
JSON.hpack 是一个用来压缩 JSON 数据的工具包和算法,目前提供了 PHP 和 C# 两种语言的版本。
压缩前:
[{
name : "Andrea",
age : 31,
gender : "Male",
skilled : true
}, {
name : "Eva",
age : 27,
gender : "Female",
skilled : true
}, {
name : "Daniele",
age : 26,
gender : "Male",
skilled : false
}]
压缩后:
[["name","age","gender","skilled"],["Andrea",31,"Male",true],["Eva",27,"Female",true],["Daniele",26,"Male",false]]
压缩效果:
-
JSON已得到广泛应用,在很多应用场景下,你可能想进一步地压缩JSON字符串的长度,以提升传输效率,这里向你介绍两种常用的同构压缩算法:CJSON和HPack。 CJSON压缩示例 原始JSON: [ { // This is a point "x": 100, "y": 100 }, { // This is a rectangle "x": 100,
-
一般的json文件拥有很多的空格和注释,虽然读起来比较方便,但是在运行的时候是要占一些内存的。 于是json压缩工具就应运而生了,这个工具是用java做的,原理是: 1:在Eclipse中导出一个可运行的jar文件 2:用python运行这个jar文件,并向这个jar文件的运行程序传一些main方法的参数(一般只传路径就可以了) //bat文件的代码如下: set assetsAPath="..j
-
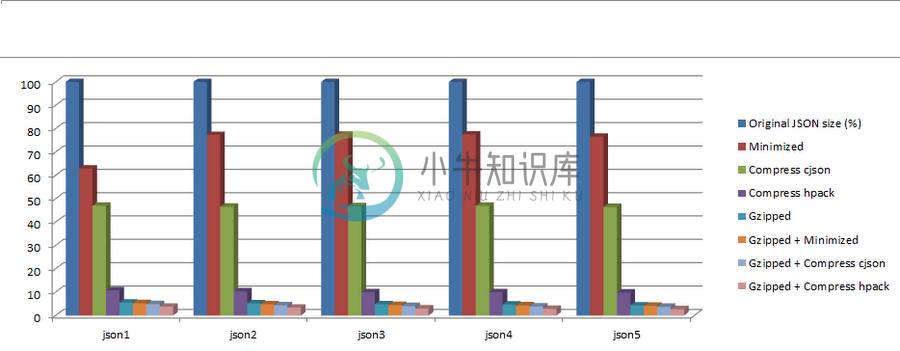
总结:HPack 优于 CJSON json1 json2 json3 json4 json5 Original JSON size (bytes) 52966 104370 233012 493589 1014099 Minimized 33322 80657 180319 382396 776135 Compress CJSON 24899 48605 108983 231760 471230
-
一般的json文件拥有很多的空格和注释,虽然读起来比较方便,但是在运行的时候是要占一些内存的。 于是json压缩工具就应运而生了,这个工具是用java做的,原理是: 1:在Eclipse中导出一个可运行的jar文件 2:用python运行这个jar文件,并向这个jar文件的运行程序传一些main方法的参数(一般只传路径就可以了) //bat文件的代码如下: set assetsAPath="..\
-
php解析json数据二种实例方法 大多数流行的 Web 服务如 twitter 通过开放 API 来提供数据一样,它总是能够知道如何解析 API 数据的各种传送格式,包括 JSON,XML 等等。 $json_string='{"id":1,"name":"php100.com","email":"php教程">admin@php100.com","interest":["wordpress",
-
我在文件list.txt中有以下JSON: { "bgates":{"first":"Bill","last":"Gates"}, "sjobs":{"first":"Steve","last":"Jobs"} } 如何使用PHP将“bross”:{“first”:“Bob”,“last”:“Ross”}添加到我的文件? 这里是我到目前为止: $user = "bross"; $first = "
-
在前端与后端做交互的时候,有的时候为了减少网络请求,很多时候都会将修改频次极低生成本地化文件进行直接操作,例如地址选择的数据,现在很多平台都是采用将这样的操作。不过对于一些少量数据的,这是一件非常简单的事情,但是当遇到大量数据的时候,这个就明显GG,今天我就遇到了一个,如果按照前端既定的结构生成json文件,文件是4.2M,当时的我简直满脸黑线,后面找到了方法,将数据降低到0.7M,这大概是我现在
-
json是一种非常简单、易读的数据结构。通常我们在做开发时,会选取json作为数据传输格式。同时为了提升性能、降低带宽,我们一般会对json数据进行压缩。今天我们就来谈谈各种压缩方法。 1、常规压缩: 默认的json数据是带有换行的,所以最简单的压缩方法是将json中的回车换行去掉,压缩成一行字符串。 测试:找了一个大的json字符串,原始大小为1.1m,去掉回车换行压缩成一行后,大小变为了360
