
Tianshou(天授)是纯基于 PyTorch 的强化学习平台,与现有的主要基于 TensorFlow 的强化学习库不同,Tianshou 没有繁杂的嵌套类、不友好的 API 和速度较慢的代码,其提供了用于构建深度强化学习代理的快速框架和 pythonic API。
支持的接口算法包括:
-
Double DQN (DDQN) with n-step returns
Tianshou 还支持所有算法并行,所有算法都重新格式化为基于重放缓冲(replay-buffer)模式。
特性:
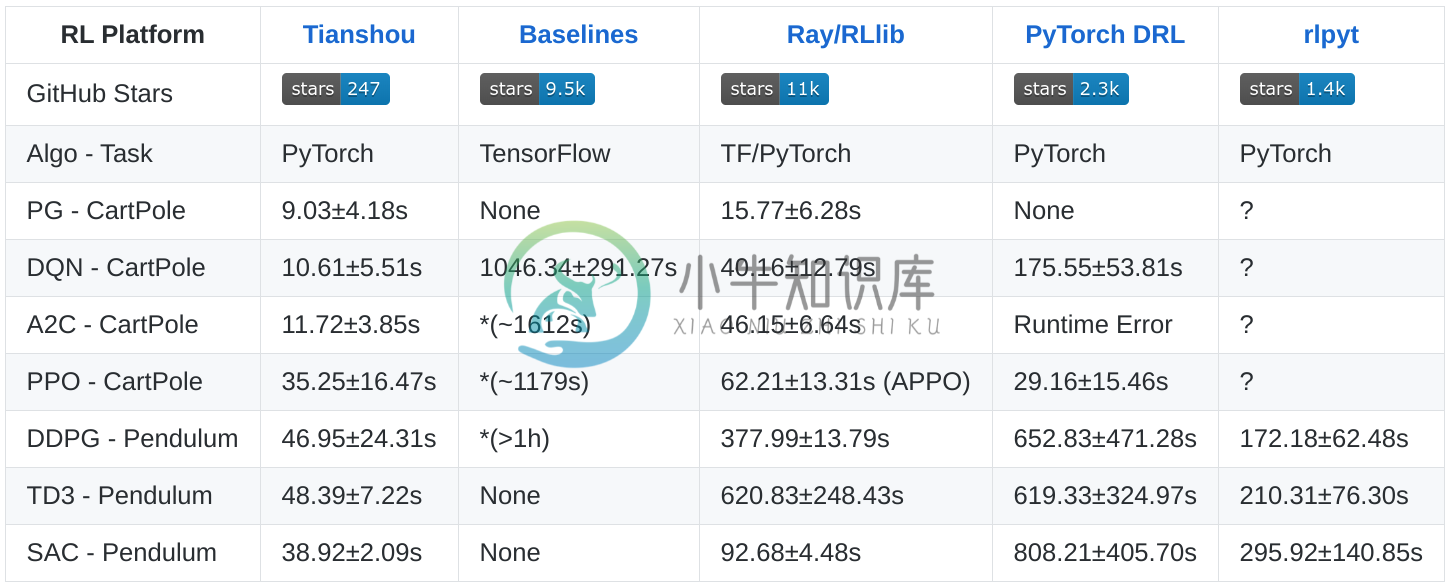
- 快速:使用 laptop(i7-8750H + GTX1060)测试为例,CartPole-v0 任务中,Tianshou 仅需要 3 秒钟即可根据 vanilla 策略梯度来训练代理:python3 test/discrete/test_pg.py --seed 0 --render 0.03
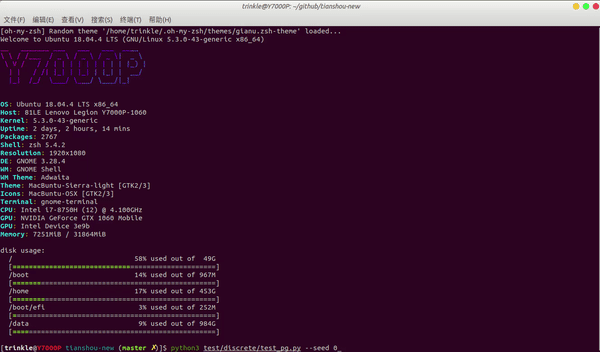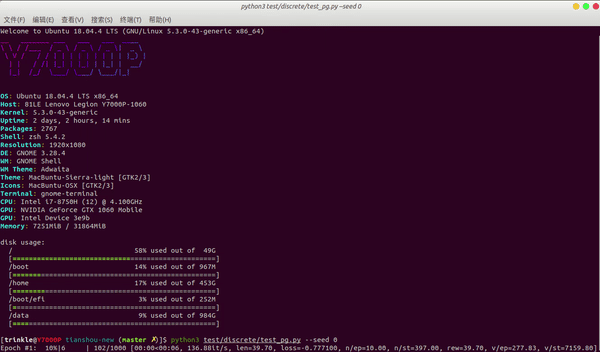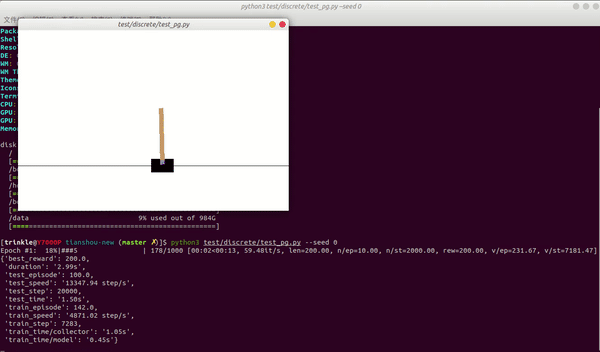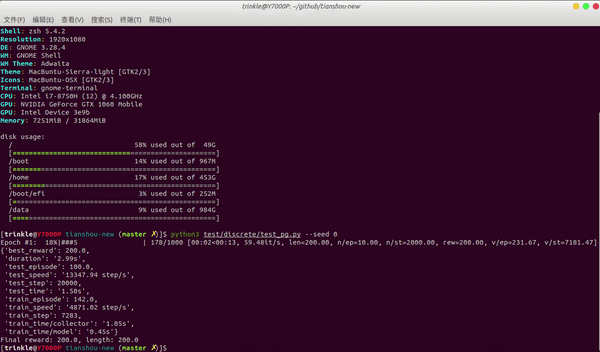
性能对比:
- 可重复性:具有单元测试,并且单元测试覆盖针对所有已实现算法的完整代理培训过程。单元测试确保了平台的可重复性
- 模块化:所有算法分解为 4 部分:
__init__:初始化process_fn:从重放缓冲区预处理数据(所有算法都重构为基于重放缓冲的算法)__call__:根据给定的观察值计算操作learn:从给定的批处理数据中学习
- 优雅灵活:整体代码不到 1500 行,大多数已实现的算法少于 100 行 Python 代码。可以根据需要提供许多灵活的 API。
-
强化学习库tianshou——DQN使用 tianshou是清华大学学生开源编写的强化学习库。本人因为一些比赛的原因,有使用到强化学习,但是因为过于紧张与没有尝试快速复现强化学习的代码,并没有获得很好的成绩,故尝试用库进行快速复现。 之前也尝试了parl等库,感觉parl在文档等方面似乎并不如tianshou,性能上作为菜鸟不好评价。tianshou的官方文档也有很久没有更新了,上面有些代码不能运
-
ImportError DLL load failed while importing defs: 找不到指定的程序 网上搜索这个问题,很多是卸载包再重新安装,反复卸载安装tianshou无果。在terminal运行后,才知道问题出在h5py。 解决方法: 解决H5py的DLL问题:from . import h5 as _h5_奥特曼丶毕健旗的博客-CSDN博客
