
中文词法分析(LAC)
中文分词(Word Segmentation)是将连续的自然语言文本,切分出具有语义合理性和完整性的词汇序列的过程。因为在汉语中,词是承担语义的最基本单位,切词是文本分类、情感分析、信息检索等众多自然语言处理任务的基础。 词性标注(Part-of-speech Tagging)是为自然语言文本中的每一个词汇赋予一个词性的过程,这里的词性包括名词、动词、形容词、副词等等。 命名实体识别(Named Entity Recognition,NER)又称作“专名识别”,是指识别自然语言文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。 我们将这三个任务统一成一个联合任务,称为词法分析任务,基于深度神经网络,利用海量标注语料进行训练,提供了一个端到端的解决方案。
我们把这个联合的中文词法分析解决方案命名为 LAC 。LAC 既可以认为是 Lexical Analysis of Chinese 的首字母缩写,也可以认为是 LAC Analyzes Chinese 的递归缩写。
特别注意:本项目依赖Paddle v0.14.0版本。如果您的Paddle安装版本低于此要求,请按照安装文档中的说明更新Paddle安装版本。
项目结构
. ├── AUTHORS # 贡献者列表 ├── CMakeLists.txt # cmake配置文件 ├── conf # 运行本例所需的模型及字典文件 ├── data # 运行本例所需要的数据依赖 ├── include # 头文件 ├── LICENSE # 许可证信息 ├── python # 训练使用的python文件 ├── README.md # 本文档 ├── src # 源码 ├── technical-report # 技术报告 └── test # Demo程序
引用
如果您的学术工作成果中使用了LAC,请您增加下述引用。我们非常欣慰LAC能够对您的学术工作带来帮助。
@article{jiao2018LAC,
title={Chinese Lexical Analysis with Deep Bi-GRU-CRF Network},
author={Jiao, Zhenyu and Sun, Shuqi and Sun, Ke},
journal={arXiv preprint arXiv:1807.01882},
year={2018},
url={https://arxiv.org/abs/1807.01882}
}
模型
词法分析任务的输入是一个字符串(我们后面使用『句子』来指代它),而输出是句子中的词边界和词性、实体类别。序列标注是词法分析的经典建模方式。我们使用基于GRU的网络结构学习特征,将学习到的特征接入CRF解码层完成序列标注。CRF解码层本质上是将传统CRF中的线性模型换成了非线性神经网络,基于句子级别的似然概率,因而能够更好的解决标记偏置问题。模型要点如下,具体细节请参考python/train.py代码。
输入采用one-hot方式表示,每个字以一个id表示
one-hot序列通过字表,转换为实向量表示的字向量序列;
字向量序列作为双向GRU的输入,学习输入序列的特征表示,得到新的特性表示序列,我们堆叠了两层双向GRU以增加学习能力;
CRF以GRU学习到的特征为输入,以标记序列为监督信号,实现序列标注。
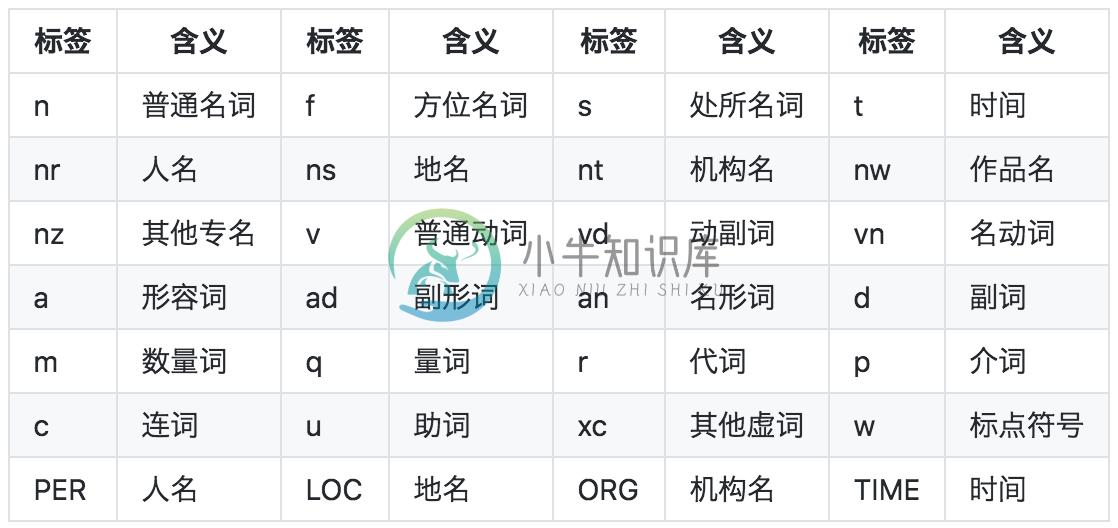
词性和专名类别标签集合如下表,其中词性标签24个(小写字母),专名类别标签4个(大写字母)。这里需要说明的是,人名、地名、机名和时间四个类别,在上表中存在两套标签(PER / LOC / ORG / TIME 和 nr / ns / nt / t),被标注为第二套标签的词,是模型判断为低置信度的人名、地名、机构名和时间词。开发者可以基于这两套标签,在四个类别的准确、召回之间做出自己的权衡。
数据
训练使用的数据可以由用户根据实际的应用场景,自己组织数据。数据由两列组成,以制表符分隔,第一列是utf8编码的中文文本,第二列是对应每个字的标注,以空格分隔。我们采用IOB2标注体系,即以X-B作为类型为X的词的开始,以X-I作为类型为X的词的持续,以O表示不关注的字(实际上,在词性、专名联合标注中,不存在O)。示例如下:
