
Heritrix是一个开源,可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix是一个爬虫框架,其组织结构如图2.1所示,包含了整个组件和抓取流程:
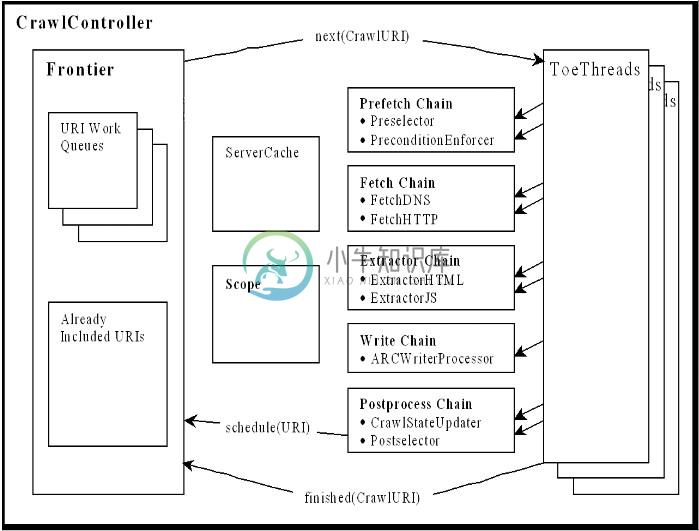
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。控制器结构图如图2.2所示:
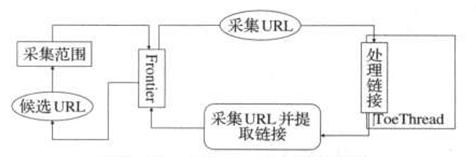
图2.2 CrawlController类结构图
CrawlController类是整个爬虫的总控制者,控制整个抓取工作的起点,决定整个抓取任务的开始和结束。CrawlController从Frontier获取URL,传递给线程池(ToePool)中的ToeThread处理。
Frontier(边界控制器)主要确定下一个将被处理的URL,负责访问的均衡处理,避免对某一Web服务器造成太大的压力。Frontier保存着爬虫的状态,包括已经找到的URI、正在处理中的URI和已经处理过的URI。
Heritrix是按多线程方式抓取的爬虫,主线程把任务分配给Teo线程(处理线程),每个Teo线程每次处理一个URL。Teo线程对每个URL执行一遍URL处理器链。URL处理器链包括如下5个处理步骤。整个流程都在图2.1中。
(1)预取链:主要是做一些准备工作,例如,对处理进行延迟和重新处理,否决随后的操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表单。
(3)抽取链:当提取完成时,抽取感兴趣的HTML和JavaScript,通常那里有新的要抓取的URL。
(4)写链:存储抓取结果,可以在这一步直接做全文索引。Heritrix提供了用ARC格式保存下载结果的ARCWriterProcessor实现。
(5)提交链:做和此URL相关操作的最后处理。检查哪些新提取出的URL在抓取范围内,然后把这些URL提交给Frontier。另外还会更新DNS缓存信息。
服务器缓存(Server cache)存放服务器的持久信息,能够被爬行部件随时查到,包括被抓取的Web服务器信息,例如DNS查询结果,也就是IP地址。
-
强大的网络爬虫框架--Heritrix:基于多线程的高效率的网络爬虫框架。 第一部分:介绍Heritrix的基本使用(首先需要从Heritrix的官网上下载相应的项目) 1.导入jar包 需要注意在项目根目录下添加lib文件夹,然后将相关联的jar包添加进去 2.拷贝源代码 src-java con/org/st运行Heritrix所必需的核心代码,拷贝到项目MyHeritrix目录下 s
-
heritrix下载及配置 一、下载:到www.sourceforge.net网站搜索heritrix,然后分别下载下来heritrix-1.14.0-RC1.zip,heritrix-1.14.0-RC1-src.zip 二、配置 .在非开发环境下配置的步骤 1.解压heritrix-1.14.0-RC1.zip,假设解压到了c盘根目录下并把解压后的文件夹命名为heri
-
一、 安装、配置Heritrix 1、将得到的heritrix-1.14.4.zip压缩包直接解压缩到某一目录,我选择的是F:\Heritrix。 2、然后,将 F:\Heritrix 目录中的heritrix-1.14.4.jar文件解压缩,把 profiles\default 下的两个文件order.xml和seeds.txt复制到 F:\Heritrix\conf 目录下
-
看了自己动手做搜索引擎那本书,上面写的运行heritrix的方法挺麻烦的!要加载好多jar包,懒得弄。后来发现bin文件夹里面本来就有一个heritrix.cmd的文件,我想着一定就是windows下的运行文件,运行了一下,提示输入用户名密码! 输入用户名密码了以后,又说找不到密码文件“jmxremote.password”。我发现在conf文件夹里面就有一个jmxremote.password.