-
安装tianshou 上https://github.com/thu-ml/tianshou,下面有安装的教程。 pip install tianshou 或者 conda install tianshou -c conda-forge 运行例程,可能会出现缺少cv2的错误 就继续安装,就行 pip install opencv-python 然后继续运行代码,还可能会出现gym出错,照着p
-
我正在读一本书,Glenn Seemann和David M Bourg的“游戏开发人员的AI”,他们使用视频游戏AI作为基于规则的学习系统的示例。 基本上,玩家有3个可能的移动,并以三次打击的组合命中。人工智能旨在预测玩家的第三次打击。系统的规则是所有可能的三步组合。每个规则都有一个关联的“权重”。每次系统猜错,规则的权重就会降低。当系统必须选择规则时,它会选择权重最高的规则。 这与基于强化学习的
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
本文向大家介绍关于机器学习中的强化学习,什么是Q学习?,包括了关于机器学习中的强化学习,什么是Q学习?的使用技巧和注意事项,需要的朋友参考一下 Q学习是一种强化学习算法,其中包含一个“代理”,它采取达到最佳解决方案所需的行动。 强化学习是“半监督”机器学习算法的一部分。将输入数据集提供给强化学习算法时,它会从此类数据集学习,否则会从其经验和环境中学习。 当“强化代理人”执行某项操作时,将根据其是否
-
探索和利用。马尔科夫决策过程。Q 学习,策略学习和深度强化学习。 我刚刚吃了一些巧克力来完成最后这部分。 在监督学习中,训练数据带有来自神一般的“监督者”的答案。如果生活可以这样,该多好! 在强化学习(RL)中,没有这种答案,但是你的强化学习智能体仍然可以决定如何执行它的任务。在缺少现有训练数据的情况下,智能体从经验中学习。在它尝试任务的时候,它通过尝试和错误收集训练样本(这个动作非常好,或者非常
-
强化学习(RL)如今是机器学习的一大令人激动的领域,也是最老的领域之一。自从 1950 年被发明出来后,它被用于一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和机器控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,在多数游戏中,比人类玩的还好,它仅