-
JSON Compression algorithms 作者 Alex 原文链接 About JSON (Java Script Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse an
-
节省流量,Andriod中必备啊 JSON 的压缩算法, 目前有 CJSON 和 HPack 两种, 都是透过结构的改变, 来将容量压小, 所以 Client 端写法还是得要改写. (不同于 gzip 等压缩算法) HPack 与 CJSON 的 Source code CJSON: 下载 (备份) HPack: WebReflection/json.hpack - GitHub CJSON Co
-
JSON优势 没有比较,就没有话语权 JSON与xml比较,优势可以概括为以下几点 1.1可读性 JSON与XML旗鼓相当 1.2可扩展性 JSON与XML旗鼓相当 1.3.编码难度 JSON略胜一筹 1.4.解码难度 JSON碾压XML,可能原因为,我是弱鸡吧 1.5流行度 JSON新起之秀 1.6数据大小 JSON略胜一筹 1.7传输速度 JSON碾压XML 1.6和1.7的原因
-
我希望使用log4j2 RollingFileAppender和定制的压缩算法(ZStd)。 目前为止支持的压缩算法似乎是FileExtension枚举(zip,gz,bz2,...)中的压缩算法,请参见https://github.com/apache/logging-log4j2/blob/efa64bfad3f67c5b5fed6b25d65ef5ca2212011b/log4j-core/
-
我试图找到一种压缩算法,我可以使用它来编码一个blob,只使用16个固定长度的符号(0b0000-0b1111)。 在没有任何压缩的情况下,我可以使用这16个符号对其各自的位值进行编码(例如,符号5(0b0101)对位0101进行编码,因此如果我的blob是100位长,我需要25个符号来表示它-但这样做不会提供压缩。 我认为我需要的是一个反向霍夫曼(在某种意义上,代码是固定长度的,但它代表可变长度
-
DEFLATE 是同时使用了哈夫曼编码(Huffman Coding)与 LZ77 算法的一个无损数据压缩算法,是一种压缩数据流的算法。任何需要流式压缩的地方都可以用。目前 zip 压缩文件默认使用的就是该算法。 关于算法的原理,以及 哈夫曼编码(Huffman Coding)与 LZ77 算法,感兴趣的读者可以查询相关资料,这里推荐 GZIP压缩原理分析——第五章 Deflate算法详解 序列文
-
问题内容: python docs将此代码作为zip的反向操作: 特别是 zip()与*运算符一起可用于解压缩列表。 有人可以向我解释运算符在这种情况下如何工作吗?据我了解,是一个二进制运算符,可以用于乘法或浅表复制…在这里似乎都不是这样。 问题答案: 像这样使用时,*(星号,在某些情况下也称为“ splat”运算符)是从列表中解压缩参数的信号。有关示例的更完整定义,请参见http://docs.
-
解析redis的lzf压缩和解压算法
-
让我澄清一下,我不是在说完美压缩,也不是说一种能够压缩任何给定源材料的算法,我意识到这是不可能的。我试图得到的是一种算法,它能够将任何源比特串编码到它的绝对最大压缩状态,这取决于它的香农熵。 我相信我听说过一些关于霍夫曼编码在某种意义上是最优的事情,所以我相信这个加密方案可能是基于此的,但这是我的问题: 考虑位串:a="101010101010",b="110100011010"。 使用纯香农熵,
-
我有两个问题。其中一个会把话题弄得乱七八糟:) 1)我遇到了一个问题,即无法找到关于不同垃圾收集器在Hotspot中如何工作的完整信息。但我不是在谈论垃圾收集器工作的一般描述(我们在互联网上有很多这样的信息),我是在谈论具体的算法。我找到了这本白皮书(Java HotSpot虚拟机中的内存管理)http://www.oracle.com/technetwork/Java/javase/tech/m
-
tar [-]c|x|u|r|t[z|j][v] -f 归档文件 [待打包文件] 将多个文件打包为一个归档文件,可以在打包的同时进行压缩。支持的格式为 tar(归档)、gz(压缩)、bz2(压缩率更高,比较耗时) 操作选项 -c 创建 -x 解包 -u 更新 -r 添加 -t 查看 -d 比较压缩包内文件和文件 -A 将 tar 文件添加到归档文件中 格式选项 -z 使用 gz 压缩格式 -j 使