-
1、Frontier(链接工厂)是Heritrix最核心的部分,有三个核心的方法:next,schedule,finished,其原型及作用如下: a) 程提供一个链接.Heritrix的所有处理线程(ToeThread)都是通过调用该方法获取链接的 b) schedule(CandidateURI caURI):调度待处理的链接 c) finished(CrawlURI cURI):完成一个已
-
建立新java工程,MyHeritrix。 解压缩heritrix-1.14.4-src.zip 1、复制 heritrix-1.14.4-src\src\java\目录下的 com,org,st 这三个文件夹到工程的src目录下 2、复制 heritrix-1.14.4-src\lib目录,到工程的根目录下,跟src同级,并且添加到classpath中.选择工程中所有jar,单击右键,Build
-
1、版本说明 (1)最新版本:3.3.0 (2)最新release版本:3.2.0 (3)重要历史版本:1.14.4 3.1.0及之前的版本:http://sourceforge.net/projects/archive-crawler/files/ 3.2.0及之后的版本:http://archive.org/ 由于国情需要,后者无法访问,因此本blog研究的是1.14.4版本。 2、官
-
Heritrix简介 爬虫概念,spider 像蜘蛛网一样的,从一个提供的种子URL地址开始,抓取当前URL的所有对外链接,往外发散。应该有URL去重复功能(去重复与增量抓取相互矛盾)、抓取层次限制功能。 Heritrix是什么? 一个开源的纯java的网络爬虫框架。遵循网站 robots(某些网站上有一些资源在时间上受下载或访问限制) 协议。 Heritrix优点? Heritrix采用了Ber
-
1. 关于Heritrix的Extractor中文乱码 继承从org.archive.crawler.extractor.Extractor的子类,在extract方法中可以从参数CrawlURI中取出要解析的内容。 curi.getHttpRecorder().getReplayCharSequence.toString() 有中文时,不做处理会输出乱码。可以在取到的HttpRecorder后
-
//-------转载-------------------------- 1 下载 和 解压 从http://crawler.archive.org/下载解压到本地 E:/heritrix-1.14.3 2 配置环境变量 HERITRIX_HOME=E:/heritrix-1.14.3 path后追加 ;%HERITRIX_HOME%/bin 3 配置 heritrix 拷贝E:/her
-
1、抓取起点CrawlOrder 在heritrix- 1.12.1 /docs/apidocs目录下可以查看其API: org.archive.crawler.datamodel Class CrawlOrder java.lang.Object
-
package heritrix; public class heritrixSourceAnalyzer01 { public static void main(String[] args) { System.out.println("Heritrix源码解读!"); } /* * -----------------------------
-
原文链接:http://www.cnblogs.com/MichaelYin/archive/2011/10/10/2205699.html 实际的url的处理是在toethread中进行的,toethread从Frontier中请求待处理的url,并将其放到一系列Processor中进行处理 可以以流水线上的处理流程来想象Processor,流水线上的产品就是url,由于处理的process
-
一、Heritrix直接安装 1、下载 heritrix-1.14.4.zip、heritrix-1.14.4-src.zip,将得到的heritrix-1.14.4.zip压缩包直接解压缩到某一目录。如:F:\Heritrix 2、然后,将 F:\Heritrix 目录中的heritrix-1.14.4.jar文件解压缩,把 profiles\default 下的两个文件order.xml和se
-
转载自:http://jason823.iteye.com/blog/84206 一、框架介绍 公司最近项目要用到全文检索,检索对象是一些网站的网页内容,要使用到网络爬虫工具。 目前技术选型对象主要有两个:Heritrix 和 Nutch。二者均为Java开源框架,Heritrix 是 SourceForge上的开源产品,Nutch为Apache的一个子项目,它们都称作网络爬虫/蜘蛛( Web C
-
一、Heritrix简介 Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。 二、Heritrix安装(Eclipse) 首先要去官网下载最新版本的heritrix。下载地址为:http://sourceforge.net/project/showfiles.php?group_id=7
-
准备用Heritrix来做个小的搜索引擎,以下是我在配置Heritrix的过程中遇到的各种问题,通过几个小时的查找和分析,终于把Heritrix的单独配置和在eclipse下的配置做成功了。我在配置过程中遇到问题的时候,发现网上关于这方面的资料比较少,很多人都遇到过相同的问题,但没有人具体详细的给予解答,下面我将从网上获得的资料和我个人的认识进行总结,希望对才开始配置Heritrix的朋友有所帮助
-
password文件必须设置为只读,否则就会出现如下错误: F:/heritrix/bin>heritrix --admin=admin:admin WARNING: It's currently not possible to run Heritrix in background on Windows. It was just started minimized in a n
-
有哪位哥们知道为什么我用Heritrix抓取页面(在一个网站中),却只有一个线程工作. package com.lantao.bookuu.frontierschedule; import org.archive.crawler.datamodel.CandidateURI; import org.archive.crawler.framework.CrawlController; import
-
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种. 通用爬虫 通用网络爬虫 就是 捜索引擎抓取系统,目的是将互联网上的所有的网页下载到本地,形成一个互联网内容的镜像备份。 它决定着整个搜索引擎内容的丰富性和时效性,因此它的性能优劣直接影响着搜索引擎的效果。 通用搜索引擎(Search Engine)工作原理 第一步:抓取网页 搜索引擎网络爬虫的基本工作流程如下: 首先选取一部分的初始UR
-
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
本文向大家介绍python爬虫爬取淘宝商品信息,包括了python爬虫爬取淘宝商品信息的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 效果图: 更多内容请参考专题《python爬取功能汇总》进行学习。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
拼多多爬虫工程师面试题 电话面: http协议、tcp协议(几次握手) top命令 Linux/Mac 下虚拟内存(Swap) 线程、进程、协程 Async 相关、事件驱动相关 阻塞、非阻塞 Python GIL 布隆过滤器原理:如何实现、一般要几次哈希函数 给我留下了一个作业:抓取天猫超市上某些商品的可以配送省份信息。(当时做这个也花了很久,主要是需要解决PC端的登陆问题,后来通过h5接口) 现
-
什么是数据采集 定义 就我个人而说,更喜欢说数据采集而不是”爬虫“。其实更标准的叫法是网络爬虫,在wiki上是这样定义的: 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 就比如百度、谷歌,都是网络爬虫,把互联网上所有的数据采集下来,保存到自己的数据库中,并根据各种各种规则建立排名和索引,向用户提供搜索服务。
-
每天,来自商业、社会以及我们的日常生活所产生「图像、音频、视频、文本、定位信息」等各种各样的海量数据,注入到我们的万维网(WWW)、计算机和各种数据存储设备,其中万维网则是最大的信息载体。