
IndexR 是一个专注于大数据实时分析的分布式列式数据库,它基于HDFS,能快速分析海量结构化数据,支持实时导入并且查询秒级延迟,特别适合ad-hoc场景下的OLAP查询。
IndexR 具体实现参考并使用了众多优秀的开源项目,比如 Infobright,Hbase,Druid,Drill 等,与 Hadoop 生态圈深度结合。目前它主要通过作为 Apache Hive 和 Apache Drill 的插件来使用。
IndexR 是由广州舜飞信息科技有限公司开发。
-
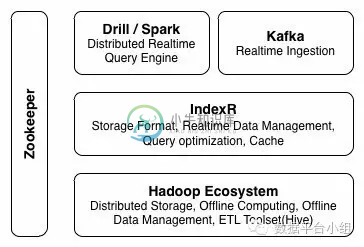
1 Index R 的前世今生 IndexR是由舜飞科技研发的实时OLAP系统。于 2017 年 1 月初正式开源,目前已经更新至 0.6.1 版本,其作者认为IndexR具有以下特点: 超大数据集,低查询延时(超大数据集由HDFS保证,查询低延迟由MPP架构的Drill和IndexR专门设计的存储格式保证) 准实时 (和Druid实时摄入的思路类似,从Kafka实时摄入数据) 高可用,易扩展(架
-
计算COX模型的C-index 两个COX模型的比较 PART1 计算COX的C-index 方法1:基于cox直接生成系数以及计算的C-index值 library("survminer") library("survival") ######### 生成COX模型 cox_model <- coxph() # 直接查看coxph summary(cox_model) # call之后: Co
-
抽样方法 常见的抽样方法 简单随机抽样 分层抽样 系统抽样 # 导入数据 # 1 金融 2 建筑 3 外语 data <- read.csv("E:\\Github\\code-learning\\R\\data\\第11期资料\\data.csv") # 按照专业和ID排序 data <- data[order(data$专业,data$ID),] head(data) 专业 ID 收入
-
PAD_INDEX选项是设置创建索引期间中间级别页中可用空间的百分比。 对于非叶级索引页需要使用PAD_INDEX选项设置其预留空间的大小。PAD_INDEX选项只有在指定了FILLFACTOR选项时才有用。因为PAD_INDEX是由FILLTACTOR指定的百分比决定。 SQL语句如下: 创建一个唯一聚集索引 USE database_name create UNIQUE CLUSTERED I
-
R语言临床预测模型的评价指标与验证指标实战:C-index指标计算 目录 R语言临床预测模型的评价指标与验证指标实战:C-index指标计算
-
例如: 将 MsgType/Cxr NoOfMsgs AvgElpsdTime(ms) 161 AM 86 30.13 171 CM 1 104 18 C
-
已知: urls.py中的代码是: from django.contrib import admin from django.urls import path from django import urls from django.conf.urls import url from goods import views urlpatterns = [ url(r'^admin/', ad
-
目的:我只想去掉浏览器地址栏中的index.php?r=这一块。 首先确认apache2配置 1. 开启 apache 的 mod_rewrite 模块 去掉LoadModule rewrite_module modules/mod_rewrite.so前的“#”符号; 2. 修改 apache 的 AllowOverride 把 AllowOverride None 修改为 AllowOverr
-
1.set_index DataFrame可以通过set_index方法,可以设置单索引和复合索引。 DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False) append添加新索引,drop为False,inplace为True时,索引将会还原为列 import nump
-
Most of the time in programming, we need to perform the same operations upon all elements in a vector or perform the same set of actions multiple times. Loop statements in programming are designed for
-
elasticsearch 异常:type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only / allow delete (api)]; 原因是磁盘空间不足85%时,默认值为85%,这意味着Elasticsearch不会将碎片分配给使用了超过85%磁盘的节点。所有会报上述错误。 解决办法: 1. 重
-
在R或者Rstudio运行这行代码 options(repos=‘http://cran.rstudio.com/’)
-
df为1个data.frame对象,有stratum和psu两列,这里统计stratum列计数 方法1: cnt = table(df$stratum) 方法2: cnt = tapply(df$psu, INDEX=df$stratum, FUN=length) 在方法2的基础上,只要改变FUN函数就可以实现分组求和、求均值等功能,如下 分组求均值: tapply(df$psu, INDEX
-
查了一些资料,发现是后端传给前端的数据,前端没有处理好所以报错 问题:因为我要加载一个列表el-table,需要的数据格式如下 // el-table的:data需要的数据格式 [{...},{...},...,{...}] // 后端返回的数据格式,我直接返给了:data,这样明显不对,应该包裹一个[] {...} 基于此,就是处理数据的方式没对 // 比如从后端解构出来一个res对象,只需要
-
原因:使用后台返回的数据直接赋值操作报错;应该使用JSON.parse(JSON.stringify(后台返回数据))转换一下即可。
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
雪花算法 类型:SNOWFLAKE 可配置属性: 属性名称 数据类型 说明 默认值 worker-id (?) long 工作机器唯一标识 0 max-vibration-offset (?) int 最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防
-
一、分布式锁 数据库的唯一索引 Redis 的 SETNX 指令 Redis 的 RedLock 算法 Zookeeper 的有序节点 二、分布式事务 2PC 本地消息表 三、CAP 一致性 可用性 分区容忍性 权衡 四、BASE 基本可用 软状态 最终一致性 五、Paxos 执行过程 约束条件 六、Raft 单个 Candidate 的竞选 多个 Candidate 竞选 数据同步 参考 一、分
-
本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置