
HTML转义字符&npsp;表示non-breaking space \xa0

1.参考
Beautiful Soup and Unicode Problems
详细解释
unicodedata.normalize('NFKD',string) 实际作用???
Scrapy : Select tag with non-breaking space with xpath
>>> selector.xpath(u''' ... //p[normalize-space()] ... [not(contains(normalize-space(), "\u00a0"))]
normalize-space() 实际作用???
In [244]: sel.css('.content')
Out[244]: [<Selector xpath=u"descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' content ')]" data=u'<p class="content text-
BeautifulSoup下Unicode乱码解决
今天在用scrapy爬某个网站的数据,其中DOM解析我用的是BeautifulSoup,速度上没有XPath来得快,不过因为用了习惯了,所以一直用的bs,版本是bs4
不过在爬取过程中遇到了一些问题,其中一个是Unicode转码问题,这也算是python中一个著名问题了。
我遇到的算是BeautifulSoup中的一个奇葩bug吧,在网页中经常会有   这种标记,称为 non-breaking space character, 本来这个应该是忽略的,但在bs中会把这个符号
转义成为一个unicode编码 \xa0, 这就导致了后面如果要对内容处理的话会出现UnicodeError, 特别是如果使用的是Console或者scrapy中写文件、写数据库的pipeline操作时,
出现无法转义的错误。
那么该如何解决呢,其实不难
s = u'\xa0'
s.replace(u'\xa0', u'')
之后就可以对s进行encode,比如:
s = u'\xa0'
s.replace(u'\xa0', u'').encode('utf-8')
特别是在我的项目中,如果需要把数据写到MongoDB中,这个bug fix完后,写数据立刻搞定,爬取的内容全部写到MongoDB中。
s.replace(u'\xa0', u'').encode('utf-8')
2.问题定位
https://en.wikipedia.org/wiki/Comparison_of_text_editors
定位元素显示为 &npsp;
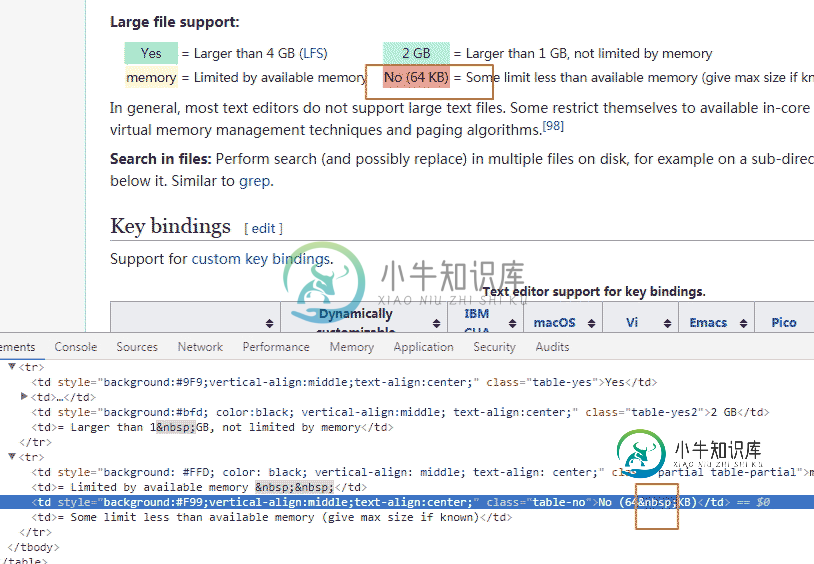
网页源代码表示为  
<tr> <td style="background: #FFD; color: black; vertical-align: middle; text-align: center;" class="partial table-partial">memory</td> <td>= Limited by available memory   </td> <td style="background:#F99;vertical-align:middle;text-align:center;" class="table-no">No (64 KB)</td> <td>= Some limit less than available memory (give max size if known)</td> </tr> </table>
实际传输Hex为:

不间断空格的unicode表示为 u\xa0',保存的时候编码 utf-8 则是 '\xc2\xa0'
In [211]: for tr in response.xpath('//table[8]/tr[2]'):
...: print [u''.join(i.xpath('.//text()').extract()) for i in tr.xpath('./*')]
...:[u'memory', u'= Limited by available memory \xa0\xa0', u'No (64\xa0KB)', u'= Some limit less than available memory (give max size if known)']
In [212]: u'No (64\xa0KB)'.encode('utf-8')
Out[212]: 'No (64\xc2\xa0KB)'In [213]: u'No (64\xa0KB)'.encode('utf-8').decode('utf-8')
Out[213]: u'No (64\xa0KB)'
保存 csv 直接使用 excel 打开会有乱码(默认ANSI gbk 打开???,u'\xa0' 超出 gbk 能够编码范围???),使用记事本或notepad++能够自动以 utf-8 正常打开。

使用记事本打开csv文件,另存为 ANSI 编码,之后 excel 正常打开。超出 gbk 编码范围的替换为'?'

3.如何处理
.extract_first().replace(u'\xa0', u' ').strip().encode('utf-8','replace')
以上就是HTML转义字符&npsp;表示non-breaking space \xa0的详细内容,更多关于HTML转义字符\xa0的资料请关注小牛知识库其它相关文章!
-
反转义 HTML 字符。 使用带有正则表达式的 String.replace() 来匹配需要被转义的字符,使用一个回调函数使用字典(对象)替换每个 HTML 实体字符为其关联的非转义字符。 const unescapeHTML = str => str.replace( /&|<|>|'|"/g, tag => ({ '
-
转义一个字符串,以用于HTML。 使用带有正则表达式的 String.replace() 来匹配需要转义的字符,使用一个回调函数使用字典(对象)替换每个字符为器关联的 HTML 实体字符。 const escapeHTML = str => str.replace( /[&<>'"]/g, tag => ({ '&': '&',
-
问题内容: 如何打印字符串的转义表示形式,例如,如果我有: 我希望输出: 在屏幕上而不是 问题答案: 我认为您正在寻找: 从Apache Commons Lang v2.6 在Apache Commons Lang v3.5 +中已弃用,请使用Apache Commons Text v1.2
-
问题内容: 有谁知道一种简单的方法来从jQuery的字符串中转义HTML ?我需要能够传递任意字符串并正确地对其进行转义以显示在HTML页面中(防止JavaScript / HTML注入攻击)。我敢肯定可以扩展jQuery来做到这一点,但是目前我对框架还不了解。 问题答案: 由于您使用的是jQuery,因此只需设置元素的属性即可:
-
问题内容: 它们是否与XML相同,也许还要加上空格()? 我发现的HTML转义字符一些大名单,但我不认为他们 必须 进行转义。我想知道 需要 逃避什么。 问题答案: 如果你在文本内容预期的位置在文档中插入文本内容1,你通常只需要,你会在XML逃脱相同的字符。在元素内部,这仅包括实体转义与号和元素定界符小于和大于符号 : 在属性值内部,还必须转义使用的引号字符: 在某些情况下,跳过这些字符中的某些字
-
我有一个标准的json结构,里面有这样的内容