

CosId 通用、灵活、高性能的分布式ID生成器
简介
CosId 旨在提供通用、灵活、高性能的分布式 ID 生成器。 目前提供了俩类 ID 生成器:
SnowflakeId: 单机 TPS 性能:409W/s JMH 基准测试 , 主要解决 时钟回拨问题 、机器号分配问题 并且提供更加友好、灵活的使用体验。SegmentId: 每次获取一段 (Step) ID,来降低号段分发器的网络IO请求频次提升性能。IdSegmentDistributor: 号段分发器(号段存储器)RedisIdSegmentDistributor: 基于 Redis 的号段分发器。JdbcIdSegmentDistributor: 基于 Jdbc 的号段分发器,支持各种关系型数据库。
SegmentChainId(推荐):SegmentChainId(lock-free) 是对SegmentId的增强。性能可达到近似AtomicLong的 TPS 性能:12743W+/s JMH 基准测试 。PrefetchWorker维护安全距离(safeDistance), 并且支持基于饥饿状态的动态safeDistance扩容/收缩。
快速开始
背景(为什么需要分布式ID)
在软件系统演进过程中,随着业务规模的增长,我们需要进行集群化部署来分摊计算、存储压力,应用服务我们可以很轻松做到无状态、弹性伸缩。 但是仅仅增加服务副本数就够了吗?显然不够,因为性能瓶颈往往是在数据库层面,那么这个时候我们就需要考虑如何进行数据库的扩容、伸缩、集群化,通常使用分库、分表的方式来处理。 那么我如何分片(水平分片,当然还有垂直分片不过不是本文需要讨论的内容)呢,分片得前提是我们得先有一个ID,然后才能根据分片算法来分片。(比如比较简单常用的ID取模分片算法,这个跟Hash算法的概念类似,我们得先有key才能进行Hash取得插入槽位。)
当然还有很多分布式场景需要分布式ID,这里不再一一列举。
分布式ID方案的核心指标
- 全局(相同业务)唯一性:唯一性保证是ID的必要条件,假设ID不唯一就会产生主键冲突,这点很容易可以理解。
