
AlphaGo 是对 DeepMind 2016 自然出版社关于“掌握围棋和深层神经网络树搜索”的复制实现。详情请看其网址 http://deepmind.com/alpha-go.html 。
神经网络训练管道和架构:
-
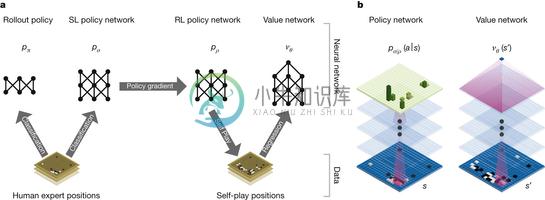
AlphaGo Zero 和 AlphaGo 都是由谷歌的 DeepMind 开发的围棋 AI 程序。 AlphaGo Zero 与 AlphaGo 的主要区别在于 AlphaGo Zero 是一种基于强化学习的围棋 AI 程序,它不需要人类围棋数据来训练,而是通过自我对弈学习策略。 AlphaGo Master 是 AlphaGo 的升级版本,它被设计为在较短的时间内更快地计算围棋棋盘上的可能情
-
第 10 章介绍了人工神经网络,并训练了我们的第一个深度神经网络。 但它是一个非常浅的 DNN,只有两个隐藏层。 如果你需要解决非常复杂的问题,例如检测高分辨率图像中的数百种类型的对象,该怎么办? 你可能需要训练更深的 DNN,也许有 10 层,每层包含数百个神经元,通过数十万个连接来连接。 这不会是闲庭信步: 首先,你将面临棘手的梯度消失问题(或相关的梯度爆炸问题),这会影响深度神经网络,并使较
-
LeNet 5 LeNet-5是第一个成功的卷积神经网络,共有7层,不包含输入,每层都包含可训练参数(连接权重)。 AlexNet tf AlexNet可以认为是增强版的LeNet5,共8层,其中前5层convolutional,后面3层是full-connected。 GooLeNet (Inception v2) GoogLeNet用了很多相同的层,共22层,并将全连接层变为稀疏链接层。 In
-
深度神经网络的工作地点、原因和方式。从大脑中获取灵感。卷积神经网络(CNN)和循环神经网络(RNN)。真实世界中的应用。 使用深度学习,我们仍然是习得一个函数f,将输入X映射为输出Y,并使测试数据上的损失最小,就像我们之前那样。回忆一下,在 2.1 节监督学习中,我们的初始“问题陈述”: Y = f(X) + ϵ 训练:机器从带标签的训练数据习得f 测试:机器从不带标签的测试数据预测Y 真实世界很
-
代码见nn_overfit.py 优化 Regularization 在前面实现的RELU连接的两层神经网络中,加Regularization进行约束,采用加l2 norm的方法,进行负反馈: 代码实现上,只需要对tf_sgd_relu_nn中train_loss做修改即可: 可以用tf.nn.l2_loss(t)对一个Tensor对象求l2 norm 需要对我们使用的各个W都做这样的计算(参考t
-
本章到目前为止介绍的循环神经网络只有一个单向的隐藏层,在深度学习应用里,我们通常会用到含有多个隐藏层的循环神经网络,也称作深度循环神经网络。图6.11演示了一个有$L$个隐藏层的深度循环神经网络,每个隐藏状态不断传递至当前层的下一时间步和当前时间步的下一层。 具体来说,在时间步$t$里,设小批量输入$\boldsymbol{X}_t \in \mathbb{R}^{n \times d}$(样本数
-
在LeNet提出后的将近20年里,神经网络一度被其他机器学习方法超越,如支持向量机。虽然LeNet可以在早期的小数据集上取得好的成绩,但是在更大的真实数据集上的表现并不尽如人意。一方面,神经网络计算复杂。虽然20世纪90年代也有过一些针对神经网络的加速硬件,但并没有像之后GPU那样大量普及。因此,训练一个多通道、多层和有大量参数的卷积神经网络在当年很难完成。另一方面,当年研究者还没有大量深入研究参
-
深度神经网络(DNN)是在输入和输出层之间具有多个隐藏层的ANN。 与浅层神经网络类似,DNN可以模拟复杂的非线性关系。 神经网络的主要目的是接收一组输入,对它们执行逐步复杂的计算,并提供输出以解决诸如分类之类的现实世界问题。 我们限制自己前馈神经网络。 我们在深层网络中有输入,输出和顺序数据流。 神经网络广泛用于监督学习和强化学习问题。 这些网络基于彼此连接的一组层。 在深度学习中,隐藏层的数量
-
神经网络和深度学习是一本免费的在线书。本书会教会你: 神经网络,一种美妙的受生物学启发的编程范式,可以让计算机从观测数据中进行学习 深度学习,一个强有力的用于神经网络学习的众多技术的集合 神经网络和深度学习目前给出了在图像识别、语音识别和自然语言处理领域中很多问题的最好解决方案。本书将会教你在神经网络和深度学习背后的众多核心概念。 想了解本书选择的观点的更多细节,请看这里。或者直接跳到第一章 开始