在抗日战争时期,朝鲜族人民先后有十几万人参加抗日战斗 p-B vn-B vn-I n-B n-I n-B n-I w-B nz-B nz-I nz-I n-B n-I d-B d-I v-B m-B m-I m-I n-B v-B v-I vn-B vn-I vn-B vn-I
我们随同代码一并发布了完全版的模型和相关的依赖数据。但是,由于模型的训练数据过于庞大,我们没有发布训练数据,仅在
data目录下的train_data和test_data文件中放置少数样本用以示例输入数据格式。模型依赖数据包括:
输入文本的词典,在
conf目录下,对应word.dic对输入文本中特殊字符进行转换的字典,在
conf目录下,对应q2b.dic标记标签的词典,在
conf目录下,对应tag.dic在训练和预测阶段,我们都需要进行原始数据的预处理,具体处理工作包括:
在训练阶段,这些工作由
python/train.py调用python/reader.py完成;在预测阶段,由C++代码完成。从原始数据文件中抽取出句子和标签,构造句子序列和标签序列
将句子序列中的特殊字符进行转换
依据词典获取词对应的整数索引
-
【收藏】 移动国家号(MCC) 定义 移动国家号(MCC)由三位十进制数组成,它表明移动用户(或系统)归属的国家。 格式 移动国家号(MCC)由三个十进制数组成,编码范围为十进制的000-999 传送 移动国家号用于国际移动用户识别(IMSI)中和位置区识别(LAI)中。 位置区识别(LAI)。位置区识别在每个小区广播的系统消息中周期发送,其中的移动国家号(MCC)表示GSMPLMN所属的国家。移
-
在使用L2TP协议构建的VPDN典型组网中,包含LAC和LNS两部分。 1、LAC LAC表示L2TP访问集中器(L2TP Access Concentrator),是附属在交换网络上的具有PPP端系统和L2TP协议处理能力的设备。LAC一般是一个网络接入服务器NAS,主要用于通过PSTN/ISDN网络为用户提供接入服务。LAC位于LNS和远端系统(远地用户和远地分支机构)之间,用于在LNS和
-
LAC 为位置区域编码,它是唯一识别我国数字 PLMN 中每个位置区的,是一个 2 字节 16 进制的 BCD 码,表示为 L1L2L3L4 范围 0000~FFFF,可定义 65536 个不 同的位置区。 区域就是在系统和网络里由几个基站组成的一个基站组。一个基站所属区域的消 息由系统参数消息里的 REG_ZONE 字段传给移动台。 基于区域登记就是当移动台移动到一个新的小区,而该小区基站所属区
-
对应数据的链接放这里了 import pandas as pd from util.logger import Log import os from util.data_dir import root_dir from LAC import LAC os_file_name = os.path.split(os.path.realpath(__file__))[-1] # 加载LAC模型 la
-
MCC,Mobile Country Code,移动国家代码(中国的为460); MNC,Mobile Network Code,移动网络号码(中国移动为00,中国联通为01); LAC,Location Area Code,位置区域码; CID,Cell Identity,基站编号,是个16位的数据(范围是0到65535)。
-
在使用L2TP协议构建的VPDN典型组网中,包含LAC和LNS两部分。 1、LAC LAC表示L2TP访问集中器(L2TP Access Concentrator),是附属在交换网络上的具有PPP端系统和L2TP协议处理能力的设备。LAC一般是一个网络接入服务器NAS,主要用于通过PSTN/ISDN网络为用户提供接入服务。LAC位于LNS和远端系统(远地用户和远地分支机构)之间,用于在LNS和远端
-
在使用L2TP协议构建的VPDN典型组网中,包含LAC和LNS两部分。 1、LAC LAC表示L2TP访问集中器(L2TP Access Concentrator),是附属在交换网络上的具有PPP端系统和L2TP协议处理能力的设备。LAC一般是一个网络接入服务器NAS,主要用于通过PSTN/ISDN网络为用户提供接入服务。LAC位于LNS和远端系统(远地用户和远地分支机构)之间,用于在