- 通常所说的全局唯一性并不是指所有业务服务都要唯一,而是相同业务服务不同部署副本唯一。 比如 Order 服务的多个部署副本在生成
t_order这张表的Id时是要求全局唯一的。至于t_order_item生成的ID与t_order是否唯一,并不影响唯一性约束,也不会产生什么副作用。 不同业务模块间也是同理。即唯一性主要解决的是ID冲突问题。
- 通常所说的全局唯一性并不是指所有业务服务都要唯一,而是相同业务服务不同部署副本唯一。 比如 Order 服务的多个部署副本在生成
- 有序性:有序性保证是面向查询的数据结构算法(除了Hash算法)所必须的,是二分查找法(分而治之)的前提。
- MySq-InnoDB B+树是使用最为广泛的,假设 Id 是无序的,B+ 树 为了维护 ID 的有序性,就会频繁的在索引的中间位置插入而挪动后面节点的位置,甚至导致频繁的页分裂,这对于性能的影响是极大的。那么如果我们能够保证ID的有序性这种情况就完全不同了,只需要进行追加写操作。所以 ID 的有序性是非常重要的,也是ID设计不可避免的特性。
- 吞吐量/性能(ops/time):即单位时间(每秒)能产生的ID数量。生成ID是非常高频的操作,也是最为基本的。假设ID生成的性能缓慢,那么不管怎么进行系统优化也无法获得更好的性能。
- 一般我们会首先生成ID,然后再执行写入操作,假设ID生成缓慢,那么整体性能上限就会受到限制,这一点应该不难理解。
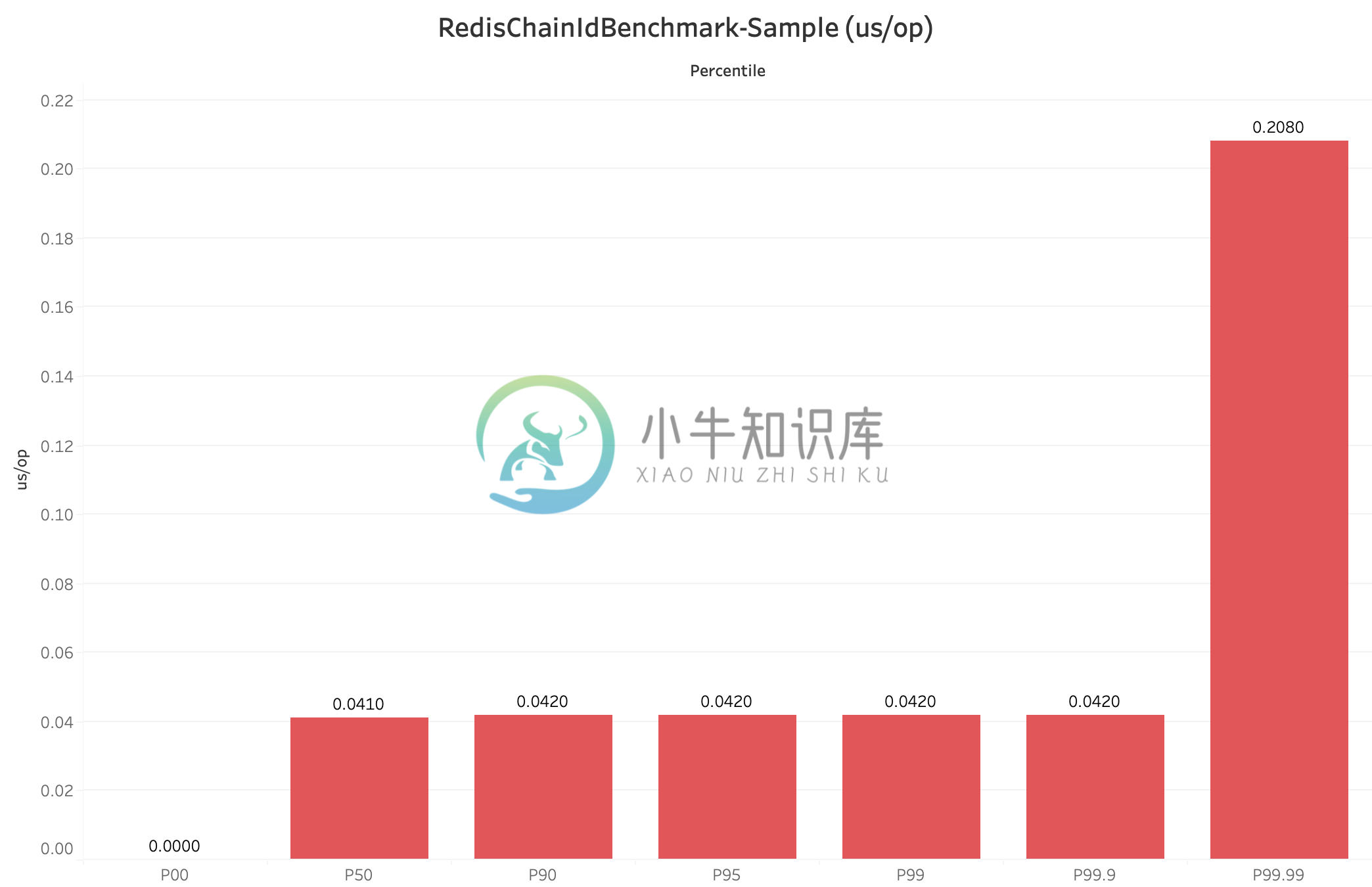
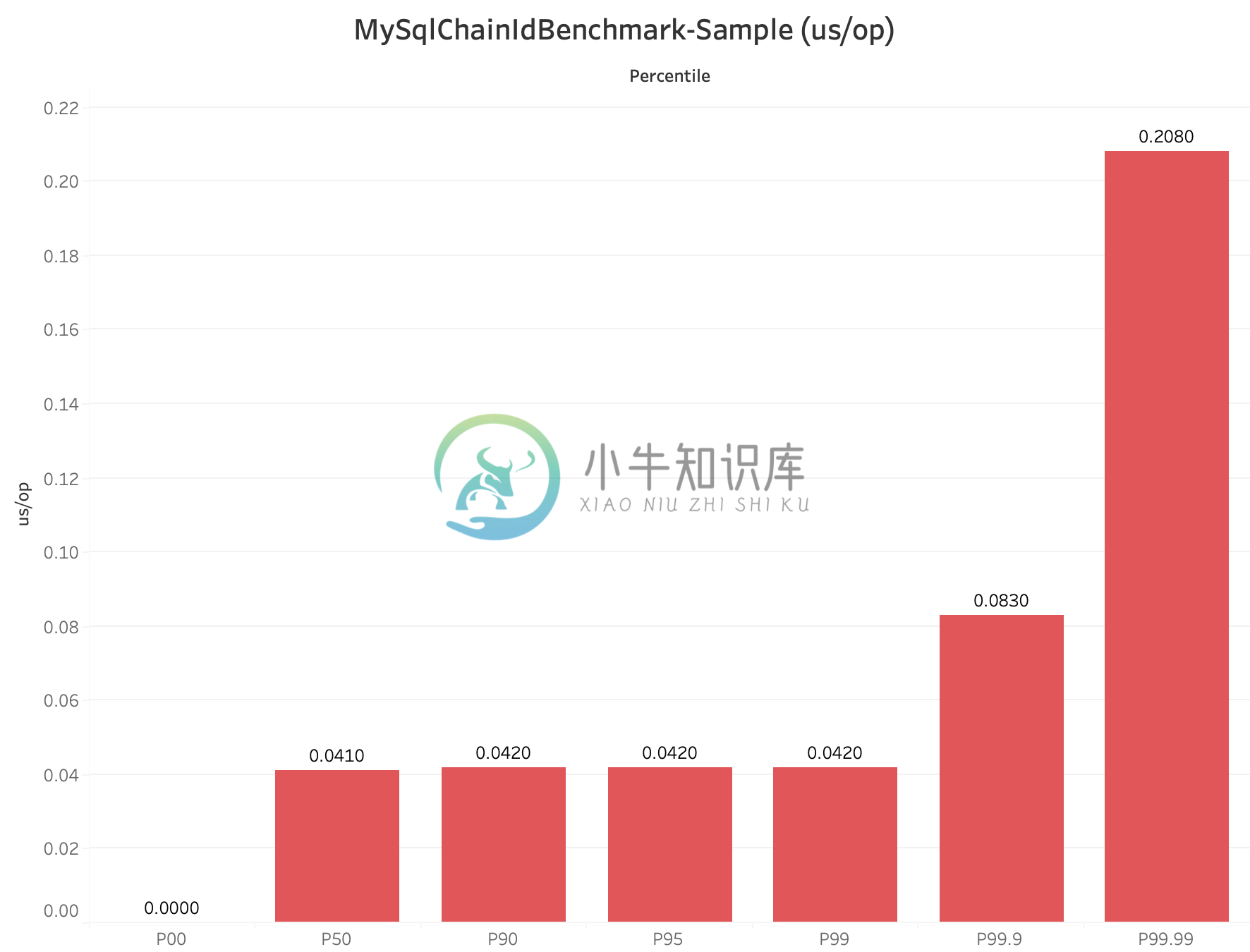
- 稳定性(time/op):稳定性指标一般可以采用每个操作的时间进行百分位采样来分析,比如 CosId 百分位采样 P9999=0.208 us/op,即 0% ~ 99.99% 的单位操作时间小于等于 0.208 us/op。
- 百分位数 WIKI :统计学术语,若将一组数据从小到大排序,并计算相应的累计百分点,则某百分点所对应数据的值,就称为这百分点的百分位数,以Pk表示第k百分位数。百分位数是用来比较个体在群体中的相对地位量数。
- 为什么不用平均每个操作的时间:马老师的身价跟你的身价能平均么?平均后的值有意义不?
