
Gubernator 作为微服务的主要特性是,它为进入系统的许多请求创建了一个同步点。在几微秒内接收到的请求可以被优化并协调成批,从而减少服务在重载下使用的总带宽和往返延迟。多个服务都运行在单个主机上,并且所有服务都在各自的进程中运行相同的库,但它们没有此功能。
Gubernator 的特性
- Gubernator 在整个集群中均匀地分布速率限制请求,这样用户就可以添加更多的节点来扩展系统。
- Gubernator 不依赖于 Memcache 或 Redis 等外部缓存,因此部署时不存在服务依赖。这使得在诸如 kubernetes 或 nomad 的编排系统中能动态增长或缩小集群。
- Gubernator 在磁盘上不保存状态,它的配置是由客户机根据每个请求传递给它的。
- Gubernator 提供了对其 API 的 GRPC 和 HTTP 访问。可以根据需要限制速率的陪伴服务运行,也可以作为独立的服务运行。
- 可以用作库来实现特定领域的限速服务。
- 支持对高吞吐量环境进行定制化的一致速率限制服务。
- Gubernator 是 俄语中 governor 的英文发音 ,听起来也很酷。
示例配置:
rate_limits:
# Scopes the request to a specific rate limit
- name: requests_per_sec
# A unique_key that identifies this instance of a rate limit request
unique_key: account_id=123|source_ip=172.0.0.1
# The number of hits we are requesting
hits: 1
# The total number of requests allowed for this rate limit
limit: 100
# The duration of the rate limit in milliseconds
duration: 1000
# The algorithm used to calculate the rate limit
# 0 = Token Bucket
# 1 = Leaky Bucket
algorithm: 0
# The behavior of the rate limit in gubernator.
# 0 = BATCHING (Enables batching of requests to peers)
# 1 = NO_BATCHING (Disables batching)
# 2 = GLOBAL (Enable global caching for this rate limit)Gubernator 是无状态的,因为它不需要磁盘空间来操作。不需要任何配置或缓存数据同步到磁盘,这是因为对 Gubernator 的每个请求都包含速率限制的配置。
首先,你可能认为这对每个请求都是不必要的开销。然而,实际上,速率限制配置仅由 4 个 64 位整数组成。配置由限制、持续时间、算法和行为组成 (有关工作原理的详细信息,请参阅下面)。正是由于这种简单的配置,Gubernator 可以用来提供客户端可以使用的各种速率限制用例。其中一些用例如下:
- 入口限制:典型的基于 HTTP 的 402 多请求类型限制。
- 流量减少:当 API 处于不佳状态时,只拒绝新的或未经身份验证的请求。
- 出口限制:用数百万条消息轰炸外部 SMTP 服务器并非易事。
- 队列处理:知道何时可以立即处理请求,或者应该按照接收请求的顺序排队和处理请求。
- API 容量管理:对一个集合 API 系统能够处理的请求总数设置全局限制。拒绝或对违反系统正常操作能力的请求进行排队。
除了上面提到的用例,无配置设计对微服务的设计和部署有重要的影响:
- 部署时不用配置同步。当使用 Gubernator 的服务被部署时,不用预先部署到 Gubernator 的速率限制配置。
- 使用 Gubernator 的服务拥有其问题空间的速率极限域模型。这使得 Gubernator 无法获得领域特定的知识,因此 Gubernator 可以专注于它最擅长的事情——速率限制!
