
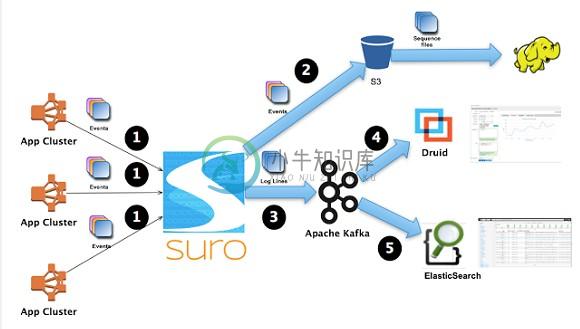
Netflix 开源了一个叫做Suro的工具,它能够在数据被发送到不同的数据平台(如Hadoop、Elasticsearch)之前,收集不同应用服务器上的事件数据,这项创新技术具备成为大数据主流实践的潜力
Suro 是数据管道服务,用来收集,聚合和调度大数据应用事件,包括日志记录数据。
特性:
-
分布式,支持横向扩展
-
支持流媒体数据流,大量连接和高吞吐量
-
根据领过的调度规则允许动态调度时间到不同的位置
-
包括一个简单而灵活的架构,允许用户添加额外的数据目的地
-
适用于 NetflixOSS 生态系统
-
是最优的数据管道,支持灵活的重试和转发,把数据丢失减到最小
-
https://github.com/Netflix/suro 原文出处:Netkiller 系列 手札 本文作者:陈景峯 转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。
-
Netflix近日开源了一个叫做Suro的工具,可以收集来自多个应用服务器的事件数据,并实时定向发送到目标数据平台如Hadoop和Elasticsearch。Netfix的这项创新有望成为大数据主流技术。 Netflix用Suro进行数据源到目标主机的实时导向,Suro不但在Netflix的数据管道中扮演关键角色,而且也是脱胎大型互联网公司的众多开源数据分析工具中的佼佼者。 Netflix
-
AWS Data Pipeline是一种Web服务,旨在使用户能够更轻松地集成跨多个AWS服务的数据,并从单个位置对其进行分析。 使用AWS Data Pipeline,可以从源访问数据,进行处理,然后将结果有效地传输到相应的AWS服务。 如何设置数据管道? 以下是设置数据管道的步骤 - Step 1 - 使用以下步骤创建管道。 登录AWS账户。 使用此链接打开AWS Data Pipeline控
-
只有在必要时,我才尝试在“httpRequestBegin”管道中执行一些操作。我的处理器在Sitecore解析用户后执行(processor type=“Sitecore.Pipelines.HttpRequest.UserResolver,Sitecore.Kernel”),因为如果Sitecore无法首先解析用户,我也在解析用户。 稍后,我想在管道“insertRenderings”中添加一
-
我在DynamoDB有一个表,它有数百万条记录。我已经根据标准创建了一个二级索引(GSI),并基于此筛选产品。现在,我想使用AWS数据管线从表中查询产品并将其导出到S3。 a)我们可以在管道中指定GSI名称吗?因为使用数据管道对大型表进行查询会因为超时问题而被取消。[管道配置有6小时的最大等待时间,它正在达到并被取消]?b)有没有更好的方法来使用GSI索引从表中快速创建导出转储? 请分享你的观点。
-
问题 你想以数据管道(类似Unix管道)的方式迭代处理数据。 比如,你有个大量的数据需要处理,但是不能将它们一次性放入内存中。 解决方案 生成器函数是一个实现管道机制的好办法。 为了演示,假定你要处理一个非常大的日志文件目录: foo/ access-log-012007.gz access-log-022007.gz access-log-032007.gz ..
-
我正在尝试设置我的开发环境。我一直在使用pubsub模拟器进行开发和测试,而不是在生产中使用谷歌云pubsub。为此,我设置了以下环境变量: 这适用于python google pubsub库,但当我切换到使用java apache beam进行google数据流时,管道仍然指向生产google pubsub。管道上是否有需要设置的设置、环境变量或方法,以便管道读取本地pubsub仿真器?
-
我使用beam SDK用python编写了一个Google数据流管道。有一些文档介绍了我如何在本地运行它,并设置runner标志以在数据流上运行它。 我现在正尝试将其自动部署到CI管道(bitbucket管道,但并不真正相关)。有关于如何“运行”管道的文档,但没有真正的“部署”管道。我测试过的命令如下: 这将运行作业,但因为它正在流式传输,所以永远不会返回。它还在内部管理打包并推送到存储桶。我知道