- 可以使用最小每个操作的时间、最大每个操作的时间作为参考吗?因为最小、最大值只说明了零界点的情况,虽说可以作为稳定性的参考,但依然不够全面。而且百分位数已经覆盖了这俩个指标。
- 自治性(依赖):主要是指对外部环境有无依赖,比如号段模式会强依赖第三方存储中间件来获取
NexMaxId。自治性还会对可用性造成影响。 - 可用性:分布式ID的可用性主要会受到自治性影响,比如SnowflakeId会受到时钟回拨影响,导致处于短暂时间的不可用状态。而号段模式会受到第三方发号器(
NexMaxId)的可用性影响。- 可用性 WIKI :在一个给定的时间间隔内,对于一个功能个体来讲,总的可用时间所占的比例。
- MTBF:平均故障间隔
- MDT:平均修复/恢复时间
- Availability=MTBF/(MTBF+MDT)
- 假设MTBF为1年,MDT为1小时,即
Availability=(365*24)/(365*24+1)=0.999885857778792≈99.99%,也就是我们通常所说对可用性4个9。
- 适应性:是指在面对外部环境变化的自适应能力,这里我们主要说的是面对流量突发时动态伸缩分布式ID的性能,
- SegmentChainId可以基于饥饿状态进行安全距离的动态伸缩。
- SnowflakeId常规位分配方案性能恒定409.6W,虽然可以通过调整位分配方案来获得不同的TPS性能,但是位分配方法的变更是破坏性的,一般根据业务场景确定位分配方案后不再变更。
- 存储空间:还是用MySq-InnoDB B+树来举例,普通索引(二级索引)会存储主键值,主键越大占用的内存缓存、磁盘空间也会越大。Page页存储的数据越少,磁盘IO访问的次数会增加。总之在满足业务需求的情况下,尽可能小的存储空间占用在绝大多数场景下都是好的设计原则。
不同分布式ID方案核心指标对比
| 分布式ID | 全局唯一性 | 有序性 | 吞吐量 | 稳定性(1s=1000,000us) | 自治性 | 可用性 | 适应性 | 存储空间 |
|---|---|---|---|---|---|---|---|---|
| UUID/GUID | 是 | 完全无序 | 3078638(ops/s) | P9999=0.325(us/op) | 完全自治 | 100% | 否 | 128-bit |
| SnowflakeId | 是 | 本地单调递增,全局趋势递增(受全局时钟影响) | 4096000(ops/s) | P9999=0.244(us/op) | 依赖时钟 | 时钟回拨会导致短暂不可用 | 否 | 64-bit |
| SegmentId | 是 | 本地单调递增,全局趋势递增(受Step影响) | 29506073(ops/s) | P9999=46.624(us/op) | 依赖第三方号段分发器 | 受号段分发器可用性影响 | 否 | 64-bit |
| SegmentChainId | 是 | 本地单调递增,全局趋势递增(受Step、安全距离影响) | 127439148(ops/s) | P9999=0.208(us/op) | 依赖第三方号段分发器 | 受号段分发器可用性影响,但因安全距离存在,预留ID段,所以高于SegmentId | 是 | 64-bit |
有序性(要想分而治之·二分查找法,必须要维护我)
刚刚我们已经讨论了ID有序性的重要性,所以我们设计ID算法时应该尽可能地让ID是单调递增的,比如像表的自增主键那样。但是很遗憾,因全局时钟、性能等分布式系统问题,我们通常只能选择局部单调递增、全局趋势递增的组合(就像我们在分布式系统中不得不的选择最终一致性那样)以获得多方面的权衡。下面我们来看一下什么是单调递增与趋势递增。
有序性之单调递增
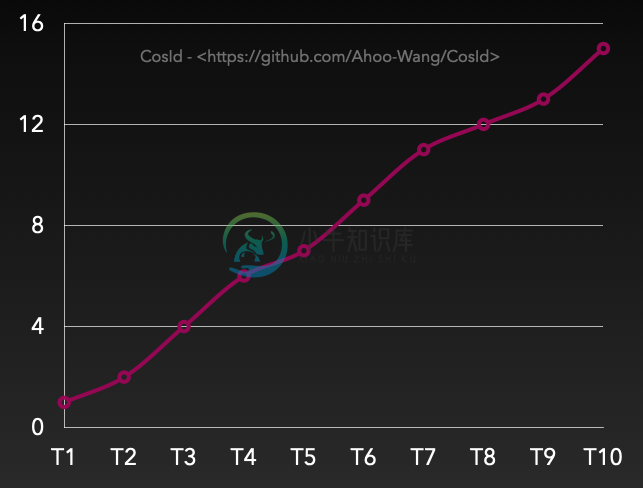
单调递增:T表示全局绝对时点,假设有Tn+1>Tn(绝对时间总是往前进的,这里不考虑相对论、时间机器等),那么必然有F(Tn+1)>F(Tn),数据库自增主键就属于这一类。 另外需要特别说明的是单调递增跟连续性递增是不同的概念。 连续性递增:F(n+1)=(F(n)+step)即下一次获取的ID一定等于当前ID+Step,当Step=1时类似于这样一个序列:1->2->3->4->5。
扩展小知识:数据库的自增主键也不是连续性递增的,相信你一定遇到过这种情况,请思考一下数据库为什么这样设计?
