
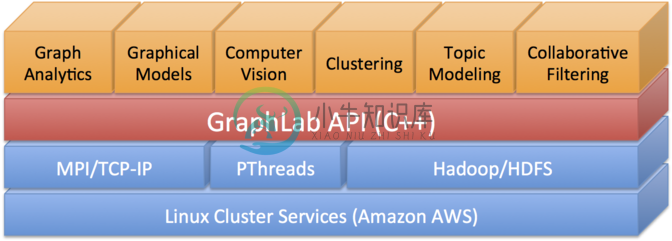
GraphLab 是一个机器学习平台,主要是图模型方面的计算。
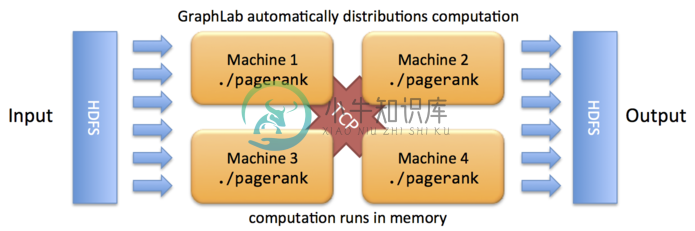
GraphLab 是另一种有趣的MapReduce抽象实现,侧重机器学习算法的并行实现。GraphLab中,Map阶段定义了可以独立执行(在独立的主机上)的计算,Reduce阶段合并这些计算结果。
设计和实施有效且可证明正确的并行机器学习(ML)算法可能非常具有挑战性。 现有的高级并行抽象(如MapReduce)通常无法充分表达,而低级工具(如MPI和Pthreads)则使ML专家反复解决相同的设计难题。通过针对ML中的常见模式,开发了GraphLab,它通过紧凑地表达具有稀疏计算依赖性的异步迭代算法,同时确保数据一致性并实现高度的并行性能,从而改进了MapReduce之类的抽象性。
-
GraphLab库详解:掌握安装和使用方法的完整攻略 GraphLab是一个强大的Python开源机器学习库,它提供了高效的数据处理、图形展示和模型构建等功能。该库支持分布式计算,能够在本地或云端进行模型训练。本文将介绍GraphLab库的安装和基本使用方法。 一、安装GraphLab库 GraphLab官方提供了两种安装方式:GraphLab Create和GraphLab Core。Graph
-
机器学习的一个核心目标是对输入数据进行分类。例如一个训练好的分类器,输入一张图片便可预测这张图中是狗还猫。 用来分类的方法有很多,支持向量机、逻辑回归、深度学习等 假设我们有一个1024行的SFrame数据集, 我们要随机把它分割成90%/10%. >>> sf = graphlab.SFrame({'id': range(1024)}) >>> sf_train, sf_test = sf.ra
-
Py之GraphLab:graphlab库的简介、安装、使用方法之详细攻略 目录 graphlab库的简介 1、GraphLab是什么 2、GraphLab的五大特点 3、为什么需要GraphLab 4、 GraphLab有什么优点 5、比较GraphLab和scikit-learn——GraphLab Create和scikit-learn哪个更好 graphlab库的安装 graphl
-
数据的预处理 导入数据 因为邮政编码zipcode虽然是数值,但是不具有数值的含义,所以我们在导入数据的时候需要将其指派为字符串类型。 事实上,Graphlab Create在训练模型的时候,对于非数值型的数据,比如说str类型的,它会自动进行形如one-hot的dummy操作,并不需要我们自己来完成这个步骤。Graphlab Create在回归模块使用了简单编码,同时使用字符串功能训练模型。 在
-
平台列表 Google Cloud AI Cloud Machine Learning Engine 托管的机器学习服务 AutoML 自动化机器学习 机器学习API,如 Jobs, Video Intelligence, Vision, Speech, Natual Language 以及 Tanslation 等 Amazon Machine Learning SageMaker 自动化机器学
-
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。
-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习课程初级 数学基础中级 机器学习课程中级 推荐书籍列表 机器学习专项领域学习 致谢 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes等其他资
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。 机器学习算法 _图片来自scikit-learn_。 机器学习全景图 _图片来自http://www.shivonzilis.com/_。
-
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。
-
“三个臭皮匠顶个诸葛亮”。集成学习就是利用了这样的思想,通过把多分类器组合在一起的方式,构建出一个强分类器;这些被组合的分类器被称为基分类器。事实上,随机森林就属于集成学习的范畴。通常,集成学习具有更强的泛化能力,大量弱分类器的存在降低了分类错误率,也对于数据的噪声有很好的包容性。
-
10点到3点半,中间停了一个半小时,面完人都傻了,真遭不住...... 一面 基本就围绕实验室项目聊了好久,中间穿插问了几个强化学习算法原理 然后问了深度学习和pytorch 几个简单的点 手撕:一个数组,对每个数可以给+ 或者-号,问有多少种情况可以和为target 二面 基本也是就围绕实验室项目聊了好久 然后再聊了好久Tcmalloc 手撕:一个无序数组,然后把它变成a <= b >= c <
-
一面 约35min 自我介绍 项目内容 项目内mysql和redis的应用 BERT细节 data collator相关 八股 python 协程、线程、进程 go与python最大的不同点 mysql慢查询怎么优化 ddp有没用过 反问: 技术栈(C++和python)、为算法部门服务、资源管理(k8s,docker) 一周内知道结果 二面: 约35min 自我介绍 项目内容 流程介绍、数据集、