
Alluxio 是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
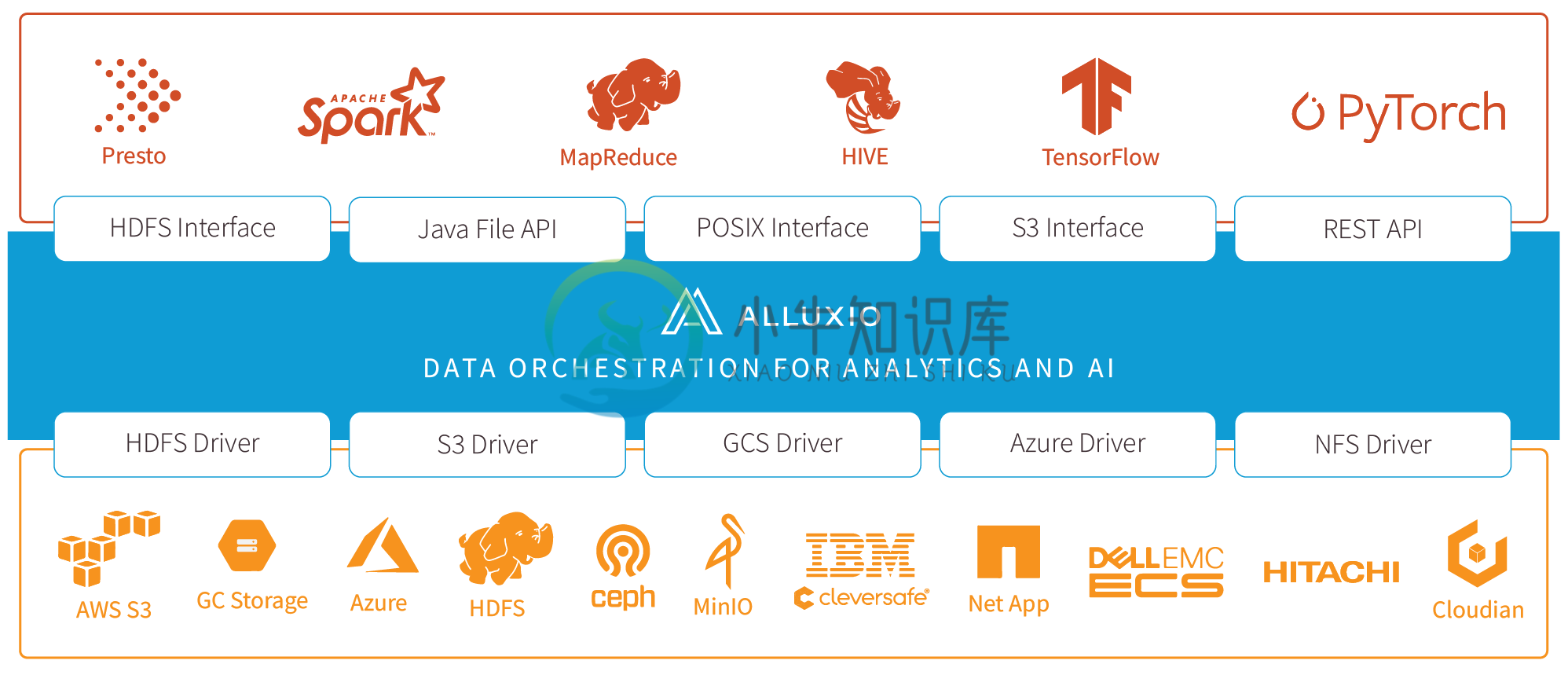
在大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和 Alibaba OSS)之间。 Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。
Alluxio 项目源自 UC Berkeley 的 AMPLab(见论文),在伯克利数据分析栈 (Berkeley Data Analytics Stack, BDAS) 中扮演数据访问层的角色。 它以 Apache License 2.0 协议的方式开源。 Alluxio 是发展最快的开源大数据项目之一,已经吸引了超过 300 个组织机构的1200多名贡献者参与到 Alluxio 的开发中,包括 阿里巴巴、 Alluxio、 百度、 CMU、 Google、 IBM、 Intel、 南京大学、 Red Hat、 腾讯、 UC Berkeley、 和 Yahoo。
到今天为止,Alluxio 已经在数百家机构的生产中进行了部署,最大部署运行的集群规模超过 1500 个节点。
优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio 能够帮助克服从数据中提取信息所面临的困难。Alluxio 的优势包括:
-
内存速度 I/O:Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
-
简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从 Alluxio 中检索读取数据,而不是从底层云存储或对象存储中检索读取。
-
简化数据管理:Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS,并且无需复杂的系统配置和管理。
-
应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 生态系统兼容,现有的数据分析应用程序,如 Spark 和 MapReduce 程序,无需更改任何代码就能在 Alluxio 上运行。
技术创新
Alluxio 将三个关键领域的创新结合在一起,提供了一套独特的功能。
- 全局命名空间:Alluxio 能够对多个独立存储系统提供单点访问,无论这些存储系统的物理位置在何处。这提供了所有数据源的统一视图和应用程序的标准接口。有关详细信息,请参阅统一命名空间文档。
- 智能多层级缓存:Alluxio 集群能够充当底层存储系统中数据的读写缓存。可配置自动优化数据放置策略,以实现跨内存和磁盘(SSD/HDD)的性能和可靠性。缓存对用户是透明的,使用缓冲来保持与持久存储的一致性。有关详细信息,请参阅 缓存功能文档。
- 服务器端 API 翻译转换:Alluxio支持工业界场景的API接口,例如HDFS API, S3 API, FUSE API, REST API。它能够透明地从标准客户端接口转换到任何存储接口。Alluxio 负责管理应用程序和文件或对象存储之间的通信,从而消除了对复杂系统进行配置和管理的需求。文件数据可以看起来像对象数据,反之亦然。
快速上手指南
如果打算快速地搭建 Alluxio 并运行,请阅读快速上手指南页面,该页面描述了如何部署 Alluxio 并在本地环境下运行示例。
下载
你可以从 Alluxio 下载页面获取已发布版本。 每个Alluxio发布版本都提供了与不同 Hadoop 版本兼容的预编译好的二进制文件。 从 Master 分支构建 Alluxio页面解释了如何从源代码编译生成Alluxio项目。 如果你有任何疑问,请联系我们用户邮件列表 或者我们的社区Slack频道。
新媒体渠道
如果还想了解更多关于Alluxio的信息,欢迎关注Alluxio新媒体平台
-
一、什么是Alluxio Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。 在大数据生态系统中,Alluxio介于计算框架(如Apache