有序性之趋势递增
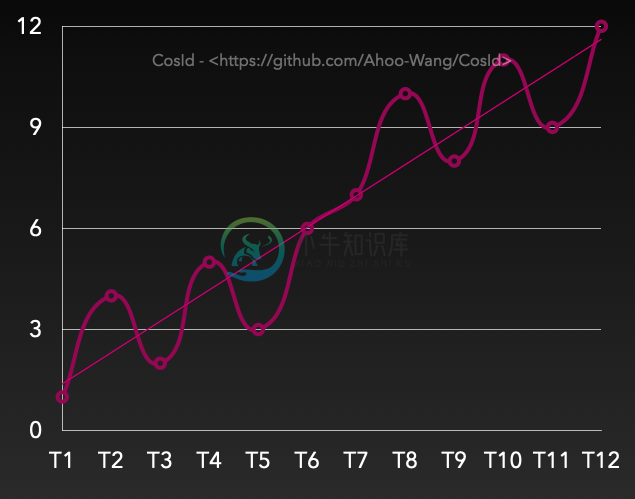
趋势递增:Tn>Tn-s,那么大概率有F(Tn)>F(Tn-s)。虽然在一段时间间隔内有乱序,但是整体趋势是递增。从上图上看,是有上升趋势的(趋势线)。
- 在SnowflakeId中n-s受到全局时钟同步影响。
- 在号段模式(SegmentId)中n-s受到号段可用区间(
Step)影响。
分布式ID分配方案
UUID/GUID
 不依赖任何第三方中间件
不依赖任何第三方中间件 性能高
性能高 完全无序
完全无序 空间占用大,需要占用128位存储空间。
空间占用大,需要占用128位存储空间。
UUID最大的缺陷是随机的、无序的,当用于主键时会导致数据库的主键索引效率低下(为了维护索引树,频繁的索引中间位置插入数据,而不是追加写)。这也是UUID不适用于数据库主键的最为重要的原因。
SnowflakeId

SnowflakeId使用
Long(64-bit)位分区来生成ID的一种分布式ID算法。 通用的位分配方案为:timestamp(41-bit)+machineId(10-bit)+sequence(12-bit)=63-bit。
- 41-bit
timestamp=(1L<<41)/(1000/3600/365),约可以存储69年的时间戳,即可以使用的绝对时间为EPOCH+69年,一般我们需要自定义EPOCH为产品开发时间,另外还可以通过压缩其他区域的分配位数,来增加时间戳位数来延长可用时间。 - 10-bit
machineId=(1L<<10)=1024,即相同业务可以部署1024个副本(在Kubernetes概念里没有主从副本之分,这里直接沿用Kubernetes的定义)。一般情况下没有必要使用这么多位,所以会根据部署规模需要重新定义。 - 12-bit
sequence=(1L<<12)*1000=4096000,即单机每秒可生成约409W的ID,全局同业务集群可产生4096000*1024=419430W=41.9亿(TPS)。
从 SnowflakeId 设计上可以看出:

timestamp在高位,单实例SnowflakeId是会保证时钟总是向前的(校验本机时钟回拨),所以是本机单调递增的。受全局时钟同步/时钟回拨影响SnowflakeId是全局趋势递增的。 SnowflakeId不对任何第三方中间件有强依赖关系,并且性能也非常高。
SnowflakeId不对任何第三方中间件有强依赖关系,并且性能也非常高。 位分配方案可以按照业务系统需要灵活配置,来达到最优使用效果。
位分配方案可以按照业务系统需要灵活配置,来达到最优使用效果。 强依赖本机时钟,潜在的时钟回拨问题会导致ID重复、处于短暂的不可用状态。
强依赖本机时钟,潜在的时钟回拨问题会导致ID重复、处于短暂的不可用状态。
machineId需要手动设置,实际部署时如果采用手动分配machineId,会非常低效。
SnowflakeId之机器号分配问题
在SnowflakeId中根据业务设计的位分配方案确定了基本上就不再有变更了,也很少需要维护。但是machineId总是需要配置的,而且集群中是不能重复的,否则分区原则就会被破坏而导致ID唯一性原则破坏,当集群规模较大时machineId的维护工作是非常繁琐,低效的。
有一点需要特别说明的,SnowflakeId的MachineId是逻辑上的概念,而不是物理概念。 想象一下假设MachineId是物理上的,那么意味着一台机器拥有只能拥有一个MachineId,那会产生什么问题呢?
目前 CosId 提供了以下三种
MachineId分配器。
- ManualMachineIdDistributor: 手动配置
machineId,一般只有在集群规模非常小的时候才有可能使用,不推荐。 - StatefulSetMachineIdDistributor: 使用
Kubernetes的StatefulSet提供的稳定的标识ID(HOSTNAME=service-01)作为机器号。 - RedisMachineIdDistributor: 使用Redis作为机器号的分发存储,同时还会存储
MachineId的上一次时间戳,用于启动时时钟回拨的检查。
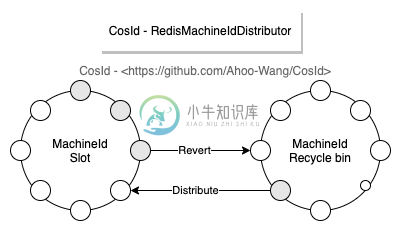
SnowflakeId之时钟回拨问题
时钟回拨的致命问题是会导致ID重复、冲突(这一点不难理解),ID重复显然是不能被容忍的。 在SnowflakeId算法中,按照MachineId分区ID,我们不难理解的是不同MachineId是不可能产生相同ID的。所以我们解决的时钟回拨问题是指当前MachineId的时钟回拨问题,而不是所有集群节点的时钟回拨问题。
MachineId时钟回拨问题大体可以分为俩种情况:
- 运行时时钟回拨:即在运行时获取的当前时间戳比上一次获取的时间戳小。这个场景的时钟回拨是很容易处理的,一般SnowflakeId代码实现时都会存储
lastTimestamp用于运行时时钟回拨的检查,并抛出时钟回拨异常。- 时钟回拨时直接抛出异常是不太好地实践,因为下游使用方几乎没有其他处理方案(噢,我还能怎么办呢,等吧),时钟同步是唯一的选择,当只有一种选择时就不要再让用户选择了。
ClockSyncSnowflakeId是SnowflakeId的包装器,当发生时钟回拨时会使用ClockBackwardsSynchronizer主动等待时钟同步来重新生成ID,提供更加友好的使用体验。
- 启动时时钟回拨:即在启动服务实例时获取的当前时钟比上次关闭服务时小。此时的
lastTimestamp是无法存储在进程内存中的。当获取的外部存储的机器状态大于当前时钟时钟时,会使用ClockBackwardsSynchronizer主动同步时钟。- LocalMachineStateStorage:使用本地文件存储
