
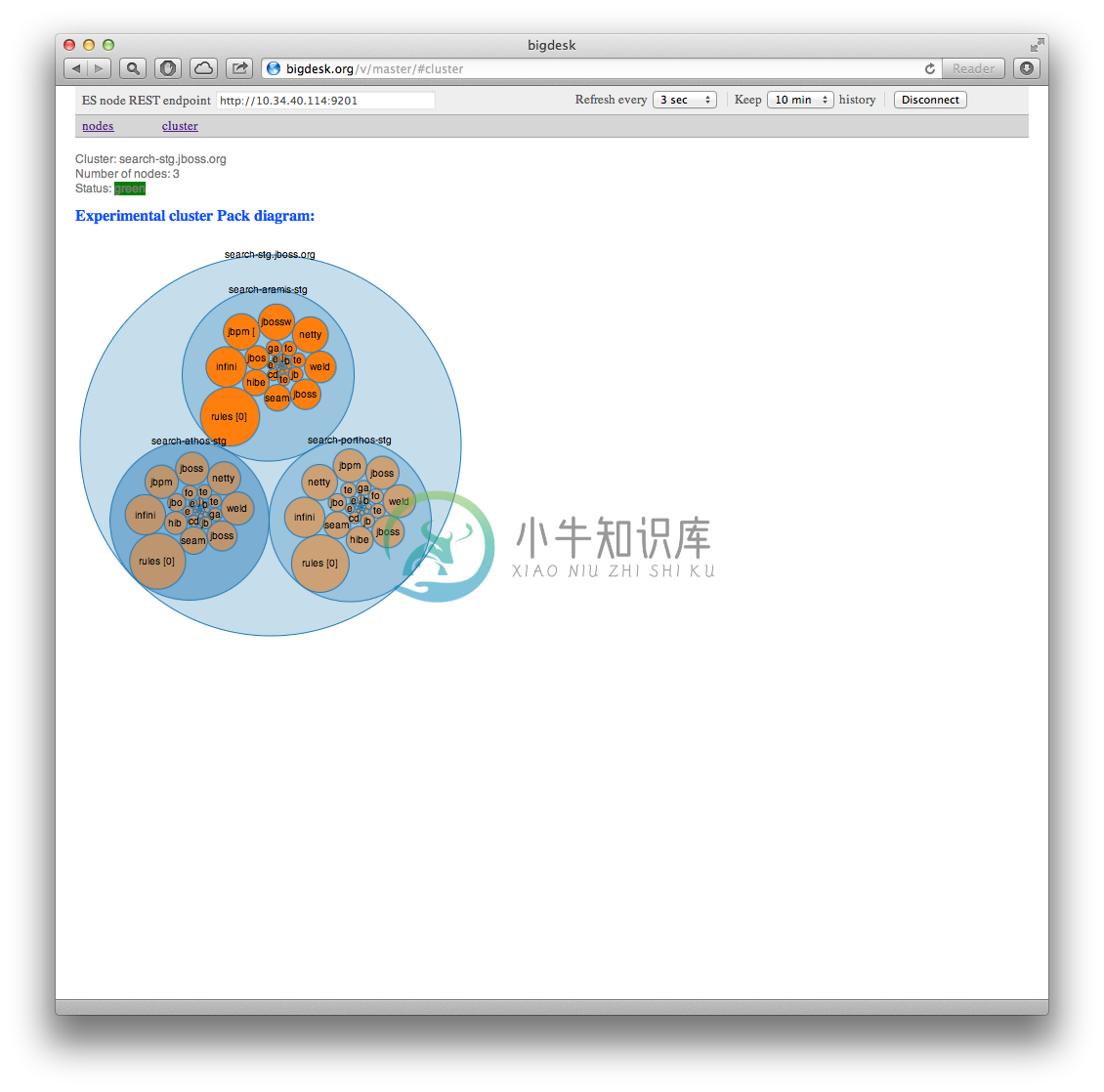
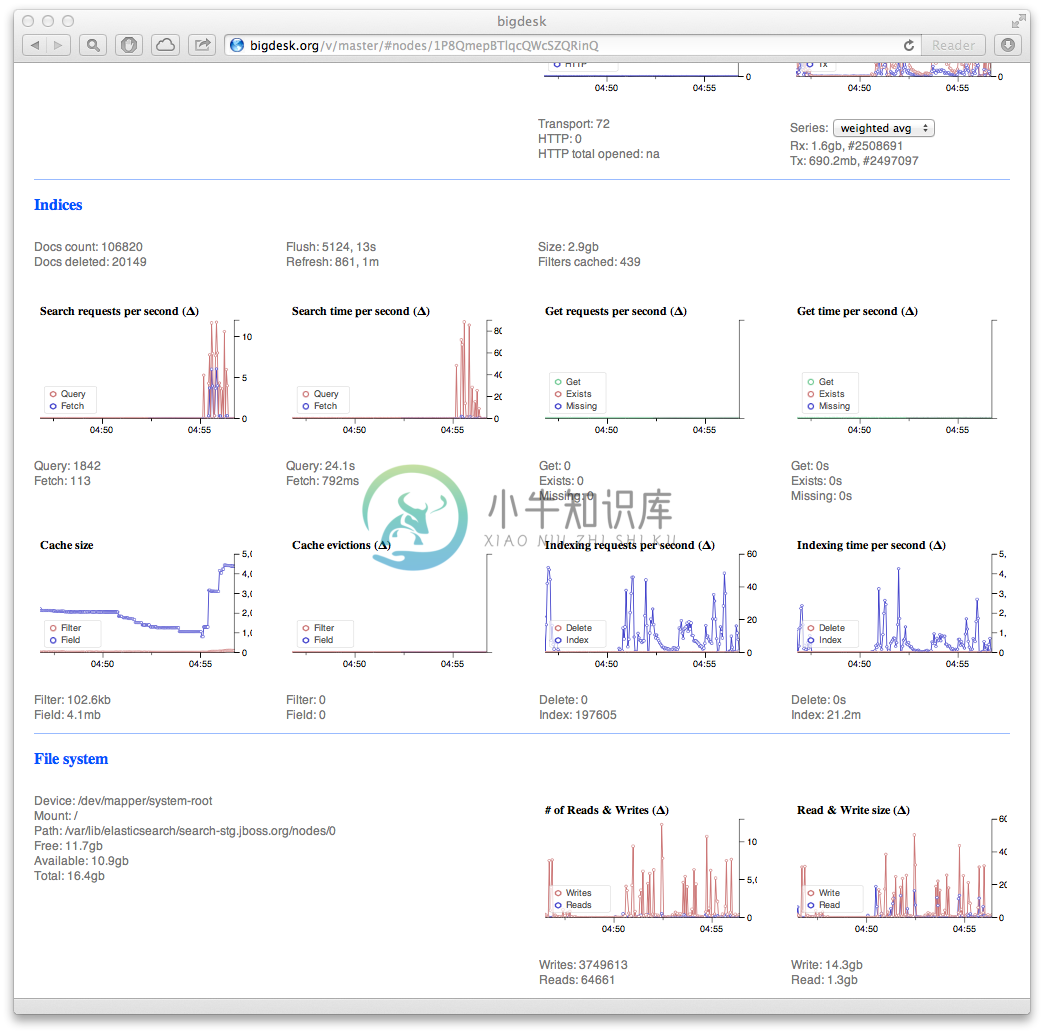
Bigdesk 是 ElasticSearch 的一个集群监控工具,可生成 ElasticSearch 集群的即时图表和统计信息。可以通过它来查看es集群的各种状态,如:cpu、内存使用情况,索引数据、搜索情况,http连接数等。版本对应关系表:
| Bigdesk | Elasticsearch |
|---|---|
| 2.4.0 | 1.0.0.RC1 ... 1.0.x |
| n/a | 1.0.0.Beta1 ... 1.0.0.Beta2 |
| 2.2.3 | 0.90.10 ... 0.90.x |
| 2.2.2 | 0.90.0 ... 0.90.9 |
| 2.2.1 | 0.90.0 ... 0.90.9 |
| 2.1.0 | 0.20.0 ... 0.20.x |
| 2.0.0 | 0.19.0 ... 0.20.x |
| 1.0.0 | 0.17.0 ... 0.18.x |

-
网址:https://www.elastic.co 192.168.14.239 es-node1 192.168.14.240 es-node2 192.168.14.241 es-node3 =====> 初始化 ① 关闭防火墙、selinux sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config setenf
-
#下载 #官网地址https://github.com/hlstudio/bigdesk #解压unzip bigdesk-master.zip *cd bigdesk-master/_site/js/util *在bigdesk_extension.js第四十八行增加如下内容(增加search guard授权认证,如果es
-
1、下载bigdesk插件包 https://github.com/lukas-vlcek/bigdesk 下载master.zip后解压 2、建立elasticsearch-2.x\plugins\bigdesk\_site文件夹 3、将解压后的bigdesk-master文件夹下的文件copy到_site 4、在plugin\bigdesk下创建 plugin-descr
-
