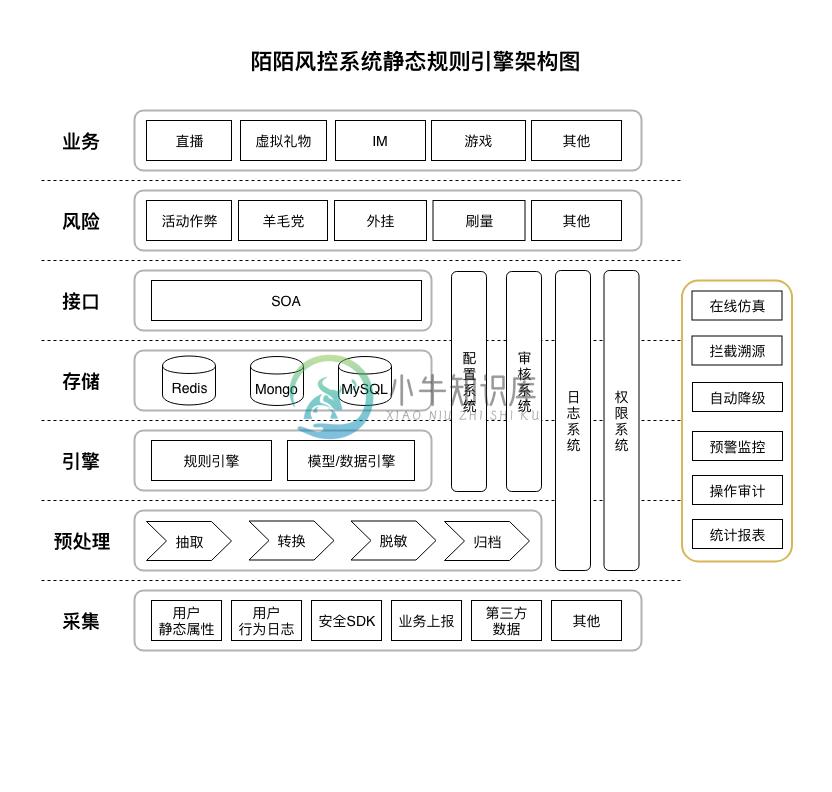
快速启动
- 本项目依赖redis, mysql, mongodb,因此需准备环境并更改配置项
# 为了简单可以使用docker安装
# docker安装文档地址(以ubuntu为例): https://docs.docker.com/install/linux/docker-ce/ubuntu/
mongo: docker run -d --name mongo -v $HOME/docker_volumes/mongodb:/data/db -p 27017:27017 mongo:latest
mysql: docker run -d --name mysql -e MYSQL_ROOT_PASSWORD=root -v $HOME/docker_volumes/mysql:/var/lib/mysql -v $HOME/docker_volumes/conf/mysql:/etc/mysql/conf.d -p 3306:3306 mysql:5.6
redis: docker run -d --name redis -p 6379:6379 -v $HOME/docker_volumes/redis:/var/lib/redis redis:latest
- 在mysql中创建risk_control库
docker exec -it mysql mysql -h 127.0.0.1 -u root -p # 后续需输入密码 若以上述方式安装mysql,密码为root.
