
FastDFS是一个开源的分布式文件系统,她对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的meta data进行管理。所谓文件的meta data就是文件的相关属性,以键值对(key value pair)方式表示,如:width=1024,其中的key为width,value为1024。文件meta data是文件属性列表,可以包含多个键值对。
FastDFS系统结构如下图所示:
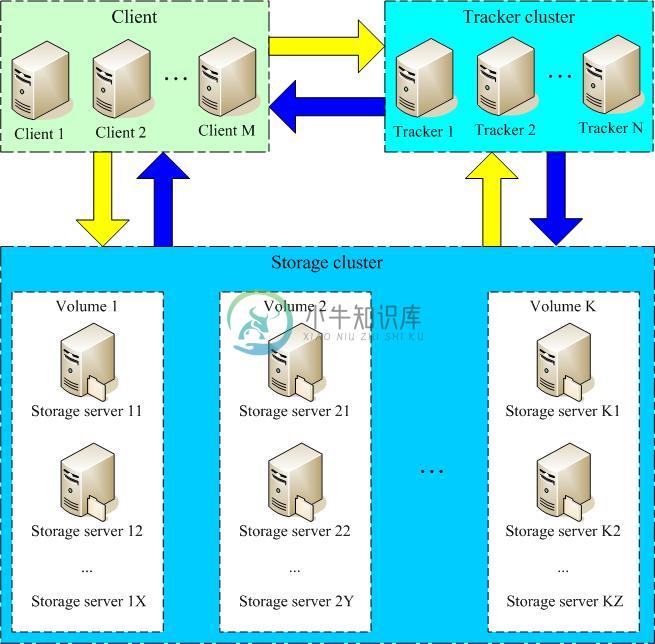
跟踪器和存储节点都可以由一台多台服务器构成。跟踪器和存储节点中的服务器均可以随时增加或下线而不会影响线上服务。其中跟踪器中的所有服务器都是对等的,可以根据服务器的压力情况随时增加或减少。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷 的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起 到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。
当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
FastDFS中的文件标识分为两个部分:卷名和文件名,二者缺一不可。
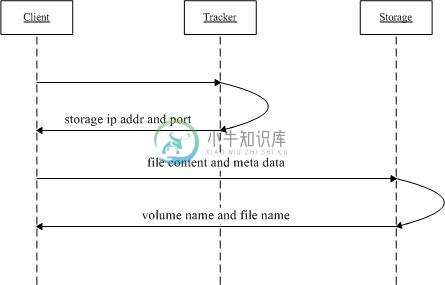
FastDFS file upload
上传文件交互过程:
1. client询问tracker上传到的storage,不需要附加参数;
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件上传。

FastDFS file download
下载文件交互过程:
1. client询问tracker下载文件的storage,参数为文件标识(卷名和文件名);
2. tracker返回一台可用的storage;
3. client直接和storage通讯完成文件下载。
需要说明的是,client为使用FastDFS服务的调用方,client也应该是一台服务器,它对tracker和storage的调用均为服务器间的调用。
-
一. 什么是FastDFS 1.介绍FastDFS FastDFS是用c语言编写的一款开源的分布式文件系统,它是由淘宝资深架构师余庆编写并开源。FastDFS专为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS很 容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务 2.为什么要使用FastDFS 上边介绍的NFS、GFS都是通用的
-
问题内容: 题 我正在寻找Java内存对象缓存API。有什么建议吗?您过去使用过什么解决方案? 当前 现在,我只是在使用地图: 要求 我需要扩展缓存以包括以下基本功能: 最大尺寸 生存时间 但是,我不需要更复杂的功能,例如: 来自多个进程的访问(缓存服务器) 持久性(到磁盘) 意见建议 内存中缓存: Guava CacheBuilder-活动开发。请参阅此演示文稿。 LRUMap-通过API配置。
-
每个 Redisson 对象都绑定到一个 Redis 键(即对象名称),且可以通过 getName 方法读取。 RMap map = redisson.getMap("mymap"); map.getName(); // = mymap 所有和 Redis 键相关的操作被抽象到了 RKeys 接口: RKeys keys = redisson.getKeys(); Iterable<String>
-
jvm的对象头是如何存储的? 对象头中有哪些信息? 对象头里面的东西:运行时元数据,类型指针:Hashcode,GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时间戳。如果是数组的化还需要记录长度 就比如下面的代码来看,内存分布情况: 由于是static的main方法所有局部变量表没有this,如果是非静态方法的话第一个放this。 其次: 栈帧:局部变量表,操作数栈,动态链接,方法返回
-
问题内容: 是否有一个提供发布/订阅模式的Java轻量级框架? 一些理想的功能 支持泛型 向发布者注册多个订阅者 API主要是接口和一些有用的实现 完全不需要内存,持久性和事务保证。 我了解JMS,但这对我来说太过分了。发布/订阅的数据是文件系统扫描的结果,扫描结果被馈送到另一个组件进行处理,然后在将其馈给另一个组件之前进行处理,依此类推。 编辑:所有在同一过程中。bean的PropertyCha
-
问题内容: 我正在寻找Java分布式缓存解决方案。我们希望功能喜欢: 我们已经分析了Terracotta这样的框架,它似乎是缓存框架中我们想要的一切……但是,似乎需要一个中央缓存节点,这成为我们的单点故障。 除了推出我们自己的解决方案之外,还有其他想法吗? 问题答案: 我建议使用JBossCache或EhCache(使用分布式缓存侦听器)。我都用过,我都喜欢,它们都适合您的要求。
-
我们可以通过下面的简单算法实现该目的: 检查本地缓存的键(key); 如果本地缓存存在该键,则返回它的值; 如果本地缓存不存在该键,则尝试在分布式缓存中找; 如果分布式缓存存在该键,则返回它的值并把它添加到本地缓存; 如果分布式缓存不存在该键,则从数据库中获取,并添加到本地和分布式缓存,最后返回该值。 当在本地缓存服务器中缓存一些信息时,使用这种方式,它还将信息缓存到分布式缓存,但这一次,如果其他
-
null 解压缩算法的重要指标是数据的大小加上算法的大小(因为它们将驻留在相同的有限内存中)。 可用于解压的RAM很少;可以将单个字形的数据解压缩到RAM中,但不能更多。 为了使事情变得更加困难,算法必须在32位微控制器(ARM Cortex-M core)上非常快,因为字形在被绘制到显示器上时需要解压缩。每八位元组十个或二十个机器循环是可以的,一百个肯定太多了。 为了使事情变得更容易,完整的数据
-
Web 应用程序可能需要为成百上千甚至更多的用户同时提供服务。如果你没有采取必要的措施,在这种负载下,你的网站可能会崩溃或变得没有响应。 假设在主页显示最后 10 条新闻,并且平均每分钟有上千名用户访问此页面。你可能为每个用户通过查询数据库来显示页面视图信息: SELECT TOP 10 Title, NewsDate, Subject, Body FROM News ORDER BY NewsD