在这些问题之外,下面就从 Gubernator 的工作原理开始,讨论更多关于 Gubernator 的内容。
Gubernator 的工作原理
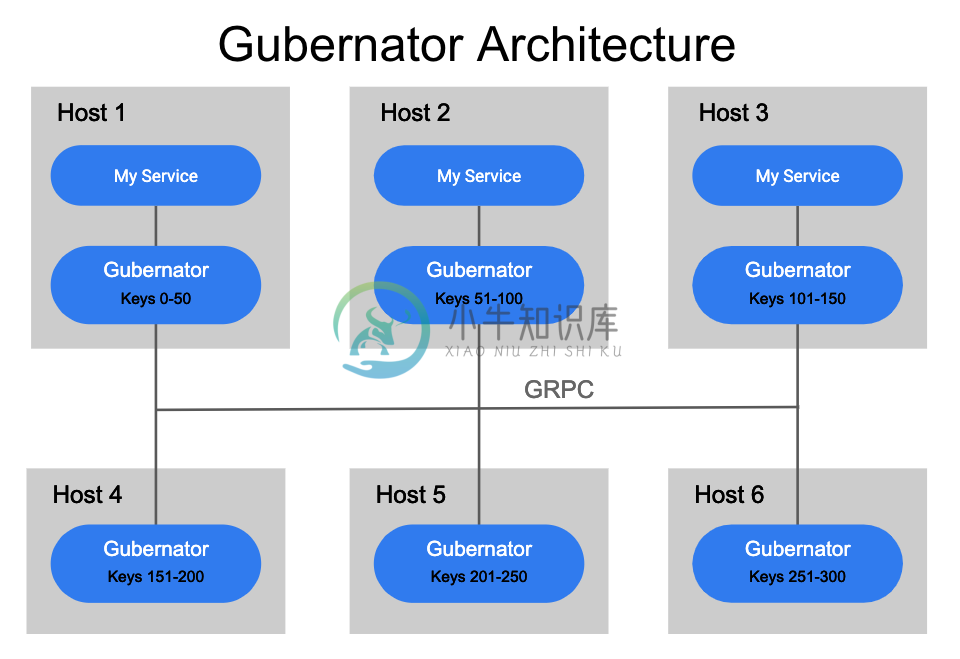
Gubernator 被设计成一个分布式的对等点集群,它利用了内存中所有当前活动速率限制的缓存,因为不用将数据同步到磁盘。由于大多数基于网络的速率限制持续时间只有几秒钟,因此在重启或计划停机期间丢失内存缓存并不是什么大问题。对于 Gubernator,我们选择性能而不是精度,因为在缓存丢失的情况下,一小部分流量在短时间内 (通常是几秒钟) 超过请求是可以接受的。
当向 Gubernator 发出速率限制请求时,将键入该请求并应用一致的哈希算法来确定哪个对等点将是速率限制请求的所有者。为速率限制选择单个所有者可以使计数的原子增量非常快,并且避免了在对等集群中一致地分布计数所涉及的复杂性和延迟。
尽管简单且性能良好,但是这种设计可能会受到一大堆请求的影响,因为一个协调器可能要处理成千上万个请求,而且速度有限。
为了解决这个问题,客户机可以请求 Behaviour=BATCHING,它允许对等点在指定的窗口内接受多个请求 (缺省值为 500 微秒),并将请求批处理为单个对等点请求,从而极大地减少了通过网络向单个 Gubernator 对等点发送请求的总数。
为了确保集群中的每个对等点准确地计算速率限制键的正确散列,必须以及时和一致的方式将集群中的对等点列表分发给集群中的每个对等点。目前,Gubernator 支持使用 etcd 或 kubernetes 端点 API 来发现 Gubernator 对等点。
Gubernator 操作
当客户机或服务向 Gubernator 发出请求时,客户机将为每个请求提供速率限制配置。然后,速率限制配置与当前速率限制状态一起存储在速率限制所有者的本地缓存中。存储在本地缓存中的速率限制及其配置仅在速率限制配置的指定持续时间内存在。
在持续时间过期之后,如果在此期间没有再次请求速率限制,则从缓存中删除它。对相同名称和 unique_key 对的后续请求将在缓存中重新创建配置和速率限制,这个循环将重复。另一方面,具有不同配置的后续请求将覆盖以前的配置并立即应用新配置。
由于 Gubernator 速率限制是由集群中的单个对等点哈希和处理的,所以适用于数据中心中的每个请求的速率限制将导致单个对等点处理整个数据中心的速率限制请求。