ElasticSearch的安装 http://www.elasticsearch.org/下载最新的ElastiSearch版本。 解压下载文件。 cd到${esroot}/bin/,执行elasticsearch启动。 使用curl -XPOST localhost:9200/_shutdown关闭ES。 ElasticSearch的基本配置(这部分配置可以不理会,取默认值) 编辑文件${es
-
原文地址:http://blog.csdn.net/u012085379/article/details/52996634 1、下载bigdesk插件包 https://github.com/lukas-vlcek/bigdesk 下载master.zip后解压 2、建立elasticsearch-2.x\plugins\bigdesk\_site文件夹 3、将解压后的big
-
x-pack权限认证+ bigdesk + Es 5.x bigdesk下载 zip 解压 修改bigdesk-master/_site/js/util/bigdesk_extension.js sync: function(method, model, options) { //options.dataType = 'jsonp'; options.url
-
elasticsearch的版本:1.7.3 windows环境: cmd进入elasticsearch的bin目录下 执行命令: plugin -install lukas-vlcek/bigdesk/2.5.0 linux环境: 执行命令: ./plugin -install lukas-vlcek/bigdesk/2.5.0 访问: http://ip:port/_plugin/bigdes
-
问题内容: 我对SQL(Server2008)的较低层次的了解是有限的,现在我们的DBA对此提出了挑战。让我解释一下这种情况:(我已经提到一些明显的陈述,希望我是对的,但是如果您发现有问题,请告诉我)。 我们有一张桌子,上面放着人们的“法院命令”。创建表(名称:CourtOrder)时,我的创建方式如下: 然后,我将非聚集索引应用于主键(以提高效率)。我的理由是,这是一个唯一字段(主键),应该像我
-
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
一、负载均衡 负载均衡算法 转发实现 二、集群下的 Session 管理 Sticky Session Session Replication Session Server 一、负载均衡 集群中的应用服务器(节点)通常被设计成无状态,用户可以请求任何一个节点。 负载均衡器会根据集群中每个节点的负载情况,将用户请求转发到合适的节点上。 负载均衡器可以用来实现高可用以及伸缩性: 高可用:当某个节点故障