MachineState(机器号、最近一次时间戳)。因为使用的是本地文件所以只有当实例的部署环境是稳定的,LocalMachineStateStorage才适用。 - RedisMachineIdDistributor:将
MachineState存储在Redis分布式缓存中,这样可以保证总是可以获取到上次服务实例停机时机器状态。
- LocalMachineStateStorage:使用本地文件存储
SnowflakeId之JavaScript数值溢出问题
JavaScript的Number.MAX_SAFE_INTEGER只有53-bit,如果直接将63位的SnowflakeId返回给前端,那么会产生值溢出的情况(所以这里我们应该知道后端传给前端的long值溢出问题,迟早会出现,只不过SnowflakeId出现得更快而已)。 很显然溢出是不能被接受的,一般可以使用以下俩种处理方案:
- 将生成的63-bit
SnowflakeId转换为String类型。- 直接将
long转换成String。 - 使用
SnowflakeFriendlyId将SnowflakeId转换成比较友好的字符串表示:{timestamp}-{machineId}-{sequence} -> 20210623131730192-1-0
- 直接将
- 自定义
SnowflakeId位分配来缩短SnowflakeId的位数(53-bit)使ID提供给前端时不溢出- 使用
SafeJavaScriptSnowflakeId(JavaScript安全的SnowflakeId)
- 使用
号段模式(SegmentId)
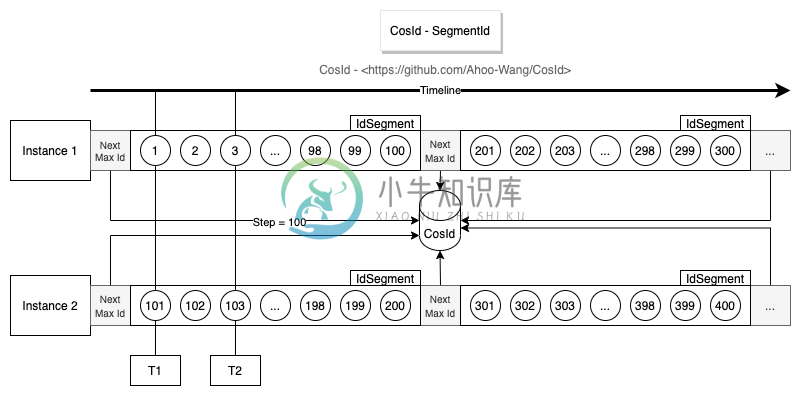
从上面的设计图中,不难看出号段模式基本设计思路是通过每次获取一定长度(Step)的可用ID(Id段/号段),来降低网络IO请求次数,提升性能。
 强依赖第三方号段分发器,可用性受到第三方分发器影响。
强依赖第三方号段分发器,可用性受到第三方分发器影响。 每次号段用完时获取
每次号段用完时获取NextMaxId需要进行网络IO请求,此时的性能会比较低。- 单实例ID单调递增,全局趋势递增。
- 从设计图中不难看出Instance 1每次获取的
NextMaxId,一定比上一次大,意味着下一次的号段一定比上一次大,所以从单实例上来看是单调递增的。 - 多实例各自持有的不同的号段,意味着同一时刻不同实例生成的ID是乱序的,但是整体趋势的递增的,所以全局趋势递增。
- 从设计图中不难看出Instance 1每次获取的
- ID乱序程度受到Step长度以及集群规模影响(从趋势递增图中不难看出)。
- 假设集群中只有一个实例时号段模式就是单调递增的。
Step越小,乱序程度越小。当Step=1时,将无限接近单调递增。需要注意的是这里是无限接近而非等于单调递增,具体原因你可以思考一下这样一个场景:- 号段分发器T1时刻给Instance 1分发了
ID=1,T2时刻给Instance 2分发了ID=2。因为机器性能、网络等原因,Instance 2网络IO写请求先于Instance 1到达。那么这个时候对于数据库来说,ID依然是乱序的。
- 号段分发器T1时刻给Instance 1分发了
号段链模式(SegmentChainId)
分布式ID(CosId)之号段链模式性能(1.2亿/s)解析
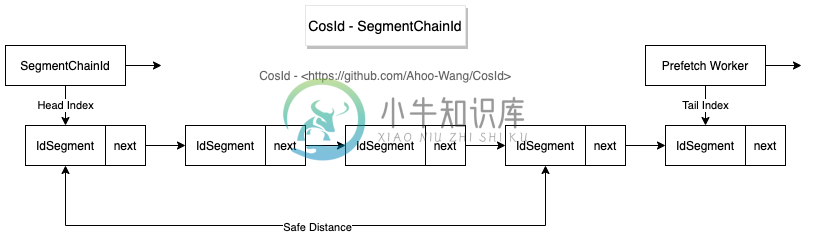
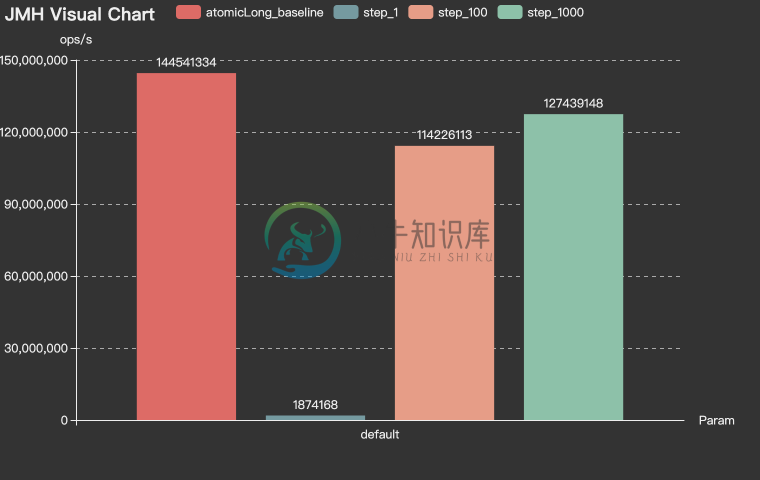
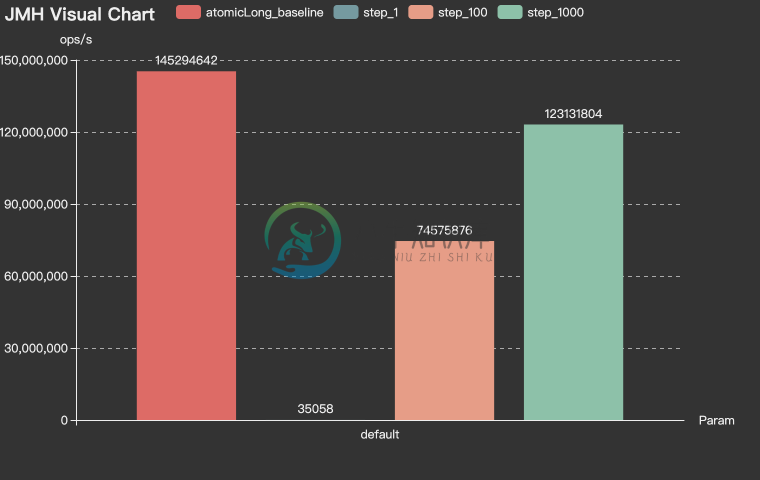
SegmentChainId是SegmentId增强版,相比于SegmentId有以下优势:
- 稳定性:SegmentId的稳定性问题(P9999=46.624(us/op))主要是因为号段用完之后同步进行
NextMaxId的获取导致的(会产生网络IO)。- SegmentChainId (P9999=0.208(us/op))引入了新的角色PrefetchWorker用以维护和保证安全距离,理想情况下使得获取ID的线程几乎完全不需要进行同步的等待
NextMaxId获取,性能可达到近似AtomicLong的 TPS 性能:12743W+/s JMH 基准测试 。
- SegmentChainId (P9999=0.208(us/op))引入了新的角色PrefetchWorker用以维护和保证安全距离,理想情况下使得获取ID的线程几乎完全不需要进行同步的等待
- 适应性:从SegmentId介绍中我们知道了影响ID乱序的因素有俩个:集群规模、
Step大小。集群规模是我们不能控制的,但是Step是可以调节的。Step应该近可能小才能使得ID单调递增的可能性增大。Step太小会影响吞吐量,那么我们如何合理设置Step呢?答案是我们无法准确预估所有时点的吞吐量需求,那么最好的办法是吞吐量需求高时,Step自动增大,吞吐量低时Step自动收缩。- SegmentChainId引入了饥饿状态的概念,PrefetchWorker会根据饥饿状态检测当前安全距离是否需要膨胀或者收缩,以便获得吞吐量与有序性之间的权衡,这便是SegmentChainId的自适应性。
集成
CosIdPlugin(MyBatis 插件)
Kotlin DSL
implementation("me.ahoo.cosid:cosid-mybatis:${cosidVersion}")
public class Order { @CosId(value = "order") private Long orderId; private Long userId; public Long getOrderId() { return orderId; } public void setOrderId(Long orderId) { this.orderId = orderId; } public Long getUserId() { return userId; } public void setUserId(Long userId) { this.userId = userId; } }
