
注意:tddl2.0是2010年的版本,已经没有人维护了。当前版本是5.1.7,网上能够找到的最新版本。项目地址为:https://www.oschina.net/p/tddl5
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):
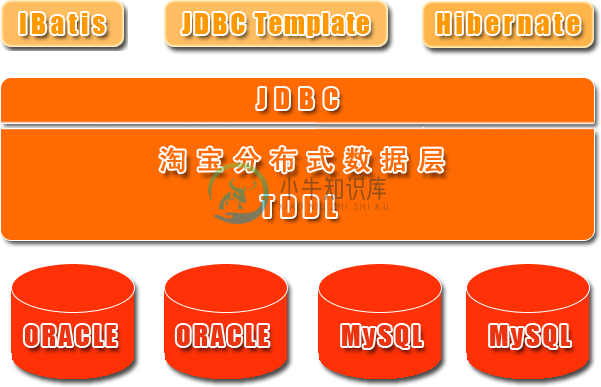
淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作 一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是 分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能 够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一 个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
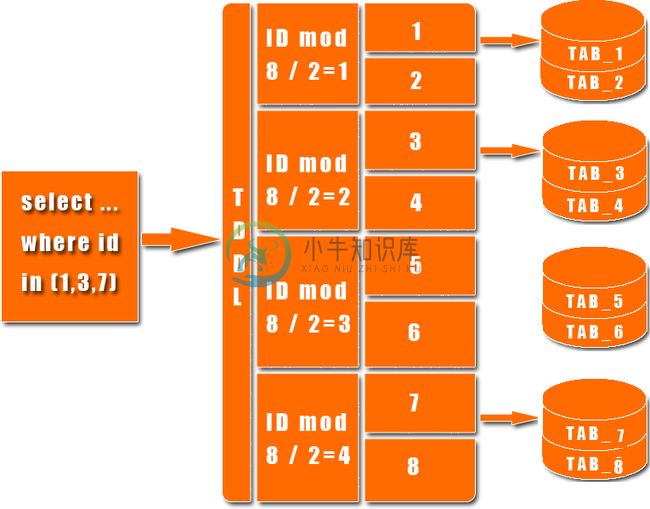
下图展示了一个简单的分库分表数据查询策略:
主要优点:
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
-
一、目前项目中只是使用了TDDL的主从模块 <bean id="dataSource" class="com.taobao.tddl.group.jdbc.TGroupDataSource" init-method="init" destroy-method="destroyDataSource"> <property name="appName" value="gome_market_s
-
总体描述 TDDL动态数据源主要分为2层,每一层都实现了jdbc**规范**,以方便地集成到各种orm框架或者直接使用.每一层都各司其职. TGroupDataSource(tddl group ds)默认情况下依赖TAtomDataSource(tddl atom ds),但是可以扩展依赖普通数据源.这一层主要的职责是解决读写分离以及主备切换的问题,当然是在线执行这些动作,无需重启.一个TGro
-
使用入门-数据源配置 数据源配置,tddl的入口,从datasource切入 <bean id="tddlDataSource" class="com.taobao.tddl.client.jdbc.TDataSource" init-method="init"> <property name="appName" value="tddl_sample" /> <property n
-
一、前言 关于taobao的tddl-common包(5.1.0)的com.taobao.tddl.common.jdbc.TExceptionUtils异常工具类,对SQLException集合异常日志标准化打印、合并拼接处理及自定义打印输出等,详见源码说明。 二、源码说明package com.taobao.tddl.common.jdbc;@b@@b@import java.sql.SQLE
-
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
淘宝根据自己的业务特点开发了 TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource 实现,具有主备,读写分离,动态数据库配置等功能。 分布式数据库中间件支持哪些SQL? 除了union,union all,其他都支持 使用示例:ht
-
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
这里我的疑问是,如果我使用多个分布式数据库,cam如何在配置(application.properties)中提到不同的DB源URL?目前我正在使用以下结构来使用一个数据库, 就像上面那样。 所以,如果我使用多个DB用于多个区域,我如何在这里给出有条件的配置?我是微服务世界和分布式数据库设计模式的新手。
-
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
主要内容:并行化集合,外部数据集RDD(弹性分布式数据集)是Spark的核心抽象。它是一组元素,在集群的节点之间进行分区,以便我们可以对其执行各种并行操作。 有两种方法可以用来创建RDD: 并行化驱动程序中的现有数据 引用外部存储系统中的数据集,例如:共享文件系统,HDFS,HBase或提供Hadoop InputFormat的数据源。 并行化集合 要创建并行化集合,请在驱动程序中的现有集合上调用的方法。复制集合的每个元素以形成