例如,考虑 name=requests_per_datacenter 和 unique_id=us-east-1 的速率限制。现在,假设对每个进入 us-east-1 数据中心的 HTTP 请求都使用这个速率限制向 Gubernator 发出请求。这可能是每秒数十万个请求,甚至可能是数百万个请求,这些请求都由集群中的一个对等点哈希并处理。由于这个潜在的可伸缩性问题,Gubernator 引入了一个名为 GLOBAL 的可配置 behavior。
当速率限制配置为 behavior=GLOBAL 时,从客户机接收到的速率限制请求将不会转发给拥有它的对等方。相反,它将从接收请求的对等方处理的内部缓存中得到响应。Hits 速率限制的点击率将由接收对等点批量处理,并异步发送到拥有该点击率的对等点,在该对等点上,点击率将被总计并得出 OVER_LIMIT。然后,拥有节点的节点有责任用速率限制的当前状态更新集群中的每个节点,这样,节点内部缓存就会定期从所有者那里获得最新速率限制状态的更新。
Global Behavior 的其他影响
由于 Hits 是批量处理并异步转发给拥有它的对等点的,所以对客户机的即时响应将不包括最精确的 remaining 计数。只有在对所有者对等点的异步调用完成并且拥有对等点有时间更新集群中的所有对等点之后,该计数才会得到更新。因此,使用 GLOBAL 允许更大的集群规模,但要以一致性为代价。如果集群足够大,使用 GLOBAL 可以增加每速率限制请求的通信量。 GLOBAL 应该只用于与传统的非 GLOBAL 行为不兼容的高容量速率限制。
Gubernator 性能
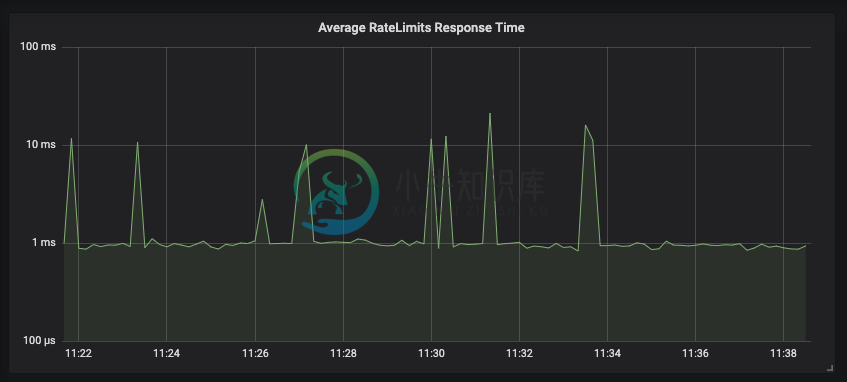
在我们的生产环境中,每向我们的 API 发送一个请求,我们就向 Gubernator 发送两个速率限制请求来评估速率限制;一个用于对 HTTP 请求进行评级,另一个用于对用户在特定时间内也可以发送电子邮件的收件人数量进行评级。在这种设置下,一个 Gubernator 节点每秒处理超过 2000 个请求,大多数批量响应在 1 毫秒内返回。
转发给拥有节点的对等请求通常在 30 微秒内响应。
- NOTE
- The
- above
- graphs
- only report
- the slowest
- request
- within the
- 1 second
- sample
- time. So
- you are
- seeing the
- slowest
- requests
- that
- Gubernator
- fields to
- clients.