ShardingSphere 插件
CosIdKeyGenerateAlgorithm、CosIdModShardingAlgorithm、CosIdIntervalShardingAlgorithm已合并至 ShardingSphere 官方,未来 cosid-shardingsphere 模块的维护可能会以官方为主。
Kotlin DSL
implementation("me.ahoo.cosid:cosid-shardingsphere:${cosidVersion}")
CosIdKeyGenerateAlgorithm (分布式主键)
spring: shardingsphere: rules: sharding: key-generators: cosid: type: COSID props: id-name: __share__
基于间隔的时间范围分片算法
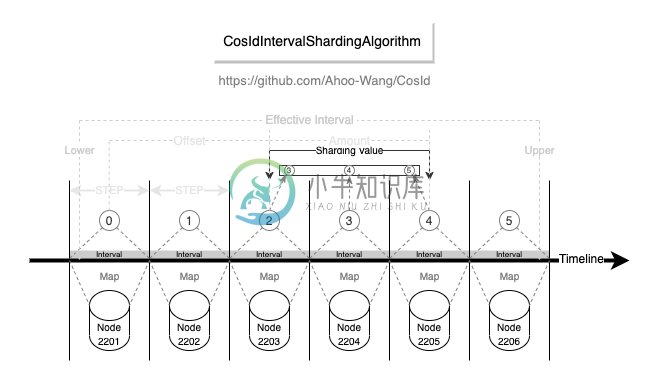
- 易用性: 支持多种数据类型 (
Long/LocalDateTime/DATE/String/SnowflakeId),而官方实现是先转换成字符串再转换成LocalDateTime,转换成功率受时间格式化字符影响。 - 性能 : 相比于
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.IntervalShardingAlgorithm性能高出 1200~4000 倍。
| PreciseShardingValue | RangeShardingValue |
|---|---|
 |
 |
gradle cosid-shardingsphere:jmh
# JMH version: 1.29 # VM version: JDK 11.0.13, OpenJDK 64-Bit Server VM, 11.0.13+8-LTS # VM options: -Dfile.encoding=UTF-8 -Djava.io.tmpdir=/work/CosId/cosid-shardingsphere/build/tmp/jmh -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: full + dont-inline hint # Warmup: 1 iterations, 10 s each # Measurement: 1 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Throughput, ops/time Benchmark (days) Mode Cnt Score Error Units IntervalShardingAlgorithmBenchmark.cosid_precise_local_date_time 10 thrpt 53279788.772 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_local_date_time 100 thrpt 38114729.365 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_local_date_time 1000 thrpt 32714318.129 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_local_date_time 10000 thrpt 22317905.643 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_timestamp 10 thrpt 20028091.211 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_timestamp 100 thrpt 19272744.794 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_timestamp 1000 thrpt 17814417.856 ops/s IntervalShardingAlgorithmBenchmark.cosid_precise_timestamp 10000 thrpt 12384788.025 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_local_date_time 10 thrpt 18716732.080 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_local_date_time 100 thrpt 8436553.492 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_local_date_time 1000 thrpt 1655952.254 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_local_date_time 10000 thrpt 185348.831 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_timestamp 10 thrpt 9410931.643 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_timestamp 100 thrpt 5792861.181 