
Piggydb是一个知识管理软件,可以个人和小团体使用。从输入各种信息,来连接他们,然后分类管理,让您可以建立自己的知识和创造想法。
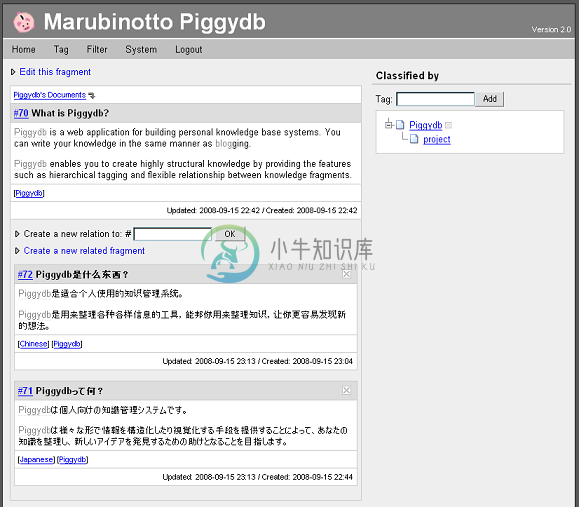
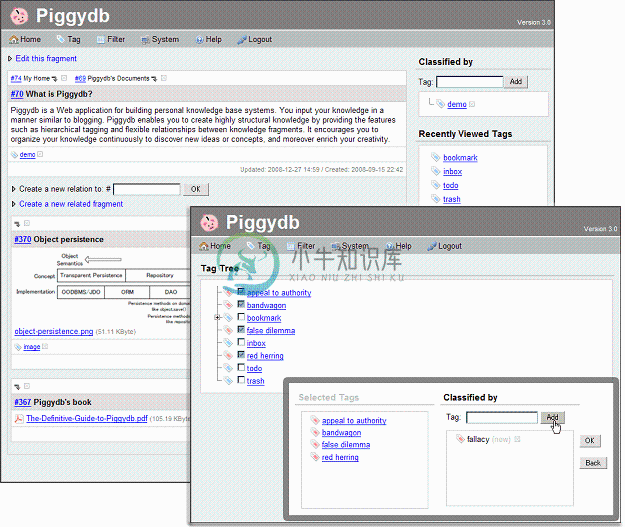
先从登记很多各种小片断的信息开始,然后把他们自由地连接在一起和分类,把信息培养和发展成对自己有益的知识,这是Piggydb的概念。Piggydb是用标签来分类的,而且标签可以分层次,这比传统的标签系统更能实现复杂的分类。
Piggydb虽然拥有全文搜索功能,但是如果只是用来把信息登记后,然后只去搜索的使用方法,其实有很多比Piggydb更优秀的软件可用。对Piggydb来说,主要的目的是通过连接和分类各种信息的过程,来让使用者从中学到和发现新的知识。
* 易于安装,开始使用时无需任何设置
* 适合个人和小团体,登记的信息可以设置是私人的,或是是公开的
* 重点不是信息,而是配置信息的过程
如果不是很了解这个软件,可以先作为日记或记事本来使用,等理解了构造后(其实是很简单的!),慢慢地尝试把有益的信息进行分类就好了。
-
Piggydb 6.6 发布,知识管理软件 http://www.oschina.net/news/36297/piggydb-6-6
-
分享:Piggydb 6.5 发布,个人知识库管理 Piggydb 6.5 发布,个人知识库管理 http://www.oschina.net/news/35867/piggydb-6-5 posted on 2012-12-18 22:13 lexus 阅读( ...) 评论( ...) 编辑 收藏 转载于:https://www.cnblogs.com/lexus/archive/2012/
-
1、接口声明 在调用接口时必须在https请求的header中携带"token"参数。 token是智齿客服接口开放平台全局唯一的接口调用凭据。 开发者在调用各业务接口时都需使用token,开发者需要进行妥善保存。token的存储至少要保留32个字符空间。token的有效期目前为24个小时,需定时刷新,或根据接口返回的token失效提示,进行重新获取。请求token接口,无论token是否存在,都
-
因为要学的东西很多,因此这段时间一直在考虑建立一个个人知识管理系统,以便更好的梳理自已的学习内容,同时也便于分享,所以最终决定用 Wiki 的形式来打造这一项目。 # 为什么选择 Wiki 来进行知识管理? Wiki 提供了一种很好的文档格式化功能,可以很好的建立自己的知识体系。同时 Wiki 本来就适用于知识的共享及协同合作,这样既可以分享给别人,也可以让其他的朋友来一起帮助你。 另外,在线的
-
主要内容:推理系统,由KBA执行的操作,基于知识的通用代理:,各级知识型代理商:,设计基于知识的代理的方法在人工智能中的知识基础代理: 智能代理需要有关现实世界的知识,才能做出有效行动的决策和推理。 基于知识的代理人是那些能够维持内部知识状态,理解知识,在观察后更新知识并采取行动的代理。这些代理可以用一些正式的代表来代表世界,并且能够智能地行动。 基于知识的代理由两个主要部分组成: 知识库和 推理系统。 基于知识的代理必须能够执行以下操作: 代理应该能够代表状态,行动等。 代理应该能够纳入新的感
-
一.介绍(Introduction) 1.XunTa是在lucene4.3上创建的通过“知识点”来找人的搜人引擎。 输入一个关键词(或组合),XunTa返回一个排名列表,排在前面的人是与该关键词(组合)最相关的“达人”。 可访问 http://www.xunta.so立即体验. 2.什么是搜人引擎? 这里的搜人不是人肉搜索,而是用户根据自己的兴趣和爱好输入相关知识点,然后找到这个知识点上的达
-
知识词库 1.知识词库类型 爱客服知识库系统支持多种知识词库,包括同义词库、敏感词库、专业词库、变量词库等,支持用户高度自定义自身词库,从而完善机器人问答能力,词库类型如下: 同义词库:同义词是用于多义词、同义词的优先识别,例如:订单、定单,同义词既可以是日常包含的同义词,也可以是易识别错的同音词 敏感词库:敏感词库的设立是用于将返回给用户的答案进行过滤,敏感词库中的词语将在最后的会话中进行过了,
-
本文向大家介绍Python测试人员需要掌握的知识,包括了Python测试人员需要掌握的知识的使用技巧和注意事项,需要的朋友参考一下 a、字符串的定义方法 使用单引号(') 你可以用单引号指示字符串,就如同'Quote me on this'这样。所有的空白,即空格和制表符都照原样保留。 使用双引号(") 在双引号中的字符串与单引号中的字符串的使用完全相同,例如"What's your name?"