由于许多面向公众的 API 都是用 python 编写的,所以我们在一个节点上运行许多 python 解释器实例。这些 python 实例将本地请求转发给 Gubernator 实例,然后 Gubernator 实例将请求批处理并转发给拥有节点的节点。
Gubernator 允许用户选择非批处理行为,这将进一步减少客户机速率限制请求的延迟。但是,由于吞吐量需求,我们的生产环境使用默认的 500 微秒窗口使用 Behaviour=BATCHING。在生产中,我们观察到在 API 使用高峰期间,批处理大小为 1000。其他不具有相同高流量需求的用户可以禁用批处理,并以吞吐量为代价降低延迟。
Gubernator 开发库
如果使用 Golang,可以使用 Gubernator 作为开发库。这对你希望在顶部实现一个公司特有模型的速率限制服务时非常有用。我们在 Mailgun 内部有一项名为“ratelimits”的服务,专门跟踪每个账户的限额。通过这种方式,你可以利用 Gubernator 的强大功能和速度,同时可以分层业务逻辑,并将特定领域的问题集成到速率限制服务中。
性能表现:
下面是一个单节点每秒 2000 个请求的测试结果:
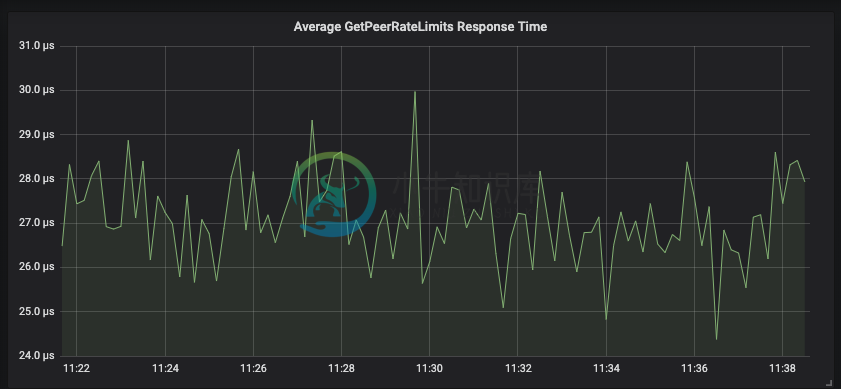
转发给拥有节点的对等请求通常在30微秒内响应
-
Gubernator 是一个分布式,高性能,云原生和无状态的速率限制服务。 关键特性 Gubernator 可以把请求的速率平均限制到整个集群,这意味着,您可以简单的通过增加更多的节点平滑的扩展系统服务能力。 Gubernator不依赖于外部的缓存,如MemCache或者Redis这样的软件,也不依赖于其他的服务,这意味着本服务可以动态的增加服务能力。 Gubernator保持磁盘的无状态能力,基
-
我有两个微服务和调用来更新数据,然后插入另一个数据,但让我们考虑一下 失败,然后我们需要回滚由 更新的数据,否则我们将处于不一致的状态。 我也经历了佐贺patterns.will它满足了这种矛盾 谁能为此提出更好的解决方案?
-
最近在学微服务的分布式事务,不太明白为什么在微服务这种分布式系统中,原有的单体acid会出现问题 希望大佬们可以讲一下原理和思想
-
imi v1.0.13 版本新增了一个 Swoole\Coroutine\Http\Server 实现的协程服务器。需要 Swoole 4.4+ 才可使用该特性。 该特性是可选的,不影响以前使用的服务器模式。 使用协程服务器特性,依靠 Linux 系统的端口重用机制,系统级的负载均衡,可以让你的多进程 Http 服务处理请求的能力得到提升。 使用 ab,本机->虚拟机(双核+2进程)压测Hello
-
我知道最好使用 Saga 模式,但想想还是很有趣的: < Li > 2PC/XA分布式事务是否提供了仅从一个应用程序和一个TM与多个RM进行事务的可能性? < li >如果没有-如果每个微服务只能访问自己的数据库,如何在多个微服务之间使用2PC/XA分布式事务来提供使用2PC的能力?我很乐意看到一个例子 < li >我们是否需要将TransactionManager服务作为一个独立的微服务,在多个
-
问题内容: 您将使用哪种分布式锁定服务? 要求是: 可以从不同的进程/机器看到的互斥(锁定) 锁定…释放语义 超时后自动释放锁-如果锁持有人死亡,它将在X秒后自动释放 Java实现 很高兴拥有:.Net实现 如果免费:死锁检测/缓解 易于部署,请参阅下面的注释。 我对诸如“可以通过数据库完成”或“可以通过JavaSpaces完成”之类的答案不感兴趣-我知道。我对现成的,现成的,经过验证的实现感兴趣
-
链接 Web API Controllers 动态WebApi层 集成OData 集成Swagger UI ASPNET Core 集成OData