
Caffe2 是一个兼具表现力、速度和模块性的深度学习框架,是 Caffe 的实验性重构,能以更灵活的方式组织计算。由 FaceBook 开源,该框架可以用在 iOS、Android 和树莓派上训练和部署模型。
建立 Caffe2
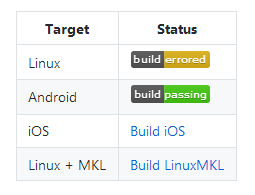
详细的构建矩阵:
git clone --recursive https://github.com/caffe2/caffe2.git cd caffe2
OS X
brew install automake protobuf mkdir build && cd build cmake .. make
Ubuntu
可运行版本:
Ubuntu 14.04
Ubuntu 16.06
需要的依赖包
sudo apt-get update sudo apt-get install -y --no-install-recommends \ build-essential \ cmake \ git \ libgoogle-glog-dev \ libprotobuf-dev \ protobuf-compiler \ python-dev \ python-pip sudo pip install numpy protobuf
可选择 GPU 支持
如果你计划使用 GPU,而不只是使用 CPU,那你应该安装 NVIDIA CUDA 和 cuDNN,这是一个面向深度神经网络的 GPU 加速库。英伟达在官方博客中详细介绍了安装指南,或者可以尝试下面的快速安装指令。首先,一定要升级你的图显驱动!否则你可能遭受错误诊断的极大困难。
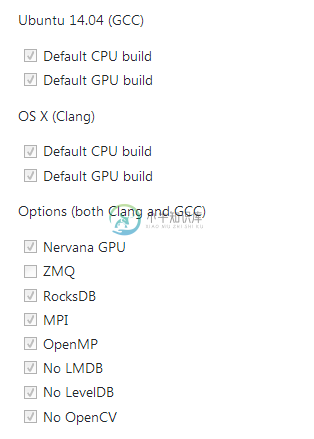
构建环境(已知能运行)

-
Caffe2存储 Caffe2中的存储结构层次从上到下依次是Workspace, Blob, Tensor。Workspace存储了运行时所有的Blob和实例化的Net。Blob可以视为对任意类型的一个封装的类,比如封装Tensor, float, string等等。Tensor就是一个多维数组,这个Tensor就类似于Caffe1中的Blob。Caffe2中真正涉及到分配存储空间的调用则在Con
-
认识Caffe与Caffe2 目录: 一、Caffe的作者-贾扬清 二、Caffe简介--Caffe、Caffe2、Caffe2Go 三、认识Caffe 四、认识Caffe2 五、认识Caffe2Go 正文: 一、Caffe的作者-贾扬清 Caffe 作者:贾扬清,任Facebook研究科学家,曾在Google Brain工作。在AI领域有数年的研究经历。在UC Berkeley获得计算机
-
前几天 facebook 开源的 caffe2,让我们在深度学习框架上又多了一个选择。caffe2 宣称是轻量级、模块化和可扩展的一个框架,code once,run anywhere。作为一个老 caffe 玩家,自是要好好研究一番。 依赖处理 第一版 caffe 的依赖是个让人头疼的事,尤其是在公司旧版的服务器上安装时,需要花费大量的时间折腾。服务器的系统旧,python的版本低(2.4),直
-
前几天 facebook 开源的 caffe2,让我们在深度学习框架上又多了一个选择。caffe2 宣称是轻量级、模块化和可扩展的一个框架,code once,run anywhere。作为一个老 caffe 玩家,自是要好好研究一番。 依赖处理 第一版 caffe 的依赖是个让人头疼的事,尤其是在公司旧版的服务器上安装时,需要花费大量的时间折腾。服务器的系统旧,python的版本低(2.4),直
-
项目需要用c++调用caffe2接口进行工程化部署,但是模型是用pytorch实现并训练。这就需要把pytorch预训练模型转化为可供c++调用的模型。 目前的问题是:训练环境和工程部署环境是不同的。利用python3.6+pytorch进行训练,模型部署是python2.7+caffe2。 总体流程: 1,在训练环境下也就是python3.6+pyto
-
在terminal中import caffe/caffe2都是没问题的,但是在pycharm中如果直接import caffe/caffe2,会报错ImportError: No module named caffe/caffe2,因为pycharm启动时未加载.bashrc中的环境变量。对比在pycharm中print sys.path和在terminal中print sys.path,会发现环
-
Caffe2 - Caffemodel 转换为 Caffe2 pb 模型 1. 单输入单输出 - caffe_translator.py Caffe2 提供了将 caffemodel 转换为 caffe2 模型的工具——caffe_translator.py. 其使用: python -m caffe2.python.caffe_translator deploy.prototxt pretrai
-
安装完caffe2后,使用python调用C++程序,出现如标题所示错误。 环境:windows10,visual studio 2015 原因分析: tips:我编译后的caffe2位于D:\projects\caffe2\build文件夹。 Import Error : No module named caffe.proto 原因是 caffe.proto模块的路径不正确,该模块位于D
-
用普通的安装方式走了不少弯路,感觉还是用docker方便: 参考的是https://hub.docker.com/r/caffe2ai/caffe2/ Latest docker pull caffe2ai/caffe2 Comes with GPU support, CUDA 8.0, cuDNN 7, all options, and tutorial files. Uses Caffe2 v
-
Table of Content Overview 所需依赖 编译安装 在 VS 中引用 Overview 环境:Windows 10,64 位,仅支持 CPU,仅 C++ 实测版本:Visual Studio 2017 Professional + Python 3.7.2 (Anaconda 1.9.6) + CMake 3.13.4 + Git 2.20.1 Caffe2 现仅支持 x64
-
>>> import torch Traceback (most recent call last): File "<stdin>", line 1, in <module> File "D:\anaconda3\envs\pytorch\lib\site-packages\torch\__init__.py", line 124, in
-
解决[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool...