CREATE DATABASE risk_control CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; # 创建数据库时指定编码格式,规避乱码问题(注意: 此编码格式在mysql低版本上可能有兼容性问题)
- 安装所需依赖,本项目基于python2.7进行开发,可运行pip install -r requirements.txt安装依赖包
- 初始化django运行所需的表并创建账户,并可以预生成一些数据(可选)
# 在www目录下
python manage.py makemigrations && python manage.py migrate
# 创建管理员账户 此处详见 其它操作--增加用户
python manage.py createsuperuser # 后续 依次输入用户名、密码、邮箱 即可创建一个管理员账号
# 如果希望对系统有一个直观的感受,可以使用如下指令来预注入一些数据
python manage.py init_risk_data
- 启动服务
# 在aswan下以nohup的方式启动服务进程、管理后台、拦截日志消费进程
bash start.sh
后台介绍
-
名单管理
为名单型策略提供基础的数据管理功能。
名单数据的维度包括:用户ID、IP、设备号、支付账号、手机号。后续也可以根据自己的需求扩充其他的维度。
名单包含三个类型:黑、白、灰名单
名单必须属于某个项目(用于确定名单的范围),可以在名单管理-名单项目管理中添加项目。

-
名单型策略
描述符为**{参数名:单选,假设是“用户ID”} {操作码:在/不在} {XX项目:单选,可选全局} 的 {维度:单选}{方向:黑/白/灰名单}**
示例:用户ID 在 初始项目 的 用户黑名单 中

-
布尔型策略
不传阈值的布尔型,描述符为 {参数名:单选,假设是"账号ID"} {操作码:是/不是} {内置函数:异常用户} 示例:账号ID是异常用户
传阈值的布尔型,描述符为 {参数名:单选,假设是"账号ID"} {操作码:大于/小于/等于/不等于} {内置函数:历史登录次数} {阈值:170} 示例:账号ID历史登录次数大于100

内置函数是什么?就是自定义的一些逻辑判断函数,只需要满足要求返回布尔值即可。比如注册时间是否在某个范围以内,当前设备是否是常用设备。 -
时段频控型策略
描述符为 同一 {计数维度:单选,假设是“设备”} 在 {时段:时间跨度} 内限制 {阈值:整数N} 次 某动作 示例:同一设备一天内限制操作10次. 可是我怎么知道当前已经有多少次呢?这就需要上报,上报后将计数 详见第9条 数据源管理

-
限用户数型策略
描述符为 同一 {计数维度:单选,假设是“设备”} 在 {时段:时间跨度} 内限制 {阈值:整数N} 个用户
示例:同一设备当天限10个用户 此策略同样需要上报的数据,且由于与用户相关,因此上报数据中必须包含user_id字段(在数据源中需配置) 详见第9条 数据源管理

-
规则管理
管控原子:命中某条策略后的管控动作,比如拦截... 把上面2--5中所述的策略原子按照优先级组合起来,由上向下执行,直到命中某条策略,则返回对应策略的管控原子。此模块更多是重交互,完成策略的配置、组合、权重等等
