
使用python对文件中的单词进行提取的方法示例

由于需要使用一个纯单词组成的文件,在网上下载到了一个存放单词的文件,但是里面有中文的解释,那就需要做一下提取了。
文本的形式如下:

所见即所得,这个文本是有规律的,每个单词为一行,紧接着下一行便是单词的解释,有了这种规律我们就很好处理了。
首先我们来将文件的数据读取出来:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
print line
代码执行的结果为:
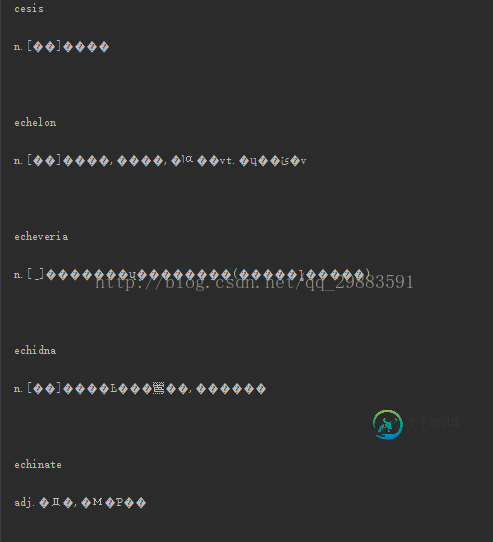
显然,这不是我们想要的结果,因为这里面有太多的空行了,现在最主要的就是要处理掉这些妨碍我们的空行,对于中文的乱码呢,我们是不需要中文的解释的,所以它是无妨碍的,如果想看得舒服些,那么我们就转码一下就好了。现在最主要的就是要知道为什么会出现这么多的空行,因为我们的文件是已将看过了,显然是这些空行的出现是有点“匪夷所思”的,这也是由于python读文件的机制导致的,下面我们修改下代码,来看看原因:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
print lines
在这里,我们直接输出lines,得到如下的结果:

我们随意拿出这句'runlet\n', 'n.\xcd\xb0,\xd0\xa1\xba\xd3\n', '\n', 'runnel\n', 'n.\xd0\xa1\xba\xd3,\xcf\xb8\xc1\xf7\n', '\n',从中可以看出,对于每行的文件,在读取的时候,换行符“\n”也是会被读取在单词和对应的解释的后面的,所以这也就是为什么会有那么多空行的原因了,这显然不是我们想要看见的,下面我们处理一下,让这些多余的空行失去效果:
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
for line in lines:
if line!='\n':
print line.decode('gb2312','ignore'), #逗号得带着,因为文件自身带了换行,可以代替pirnt的换行
程序执行后,得到如下的结果:

好了,这下就是我们想看到的东西了,那么,现在我们可以将这些输出写入 到新的文件里了,然后就可以得到我们想要的单词文本了。
#coding:utf-8
file_object = open('words.txt')
try:
lines = file_object.readlines()
finally:
file_object.close( )
myfile=open('newfile.txt','w')
num=0
for word in lines:
if word!='\n':
num+=1
if num%2: #只有奇数行为单词
myfile.write(word)
运行程序便可以得到新的单词文件了,最终提取了45000多个单词,文件如下所示:
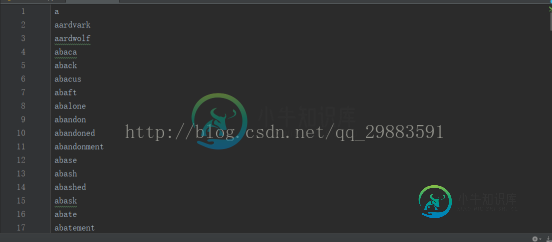
很显然,满足我们最终想要实现的要求,那么可以收工了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我想读一个文本文件,打印出已知单词前面的单词,比如Java中的xxx。我使用Scanner类用java编写了这段代码。但是这段代码只打印了“xxx”前面的一半单词,而“xxx”前面的一些单词则丢失了。我想知道是什么问题,你能解决这个代码吗。 测试文件包含类似的内容
-
问题内容: 鉴于: 是否有一个正则表达式可以同时抓取(最多)两个单词,例如: 结果: 这个问题是关于 分割正则表达式的 。这与“找到解决方法”或其他“使其以其他方式工作”解决方案 无关 。 问题答案: 当前(最近在Java 14上进行了测试)可以使用,但在现实世界中不要使用此方法,因为它看起来像是基于错误的,因为Java中的后向应该具有明显的最大长度,但是此解决方案使用不遵守此限制的方法,并且仍然
-
问题内容: 我正在使用python,NLTK和WordNetLemmatizer进行lemmatizer。这是输出我期望的随机文本 输出: 输出: 好吧,这里的一切都很好。其行为与其他形容词一样(对于(不规则形式)或)(请注意,相同的测试将永远不会输出,但我想wordnet并不是所有现有英语单词的详尽列表) 我的问题是尝试使用以下单词时出现的: 输出: 输出: 这是与单词相反的行为! 谁能解释我为
-
问题内容: 假设您有一个像这样的文本文件:http : //www.gutenberg.org/files/17921/17921-8.txt 有没有人有一个好的算法或开放源代码从文本文件中提取单词?如何获得所有单词,同时避免使用特殊字符,并保留诸如“ it’s”之类的内容… 我在用Java工作。谢谢 问题答案: 这听起来像是正则表达式的正确工作。如果您不知道如何开始,以下是一些Java代码,可以
-
问题内容: 文件: 我想使用脚本语言( BASH )以执行读取每个命令在上述,然后将其插入到一个。 然后循环到列表中的下一个单词(每个单词在新行中)。到达末尾时停止。 进度将类似于以下内容: 从上面先阅读 将单词插入命令 它将输出到文本文件;以word作为文件名。 重复此过程,但要紧挨着第n个(每行一个新行)。 到达上述末尾时终止过程。 以上BASH命令的结果 : 你好: 世界: 问题答案: 您可
-
本文向大家介绍使用Python进行二进制文件读写的简单方法(推荐),包括了使用Python进行二进制文件读写的简单方法(推荐)的使用技巧和注意事项,需要的朋友参考一下 总的感觉,python本身并没有对二进制进行支持,不过提供了一个模块来弥补,就是struct模块。 python没有二进制类型,但可以存储二进制类型的数据,就是用string字符串类型来存储二进制数据,这也没关系,因为string是