pytorch 1.9遇到如下问题 问题: [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (functi
-
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool) [W pth
-
报错信息如下: C:\software\Anaconda3\envs\pytorch_190\python.exe C:/Users/stars_ocean/Desktop/PyTorch_test_folder/模型测试.py Traceback (most recent call last): File "C:/Users/stars_ocean/Desktop/PyTorch_test_
-
问题背景: import torch时提示 Error loading "D:\anaconda3\envs\simple_fasterrcnn\lib\site-packages\torch\lib\caffe2_detectron_ops.dll" or one of its dependencies. 可能的解决办法(我是这么解决的): 你的环境中有多个pytorch,卸载后重装。
-
主要内容 课程列表 专项课程学习 辅助课程 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 卷积神经网络视觉识别 Stanford 暂无 链接 神经网络 Tweet 暂无 链接 深度学习用于自然语言处理 Stanford 暂无 链接 自然语言处理 Speech and Language Processing 链接 专项课程学习 下述的课程都是公认的最好的在线学习资料,侧重点不同,但推
-
Google Cloud Platform 推出了一个 Learn TensorFlow and deep learning, without a Ph.D. 的教程,介绍了如何基于 Tensorflow 实现 CNN 和 RNN,链接在 这里。 Youtube Slide1 Slide2 Sample Code
-
torch是什么 torch就是诸多深度学习框架中的一种 业界有几大深度学习框架:1)tensorflow,谷歌主推,时下最火,小型试验和大型计算都可以,基于python,缺点是上手相对较难,速度一般;2)torch,facebook主推,用于小型试验,开源应用较多,基于lua,上手较快,网上文档较全,缺点是lua语言相对冷门;3)mxnet,大公司主推,主要用于大型计算,基于python和R,缺
-
我太菜了,C++需要恶补才行,面试完基本上就知道自己寄,面试官特别好给我说了很多,也让我充分认识到自己的不足 如果是项目的话,会问你项目背景以及项目最终的实现结果等等 如果是自己学习的项目的话,会问你对这个项目的学习心得 最后问对C++对掌握程度 实现vector
-
现在开始学深度学习。在这部分讲义中,我们要简单介绍神经网络,讨论一下向量化以及利用反向传播(backpropagation)来训练神经网络。 1 神经网络(Neural Networks) 我们将慢慢的从一个小问题开始一步一步的构建一个神经网络。回忆一下本课程最开始的时就见到的那个房价预测问题:给定房屋的面积,我们要预测其价格。 在之前的章节中,我们学到的方法是在数据图像中拟合一条直线。现在咱们不
-
深度学习的总体来讲分三层,输入层,隐藏层和输出层。如下图: 但是中间的隐藏层可以是多层,所以叫深度神经网络,中间的隐藏层可以有多种形式,就构成了各种不同的神经网络模型。这部分主要介绍各种常见的神经网络层。在熟悉这些常见的层后,一个神经网络其实就是各种不同层的组合。后边介绍主要基于keras的文档进行组织介绍。
-
Python 是一种通用的高级编程语言,广泛用于数据科学和生成深度学习算法。这个简短的教程介绍了 Python 及其库,如 Numpy,Scipy,Pandas,Matplotlib,像 Theano,TensorFlow,Keras 这样的框架。
-
你拿起这本书的时候,可能已经知道深度学习近年来在人工智能领域所取得的非凡进展。在图像识别和语音转录的任务上,五年前的模型还几乎无法使用,如今的模型的表现已经超越了人类。