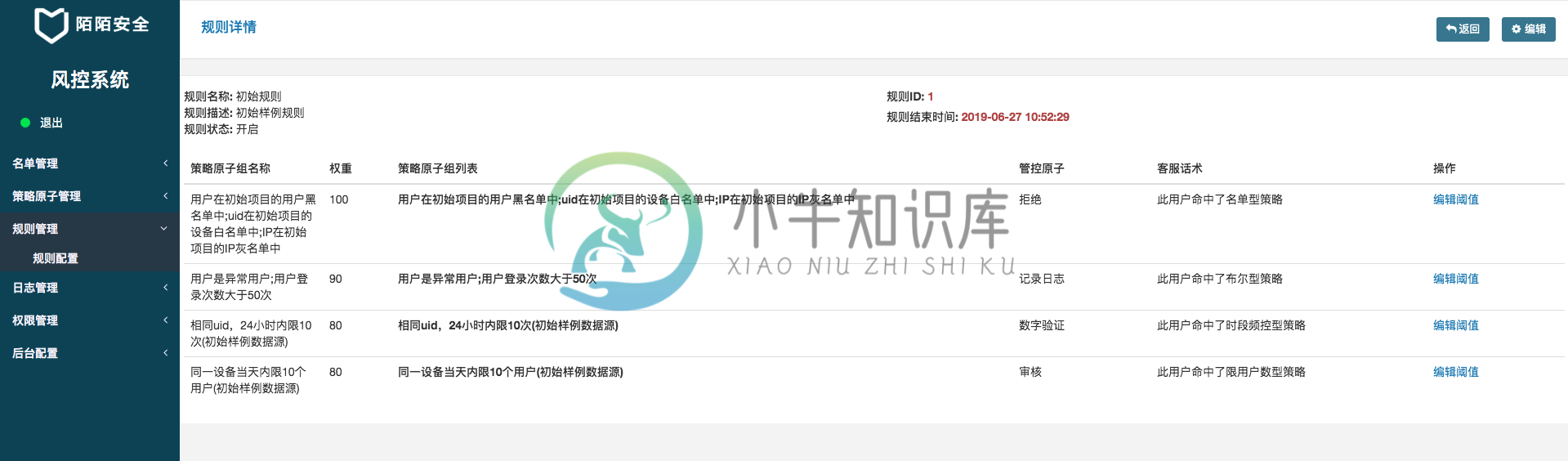
-
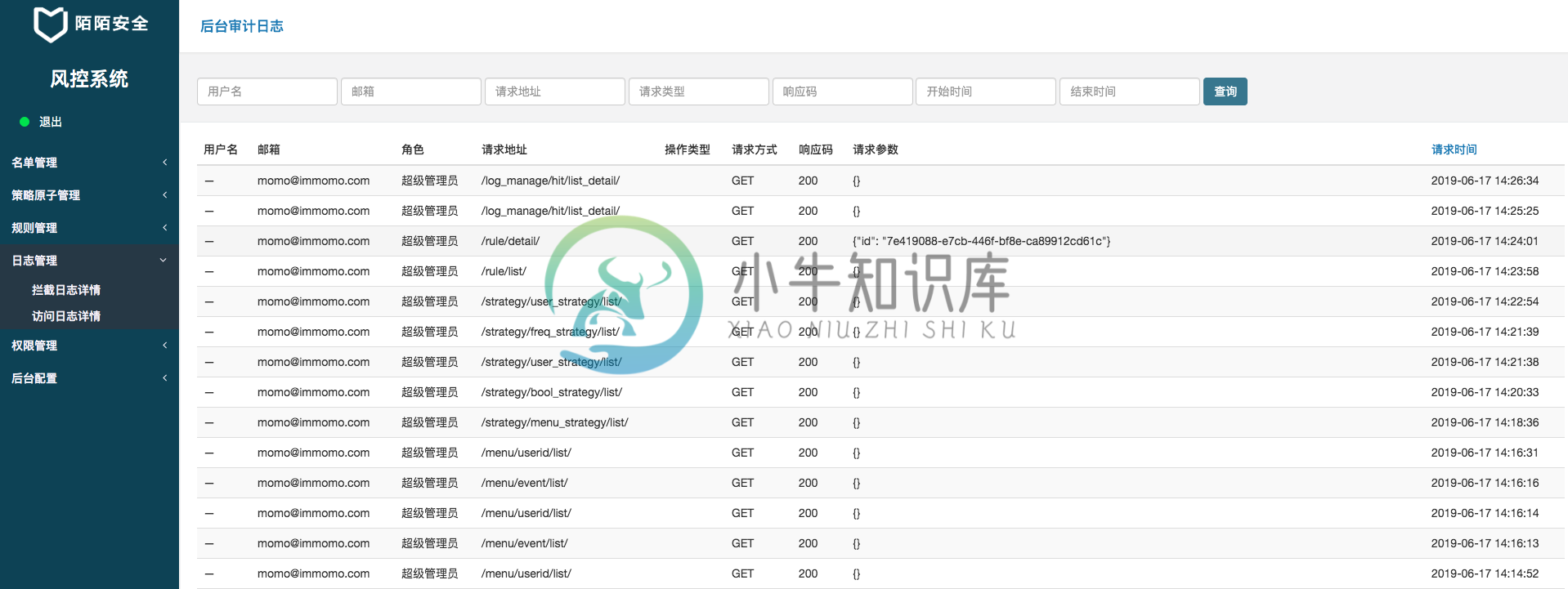
日志管理
所有命中策略的日志均在此展示,也会包含审计相关的日志,
下一期会基于此日志,开放拦截溯源功能。
-
权限配置
供权限设置使用,精确限定某个用户能看哪些页面的数据。 详见 其它 -- 权限管理。
-
数据源配置
示例策略:同一设备一天内限制登录1000次 那么每次登陆就需要上报一条数据,系统会分类计数,并分类存储。 存储的名字叫啥?就是此处要配置的数据源。对于此策略,只需要配置数据源,命名为login_uid, 字段包含uid, uid类型是string。然后程序就能根据uid为维度计数,并自动计算指定时间窗口内是否超出指定阈值。
重要:由于逻辑必然依赖时间信息,为通用且必需字段,timestamp为默认隐含字段,类型是时间戳(精确到秒,整数)

调用样例
-
调用查询服务
假设存在id为1的规则,则可以通过如下方式查询是否命中策略
curl 127.0.0.1:50000/query/ -X POST -d '{"rule_id": "1", "user_id": "10000"}' -H "Content-Type:application/json"
-
调用上报服务
假设存在名称为test的数据源, 且数据源含有的数据是: {"ip": "string", "user_id": "string", "uid": "string"}
curl 127.0.0.1:50000/report/ -X POST -d '{"source": "test", "user_id": "10000", "ip": "127.0.0.1", "uid": "abcabc112333222", "timestamp": 1559049606}' -H "Content-Type:application/json"
-
关于服务拆分
开源样例中,为了简化安装部署,查询和上报揉进了一个服务。实际场景中,显然读写应该分离。
1.可以直接此方式部署2份,域名不同,一份用于查询(上报接口不被访问),一份用于上报(查询接口不被访问),流量分发在nginx层完成
2.risk_server.py中修改配置URL_2_HANDLERS,选择您需要的服务接口部署
内置函数的扩展
-
不带阈值的内置函数扩展
以
是否异常用户内置函数为例
代码见 aswan/buildin_funcs/sample.py 中的 is_abnormal 方法 -
带阈值的内置函数布尔型策略扩展
以
历史登录次数内置函数为例
代码见 aswan/buildin_funcs/sample.py 中的 user_login_count 方法
注意:阈值计算不包含在内置函数中进行,控制流详见 aswan/buildin_funcs/base.py
其它
增加用户
考虑到企业用户大多数为域账户登录,因此推荐使用LDAP认证模块直接集成。但考虑到大家的场景不一样,因此也可以手动增加用户,样例代码如下:
# coding=utf-8 from django.contrib.auth.models import User username = 'username' password = 'password' email = 'email@momo.com' first_name = '测' last_name = '试' # 普通用户 User.objects.create_user(username=username, password=password, email=email, first_name=first_name, last_name=last_name) # 管理员账户 User.objects.create_superuser(username=username, password=password, email=email, first_name=first_name, last_name=last_name)
添加完成后,让用户登录,然后管理员配置权限即可。
权限管理
目前的权限模型包含如下元素,可在对应的页面进行配置。
| 元素名称 | 元素含义 | 配置方式 | 注 |
|---|---|---|---|
| uri | 风控管理后台的一个独立uri | 开发时自动产生 | 此处uri为相对路径,例如: /permissions/groups/ |
| uri组 | 多个相互关联的uri可以被放置到一个uri组中 | /permissions/uri_groups/ | - |
| 权限组 | 多个uri组可以被分配到一个权限组中 | /permissions/groups/ | - |
| 用户 | 用户即为独立的个人/员工 | /permissions/users/ | 1. 本系统在界面上不提供添加用户的功能;2. 用户可以被分配到某个权限组中,也可以直接配置uri组 |
| 管理员 | 即为系统的拥有者,默认拥有所有权限 | 手动配置 | - |
具体图示如下:



配置相关
目前Django部分的配置均存放于 www/settings 目录,非Django部分的配置均位于 config 目录下。
为了在不同环境加载不同的配置,我们使用了RISK_ENV这个环境变量,系统在运行时会自动通过这个环境变量的值加载对应的配置文件。
为了方便项目启动,在未设置这个值时,系统默认会加载 develop 环境的配置。而在执行测试时(python manage.py test)时,RISK_ENV的值必须是 test 。
-
数字中国战略是国家战略,数字产业化和产业数字化是中国发展的新动力,技术创新是经济发展的源动力。 当前新一轮科技革命和产业变革席卷全球,数字产业化和产业数字化成为中国经济发展的新趋势、新动能。区块链技术目前在国际上被认为是非常具有潜力和想象力的一种技术革新,拥有去中心化、不可抵赖、不可篡改、安全及不可逆等基本属性,可以广泛应用在金融、民生、医疗、政务等相关领域。 因此,区块链+数字资产是必然的组合。
-
#陌陌暑期实习生#写一下本次陌陌Java后端笔试体会。 开考系统直接崩了,等了大概40分钟,进去就剩15分钟,但是中间延长了20分钟,不过最后剩13分钟时,倒计时直接变为1分钟,无奈直接交卷了。 一共22道题,20道选择,2道编程 写了写选择,包括但不限于linux,前端http,DNS,消息队列,多线程,封装,继承,多态,redis缓存三兄弟,软件工程内容,git,网络安全,数据结构,数据库索引