-
先从我们生活中能看到的说起吧: 生活中,我们经常看到一个大铁塔(每一个铁塔下班都有一个机房,用来装其他硬件设备的。例如BTS 基站收发信台 ,及我们通俗说的基站 ),上面固定着几个柱型的棒子,那个是基站的天线 。朝着不同的方向,用来发射和接收手机信号的。一个基站 一般有三个天线装在机房外边较高的空旷区,并朝着不同的方向,每个天线负责120的区域,他们各自负责自己区域的手机信号发射和手机信号
-
目录 为什么要将LAC改造成ES插件? 怎么将LAC改造成ES插件? 确认LAC java接口能work 搭建ES插件开发调试环境 编写插件 生成插件 安装、运行插件 linux版本的动态链接库生成 总结 参考文档 为什么要将LAC改造成ES插件? ES是著名的非关系型文档数据库,开源、近实时、分布式,很多搜索引擎比如github、维基百科等都是以ES为骨架搭建的。我们也想基于ES搭建一套自己的搜
-
To begin with,what is 'LAC' 就是说,在一棵树中,照亮个节点的最近路线 先来一个模板题 题目描述 给定一棵n个点的树,Q个询问,每次询问点x到点y两点之间的距离。 输入格式: 第一行一个正整数n,表示这棵树有n个节点; 接下来n−1行,每行两个整数x,y,表示 x,y之间有一条连边; 然后一个整数Q,表示有Q个询问; 接下来Q行,每行两个整数x,y表示询问x到y的距离。
-
1, A GSM Cell ID (CID) is a generally unique number used to identify each Base transceiver station (BTS) or sector of a BTS within a Location area code (LAC) if not within a GSM network. 2, A "locatio
-
本项目实现基于LAC提供RESTAPI服务的最小化方案。 依赖: python-3.9.9 百度lac2.X fastAPI uvicorn 首先下载并安装python,本人选择3.9版本。 依次安装: 安装 vc++ vc_redist.x64.exe 64位:https://download.microsoft.com/download/9/3/F/93FCF1E7-E6A4-478
-
LAC:location area code 位置区码 位置区码(移动通信系统中),是为寻呼而设置的一个区域,覆盖一片地理区域,初期一般按行政区域划分(一个县或一个区),现在很灵活了,按寻呼量划分.当一个LAC下的寻呼量达到一个预警门限,就必须拆分. 定义 为了确定移动台的位置,每个GSMPLMN的覆盖区都被划分成许多位置区,位置区码(LAC)则用于标识不同的位置区。
-
基站定位是指手机发射基站根据与手机的距离来计算手机坐标地理位置的一种功能,基站定位一般应用于手机用户,手机基站定位服务又叫做移动位置服务(LBS服务),它是通过电信移动运营商的网络(如GSM网)获取移动终端用户的位置信息(经纬度坐标),在电子地图平台的支持下,为用户提供相应服务的一种增值业务。要使用基站定位接口,须在网络上找一个解析。定位精度最终取决于当地基站的密度。城市大概50到150米,城郊大
-
第一步: 先一键部署 #hub serving start -m lac 第二步: coding: utf8 import requests import json if name == “main”: # 指定用于预测的文本并生成字典[text_1, text_2, … ] text = [“今天是个好日子”, “天气预报说今天要下雨”] # 以key的方式指定text传入预测方法的时的参数,此
-
工具介绍 LAC全称Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。该工具具有以下特点与优势: 效果好:通过深度学习模型联合学习分词、词性标注、专名识别任务,整体效果F1值超过0.91,词性标注F1值超过0.94,专名识别F1值超过0.85,效果业内领先。 效率高:精简模型参数,结合Paddle预测库
-
