
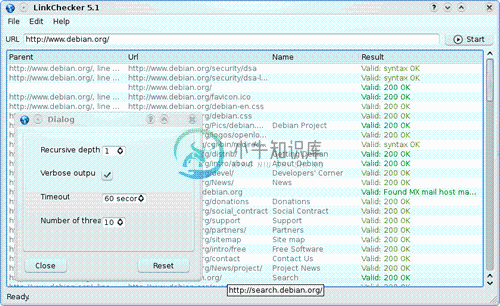
LinkChecker 是一个网页链接检查程序,主要特性:
- 循环遍历和多线程检查
- 输出各种格式检查结果:text, HTML, SQL, CSV, XML
- 支持 HTTP/1.1, HTTPS, FTP, mailto:, news:, nntp:, Telnet 和本地文件链接检查
- 可使用正则表达式对链接的url进行过滤
- 支持代理服务器
- 支持用户名和密码验证
- 遵守 robots.txt 法则
- 支持 Cookie
- 支持 HTML 和 CSS 语法检查
- 反病毒检查
- 提供命令行和图形界面和Web三种用户接口
-
LinkChecker 8.3 修复了 GUI 配置中忽略行的问题,另外从该版本开始代码移到 Github 上。 LinkChecker 是一个网页链接检查程序,主要特性: 循环遍历和多线程检查 输出各种格式检查结果:text, HTML, SQL, CSV, XML 支持 HTTP/1.1, HTTPS, FTP, mailto:, news:, nntp:, Telnet 和本地文件链接检查
-
问题内容: 如何检索网页链接并使用Python复制链接的URL地址? 问题答案: 这是在中使用类的一小段代码:
-
我们的Spotify链接如下所示: 我们刚刚注意到所有这些链接似乎都被破坏了--Spotify只是返回一个网页,上面写着“对不起,找不到那个”。我很难在网上找到任何有关这方面的信息。有没有人知道Spotify最近是否改变了他们的API,我们可以做什么来修复这些URL?
-
问题内容: 使用Java,如何从给定的网页中提取所有链接? 问题答案: 将Java文件下载为纯文本/ html格式,并通过Jsoup或 html clean传递,两者相似,甚至可以用于解析格式错误的html 4.0语法,然后可以使用流行的HTML DOM解析方法,例如getElementsByName(“ a”)或在jsoup中它甚至很酷,您只需使用 并找到所有链接,然后使用 取自http://j
-
我想知道如何链接到同一liferay网站中的另一个页面。 显然,我可以在我的portlet视图中硬编码url,但是我担心必须更新所有的portlet,以防友好的url在未来发生变化。 我知道我试图链接到的页面的名称,但是如果页面名称也改变了呢? 我发现了无数具有返回友好URL的方法的类,例如,,甚至,但它们都需要我不确定如何获取的参数。 是否有一个标准的方式获得友好的网址?
-
我正在使用selenium网络驱动程序来自动化网页。我的selenium代码没有识别链接。我收到以下错误。 线程“main”组织中出现异常。openqa。硒。NoSuchElementException:没有这样的元素:无法定位元素:{“method”:“xpath”,“selector”:“/html/body/font/font/b/a[2]”(会话信息:chrome=44.0.2403.89
-
问题内容: 只是一个基本的html链接问题。 我有一个Intranet设置,我需要链接到一些网络驱动器。它们位于\ server_drive \ blahblah \ doc.docx等驱动器上 在IE8或Firefox上都无法使用file://。如何链接到这些文件? 问题答案: 要从HTML文档链接到UNC路径,请使用file://///(是,这是五个斜杠)。 文件://////服务器/路径/到