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_timestamp 1000 thrpt 1585344.761 ops/s IntervalShardingAlgorithmBenchmark.cosid_range_timestamp 10000 thrpt 196663.812 ops/s IntervalShardingAlgorithmBenchmark.office_precise_timestamp 10 thrpt 72189.800 ops/s IntervalShardingAlgorithmBenchmark.office_precise_timestamp 100 thrpt 11245.324 ops/s IntervalShardingAlgorithmBenchmark.office_precise_timestamp 1000 thrpt 1339.128 ops/s IntervalShardingAlgorithmBenchmark.office_precise_timestamp 10000 thrpt 113.396 ops/s IntervalShardingAlgorithmBenchmark.office_range_timestamp 10 thrpt 64679.422 ops/s IntervalShardingAlgorithmBenchmark.office_range_timestamp 100 thrpt 4267.860 ops/s IntervalShardingAlgorithmBenchmark.office_range_timestamp 1000 thrpt 227.817 ops/s IntervalShardingAlgorithmBenchmark.office_range_timestamp 10000 thrpt 7.579 ops/s
- SmartIntervalShardingAlgorithm
- type: COSID_INTERVAL
- DateIntervalShardingAlgorithm
- type: COSID_INTERVAL_DATE
- LocalDateTimeIntervalShardingAlgorithm
- type: COSID_INTERVAL_LDT
- TimestampIntervalShardingAlgorithm
- type: COSID_INTERVAL_TS
- TimestampOfSecondIntervalShardingAlgorithm
- type: COSID_INTERVAL_TS_SECOND
- SnowflakeIntervalShardingAlgorithm
- type: COSID_INTERVAL_SNOWFLAKE
spring: shardingsphere: rules: sharding: sharding-algorithms: alg-name: type: COSID_INTERVAL_{type_suffix} props: logic-name-prefix: logic-name-prefix id-name: cosid-name datetime-lower: 2021-12-08 22:00:00 datetime-upper: 2022-12-01 00:00:00 sharding-suffix-pattern: yyyyMM datetime-interval-unit: MONTHS datetime-interval-amount: 1
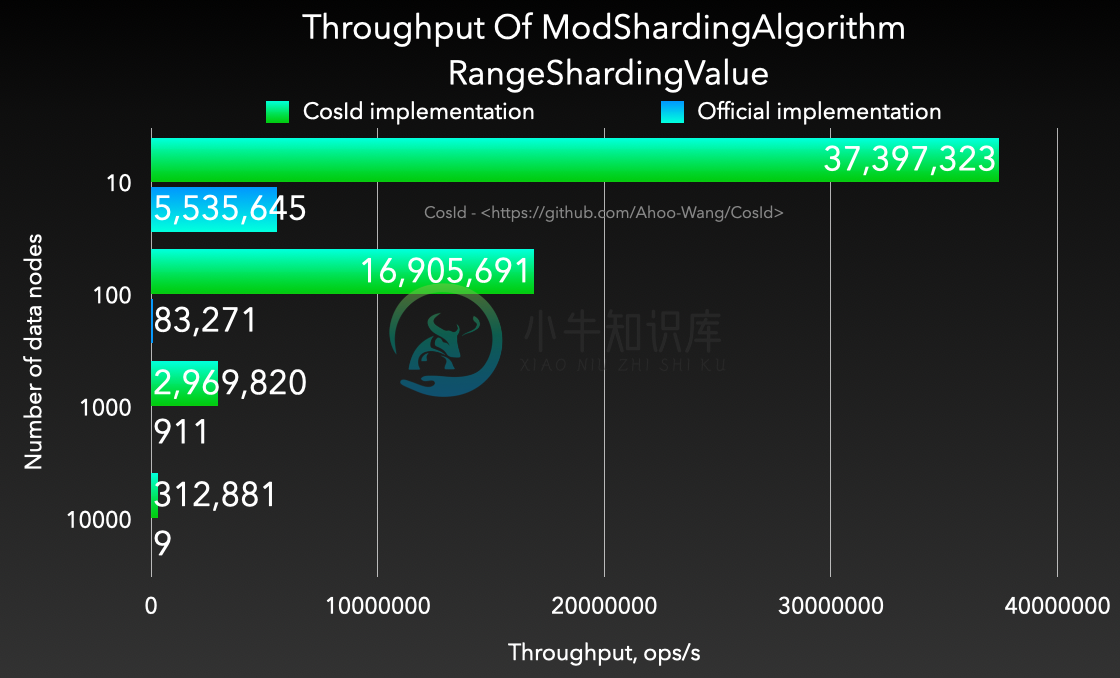
取模分片算法
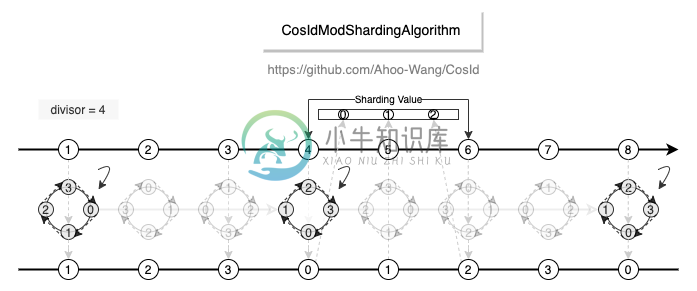
- 性能 : 相比于
org.apache.shardingsphere.sharding.algorithm.sharding.mod.ModShardingAlgorithm性能高出 1200~4000 倍。并且稳定性更高,不会出现严重的性能退化。
| PreciseShardingValue | RangeShardingValue |
|---|---|
 |
 |
gradle cosid-shardingsphere:jmh
# JMH version: 1.29 # VM version: JDK 11.0.13, OpenJDK 64-Bit Server VM, 11.0.13+8-LTS # VM options: -Dfile.encoding=UTF-8 -Djava.io.tmpdir=/work/CosId/cosid-shardingsphere/build/tmp/jmh -Duser.country=CN -Duser.language=zh -Duser.variant # Blackhole mode: full + dont-inline hint # Warmup: 1 iterations, 10 s each # Measurement: 1 iterations, 10 s each # Timeout: 10 min per iteration # Threads: 1 thread, will synchronize iterations # Benchmark mode: Throughput, ops/time Benchmark (divisor) Mode Cnt Score Error Units ModShardingAlgorithmBenchmark.cosid_precise 10 thrpt 121431137.111 ops/s ModShardingAlgorithmBenchmark.cosid_precise 100 thrpt 