链接 题目描述 给定一棵 nn 个点的树,QQ 个询问,每次询问点 xx 到点 yy 两点之间的距离。 输入格式 第一行一个正整数 nn,表示这棵树有 nn 个节点; 接下来 n-1n−1 行,每行两个整数 x,yx,y 表示 x,yx,y 之间有一条连边; 然后一个整数 QQ,表示有 QQ 个询问; 接下来 QQ 行每行两个整数 x,yx,y 表示询问 xx 到 yy 的距离。 输出格式 输出
-
代码如下: from LAC import LAC # 分词的功能 def fenci(): # 装载分词模型 lac = LAC(mode='seg') # 单个样本输入,输入为Unicode编码的字符串 text = u"LAC是个优秀的分词工具" seg_result = lac.run(text) print(seg_result)
-
一个高级语言程序在计算机中一般以文件形式存在,文件是一堆字节的集合,而它要表达的含义显然不是一堆字节,最小单位是一个个词,因此编译一个程序,一开始的工作就是词法分析 龙书的词法分析部分,掺杂了很多自动机相关的东西,其实这些在计算理论有更详细的描述,在编译原理里面讲大概是希望能让零基础的人看懂,可惜这样一来内容就比较臃肿,而且好像也讲的不是很系统反而让人看糊涂,就好像算法导论里面讲NP一样,虽然没有
-
本文向大家介绍c#中XML解析文件出错解决方法,包括了c#中XML解析文件出错解决方法的使用技巧和注意事项,需要的朋友参考一下 1.内容中含有xml预定好的实体,如“<”和“&”,对xml来说是禁止使用的,针对这种字符,解决方式是使用CDATA部件以"<![CDATA[" 标记开始,以"]]>"标记结束,是CDATA内部内容被解析器忽略。具体说明参考《XML CDATA是什么?》。 2.内容中含有
-
词法解析、语法解析 这一节我们分析下PHP的解析阶段,即 PHP代码->抽象语法树(AST) 的过程。 PHP使用re2c、bison完成这个阶段的工作: re2c: 词法分析器,将输入分割为一个个有意义的词块,称为token bison: 语法分析器,确定词法分析器分割出的token是如何彼此关联的 例如: $a = 2 + 3; 词法分析器将上面的语句分解为这些token:$a、=、2、+、3
-
本文向大家介绍python中文分词库jieba使用方法详解,包括了python中文分词库jieba使用方法详解的使用技巧和注意事项,需要的朋友参考一下 安装python中文分词库jieba 法1:Anaconda Prompt下输入conda install jieba 法2:Terminal下输入pip3 install jieba 1、分词 1.1、CUT函数简介 cut(sentence,
-
2. 词法分析 Python程序由解析器读取。输入到解析器中的是由词法分析器生成的词符流。本章讲述词法分析器如何把一个文件拆分成词符。 Python程序的文本使用7比特ASCII字符集。 2.3版中新增:可以使用编码声明指出字符串字面值和注释使用一种不同于ASCII的编码。 为了和旧的版本兼容,如果发现8比特字符,Python只会给出警告。修正这些警告的方法是声明显式的编码,或者对非字符的二进制数
-
上一篇文章讲到了状态机和词法分析的基本知识,这一节我们来分析Jsoup是如何进行词法分析的。 代码结构 先介绍以下parser包里的主要类: Parser Jsoup parser的入口facade,封装了常用的parse静态方法。可以设置maxErrors,用于收集错误记录,默认是0,即不收集。与之相关的类有ParseError,ParseErrorList。基于这个功能,我写了一个PageEr
-
本文向大家介绍Java中Json解析的方法分析,包括了Java中Json解析的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java中Json解析的方法。分享给大家供大家参考,具体如下: 首先准备一个JSON格式的字符串 下面是一个Json解析的程序代码 PS:关于json操作,这里再为大家推荐几款比较实用的json在线工具供大家参考使用: 在线JSON代码检验、检验、美化、格式
-
在我们的VS2012 web项目中,Resharper报告了数百个错误,但软件的构建和编译都很好。