-
集群为一组LBAgent转发节点的集合。 负载均衡集群是一组转发节点LBAgent的集合,一般情况下一个集群下配置两个LBAgent节点互为主备即可,同一集群下的LBAgent节点的VRRP路由ID必须相同。 入口:在云管平台单击左上角导航菜单,在弹出的左侧菜单栏中单击 “网络/负载均衡集群/集群” 菜单项,进入集群页面。 创建集群 该功能用于创建负载均衡集群。 单击列表上方 “新建” 按钮,弹出
-
帮助用户快速搭建Kubernetes集群。 云管平台支持创建和纳管Kubernetes集群,目前支持以下纳管集群的方式。 基于 云联壹云 、Aliyun、AWS 平台的虚拟机创建 Kubernetes 集群。 导入已创建的集群,支持纳管 Kubernetes 集群和 OpenShift 集群。 Kubernetes集群是容器运行所需要的云资源的集合。一个Kubernetes集群由1~3个控制节点和
-
集群章节帮助用户快速搭建集群,并帮助用户管理节点、命名空间以及RBAC授权管理等。 集群 帮助用户快速搭建Kubernetes集群。 节点 节点是Pod的实际运行环境。 存储类 存储类用于定义容器集群中的不同存储类型。 命名空间 命名空间用于逻辑上隔离Kubernetes集群中的资源。 角色 角色定义了对集群的指定命名空间下资源的权限。 集群角色 集群角色定义了对集群下资源的权限。 角色绑定 角色
-
etcd 集群 下面我们使用 Docker Compose 模拟启动一个 3 节点的 etcd 集群。 编辑 docker-compose.yml 文件 version: "3.6"services: node1: image: quay.io/coreos/etcd:v3.4.0 volumes: - node1-data:/etcd-data expose:
-
主版本和次版本升级 Seafile 在主版本和次版本中添加了新功能。有可能需要修改一些数据库表,或者需要更新搜素索引。一般来说升级集群包含以下步骤: 更新数据库 更新前端和后端节点上的符号链接以指向最新版本。 更新每个几点上的配置文件。 更新后端节点上的搜索索引。 一般来说,升级集群,您需要: 在一个前端节点上运行升级脚本(例如:./upgrade/upgrade_4_0_4_1.sh) 在其他所