-
分布式缓存:Alluxio 已经有的开源为什么还要进行开发: 基于开源来做的一个内部应用场景,就像sylph一样(也是开源的) 最终的目标: 1.为HDFS迁移未来一段时间数据的跨机房访问做缓冲; 2.对同机房数据的访问做加速缓冲; 什么是Alluxio: ->Alluxio是世界上第一个以内存为中心的虚拟的分布式存储系统(面向基于云的数据分析和人工智能
-
一、搭建Alluxio集群 1、前期准备 设置不需要密码的从master节点到worker节点的SSH登录,开放所有节点之间的TCP通信。 2、下载解压 下载预编译的Alluxio二进制文件 alluxio-2.7.3-bin.tar.gz,使用以下命令解压缩 tar -xvzpf alluxio-2.7.3-bin.tar.gz 3、基本配置 在master节点上,先创建alluxio-env.
-
准备 下载文件:wget https://downloads.alluxio.io/downloads/files/2.8.0/alluxio-2.8.0-bin.tar.gz 解压目录:/opt/servers/alluxio 创建目录:mkdir -p /mnt/ramdisk 机器:192.168.3.21(master,worker)192.168.3.22(master,worker)1
-
诸葛io提供了非常完备的数据接入方案,支持代码埋点、全埋点、可视化埋点、服务端埋点等多种数据采集方式。您可以根据您的需求搭配选择最合适的数据采集方式,方便快捷的使用诸葛io。 一、接入流程 我们建议您采用如下接入流程,如果您有其他需求,也可联系诸葛io数据驱动顾问和技术支持 了解诸葛io的数据模型,具体可参照诸葛io数据模型 业务人员梳理产品/运营需求,确定业务数据指标,初步罗列出数据采集文档,主
-
我能够使用cloudera提供的示例jar在alluxio上运行wordcount,使用: 但是当我使用附带代码创建的jar时,我不能运行它,这也是一个示例wordcount示例代码 上面的代码是使用maven pom.xml文件构建的 你能帮我在alluxio集群中运行我的wordcount程序吗。希望没有额外的配置添加到pom文件运行相同。
-
时间线:9.22投递-------->9.26笔试-------->9.28闪电AI面试-------->10.12技术面(20min) 闪电AI面试: 一共六个问题,五个开放性问题(包括自我介绍,优势劣势,项目的难点,如何解决的,项目中收获等)一个英文朗读 技术面(五个面试官,但是主要是两位面试官分别从技术和项目两个角度进行提问): 自我介绍 详细介绍一下第一个项目(场景,需求,解决的问题,如何
-
我使用prestodb和hive metastore作为模式存储,使用alluxio缓存作为数据的外部存储。alluxio和hive模式中使用的存储格式是PARQUET。同时使用配置单元目录从presto检索时间戳字段。我会跟踪错误。 列 utdate 声明为类型时间戳,但 Parquet 文件将列声明为 INT64 类型 数据集的架构为 创建表测试( utcdate timestamp ) WI
-
本文向大家介绍编写Golang程序以检查给定数组是否已排序(使用冒泡排序技术),包括了编写Golang程序以检查给定数组是否已排序(使用冒泡排序技术)的使用技巧和注意事项,需要的朋友参考一下 例子 输入arr = [7、15、21、26、33] =>数组已排序。 输入arr = [7,5,1,6,3] =>数组未排序。 解决这个问题的方法 步骤1:将数组从第0个索引迭代到n-1。 步骤2:将数组从
-
通过Helm编排一键部署虚拟机实例和容器实例。 编排使用流程: 在Helm仓库中对接虚拟机类型和容器类型等Helm仓库。 在应用市场中选择虚拟机类型或容器类型的应用部署。 部署容器类型应用前需要在容器中创建容器集群以及命名空间等。 部署虚拟机类型应用前请确保平台中有“CentOS-7.6.1810-20190430.qcow2”镜像、可用宿主机或公有云/私有云云账号等。 虚拟机实例 用于管理通过编