119947284.141 ops/s ModShardingAlgorithmBenchmark.cosid_precise 1000 thrpt 113095657.321 ops/s ModShardingAlgorithmBenchmark.cosid_precise 10000 thrpt 108435323.537 ops/s ModShardingAlgorithmBenchmark.cosid_precise 100000 thrpt 84657505.579 ops/s ModShardingAlgorithmBenchmark.cosid_range 10 thrpt 37397323.508 ops/s ModShardingAlgorithmBenchmark.cosid_range 100 thrpt 16905691.783 ops/s ModShardingAlgorithmBenchmark.cosid_range 1000 thrpt 2969820.981 ops/s ModShardingAlgorithmBenchmark.cosid_range 10000 thrpt 312881.488 ops/s ModShardingAlgorithmBenchmark.cosid_range 100000 thrpt 31581.396 ops/s ModShardingAlgorithmBenchmark.office_precise 10 thrpt 9135460.160 ops/s ModShardingAlgorithmBenchmark.office_precise 100 thrpt 1356582.418 ops/s ModShardingAlgorithmBenchmark.office_precise 1000 thrpt 104500.125 ops/s ModShardingAlgorithmBenchmark.office_precise 10000 thrpt 8619.933 ops/s ModShardingAlgorithmBenchmark.office_precise 100000 thrpt 629.353 ops/s ModShardingAlgorithmBenchmark.office_range 10 thrpt 5535645.737 ops/s ModShardingAlgorithmBenchmark.office_range 100 thrpt 83271.925 ops/s ModShardingAlgorithmBenchmark.office_range 1000 thrpt 911.534 ops/s ModShardingAlgorithmBenchmark.office_range 10000 thrpt 9.133 ops/s ModShardingAlgorithmBenchmark.office_range 100000 thrpt 0.208 ops/s
spring: shardingsphere: rules: sharding: sharding-algorithms: alg-name: type: COSID_MOD props: mod: 4 logic-name-prefix: t_table_
性能测试报告
SegmentChainId-吞吐量 (ops/s)
RedisChainIdBenchmark-Throughput
MySqlChainIdBenchmark-Throughput
SegmentChainId-每次操作耗时的百分位数(us/op)
RedisChainIdBenchmark-Percentile
MySqlChainIdBenchmark-Percentile
基准测试报告运行环境说明
- 基准测试运行环境:笔记本开发机(MacBook-Pro-(M1))
- 所有基准测试都在开发笔记本上执行。
-
主要内容:1.UUID,2.数据库自增Id,3.基于数据库集群模式,4.基于数据库的号段模式,5.Redis,6.Snowflake,7.百度(uid-generator),8.Leaf,9.TinyId生成方式: 1.UUID 2.数据库自增ID 3.数据库多主模式 4.号段模式 5.Redis 6.雪花算法(SnowFlake) 7.滴滴出品(TinyID) 8.百度 (Uidgenerator) 9.美团(Leaf) 1.UUID UUID的生成简单到只有一行代码,输出结果 c2b8c2b
-
有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id。以支持业务中的高并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。 在插入数据库之前,我们需要给这些消息、订单先打上一个ID,然后再插入到我们的数据库。对这个id的要求是希望其中能带有一些时间信息,这样即使我
-
如何自定义生成固定长度的字符串ID,8-12个字符 格式:业务标记_xxxxxxxxxx 如:user_Nuxq23s24dxa1ScSx 要求:1ms生成100W个 或有什么现成的库可以使用,麻烦老大们贴下代码
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
万法皆空,因果不空。 随着摩尔定律碰到瓶颈,越来越多的系统要依靠分布式集群架构来实现海量数据处理和可扩展计算能力。 区块链首先是一个分布式系统。 中央式结构改成分布式系统,碰到的第一个问题就是一致性的保障。 很显然,如果一个分布式集群无法保证处理结果一致的话,那任何建立于其上的业务系统都无法正常工作。 本章将介绍分布式系统中一些核心问题的来源以及相关的工作。
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,