-
前言 2022年已经悄然过去一半,马上有到了秋招的时候,对于Android开发者们,也是听到、看到了很多不太利好的消息,很多大厂也是频频冲上热搜,这也着实让大家对自己的前途感到迷茫。 其实近些年来,很多人都在不断地唱衰Android的发展趋势,虽然Android热度不如从前,随着行业的发展,各大厂对于从业者的要求也越来越严格,但其实那些基础知识扎实、开发技能过硬的开发者依旧是各大厂争相抢夺的香饽饽
-
(60mins) 自我介绍 介绍项目 Java基本数据类型 基本数据类型和引用数据类型的区别 基本数据类型哪些不能相互转换 ==和equals Java异常处理机制有哪些 Finally中的代码一定会被执行吗? throw和throws的区别 线程创建的方式 各自的应用场景 callable的返回值是什么 线程池的属性 线程池中核心线程数为5 最大线程数为8,如果核心线程都在执行,再添加个线程会发
-
软件功能:模仿陌陌客户端,功能很相似,注册、登陆、上传照片、浏览照片、浏览查找附近会员、关注、取消关注、聊天、语音和文字聊天,还有拼车和搭车的功能,支持微博分享和查找好友。 后台是php+mysql,前台是xcode工程 前台下载地址:https://github.com/zengchao/MOMO 后台下载地址:https://github.com/zengchao/MOMO_SERVER 上线
-
7.12 一面通过,一面面试体验良好 当天下午hr通知二面 约了7.14的二面 7.14下午三点二面,面试官迟到,与hr沟通后进入会议室开始面试 一上来问了我很多与推荐算法无关的东西(是真不会啊) 问了和开发相关的,什么是推排序,怎么实现, 一个场景题,给你一个不知道长度的链表,怎样等概率的抽取50个数据。。。。。。 就是不问机器学习的相关知识,当场kpi面试官,直接摆烂 之后,问了论文和项目,说
-
陌陌安卓一面 自我介绍 大概讲一讲reactor模型 你采用reactor模型的理由 假设现在2个人在同一个群里几乎同时去更改群名,你如何保证它能被安全正确的修改 数据库的读写锁 数据库ACID 你的群聊是如何实现的 如何判断用户是否在线 TCP和UDP的区别 客户端如何拉取离线消息的 现在用户加入了100个群聊,如何拉取这100个群聊中的离线消息 你刚刚提到界面会卡死的情况,为什么会卡死? 在安
-
线下宣讲会 第一个到,给了我一个衣服,问怎么了解到信息的,我直接贴脸开大说上一次笔试做过,卡了一下(比较委婉,没敢说大范围504,白做一次笔试) 线下笔试内容20道不定项选择,单多选交错在一起,什么正则,linux,shell,数据结构,设计模式都有考察 一道编程,一道思考 编程题是先是模仿redis的geohash编码,交替合并经纬度二进制,转base32输出字符串 手写代码 思考题 五亿的数据
-
7.15 笔试 7.20 一面 无自我介绍 介绍项目 Anchor-free标签匹配方式 小目标信息丢失问题 基线选择 模型压缩技术 代码 7.1 求均方根 7.2 Softmax函数 7.3 交叉熵损失函数 7.27 二面 自我介绍 项目介绍 传统方法如何处理多尺度目标共存问题 双模态语义分割框架 语义分割损失函数 语义分割常见问题 边界模糊问题 点云配准及应用 凉~ #陌陌面试#