
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解

基本思路:
首先用开发者工具找到需要提取数据的标签列
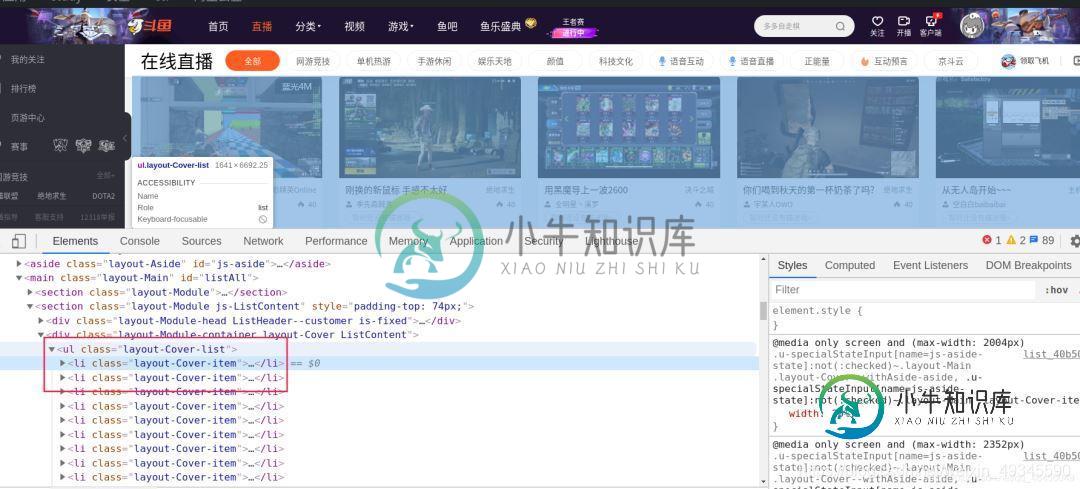
利用xpath定位需要提取数据的列表
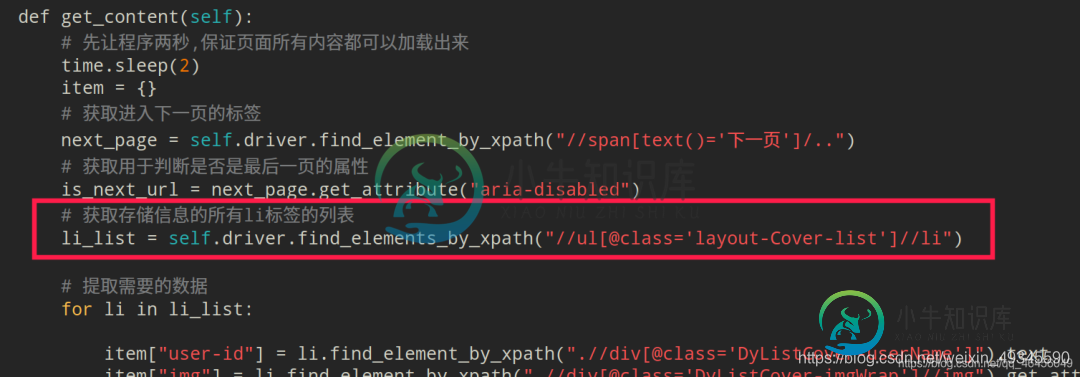
然后再逐个提取相应的数据:
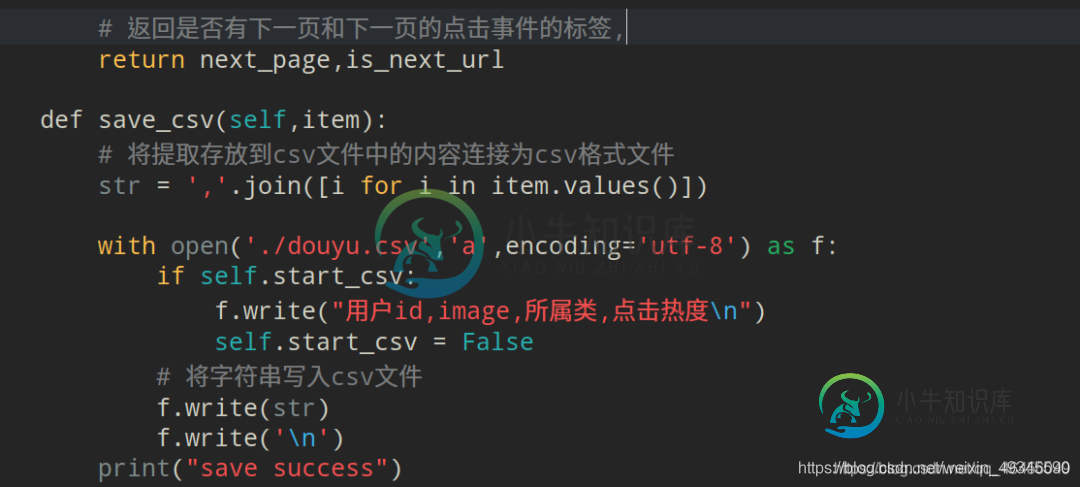
保存数据到csv:
利用开发者工具找到下一页按钮所在标签:
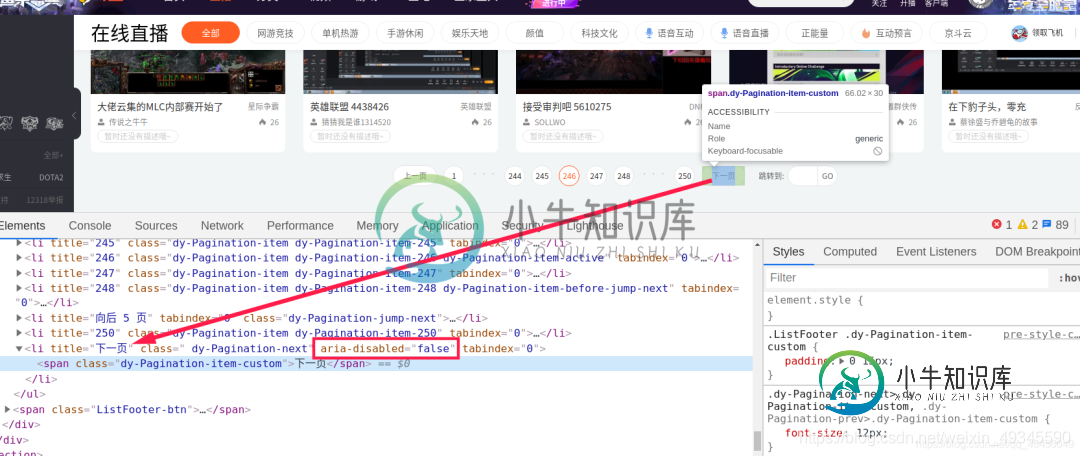
利用xpath提取此标签对象并返回:

调用点击事件,并循环上述过程:
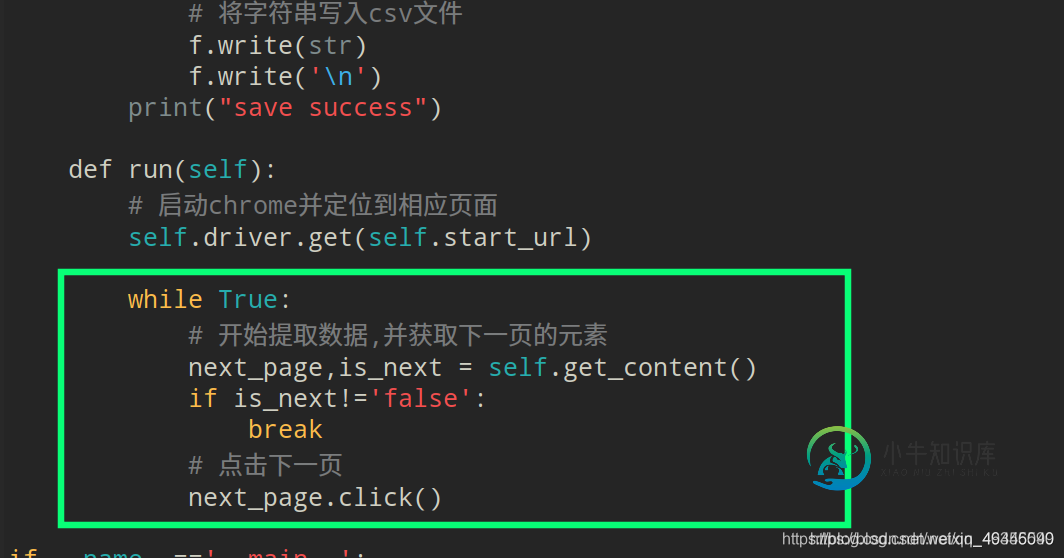
最终效果图:
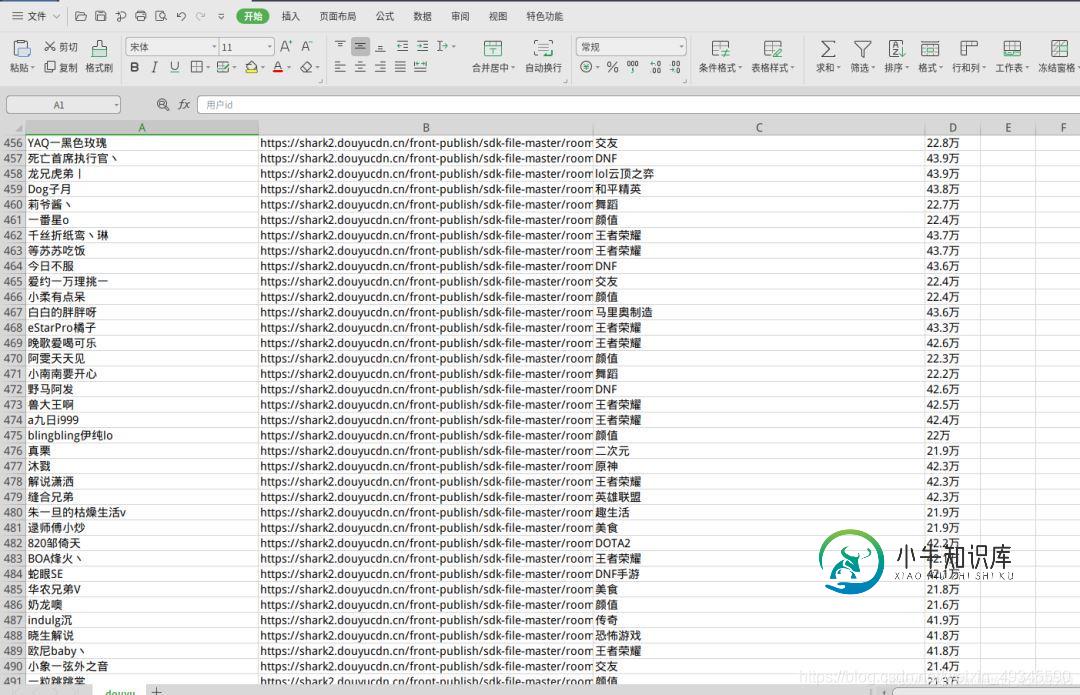
代码:
from selenium import webdriver
import time
import re
class Douyu(object):
def __init__(self):
# 开始时的url
self.start_url = "https://www.douyu.com/directory/all"
# 实例化一个Chrome对象
self.driver = webdriver.Chrome()
# 用来写csv文件的标题
self.start_csv = True
def __del__(self):
self.driver.quit()
def get_content(self):
# 先让程序两秒,保证页面所有内容都可以加载出来
time.sleep(2)
item = {}
# 获取进入下一页的标签
next_page = self.driver.find_element_by_xpath("//span[text()='下一页']/..")
# 获取用于判断是否是最后一页的属性
is_next_url = next_page.get_attribute("aria-disabled")
# 获取存储信息的所有li标签的列表
li_list = self.driver.find_elements_by_xpath("//ul[@class='layout-Cover-list']//li")
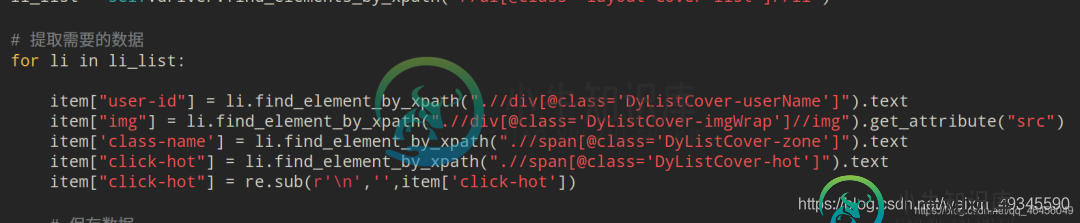
# 提取需要的数据
for li in li_list:
item["user-id"] = li.find_element_by_xpath(".//div[@class='DyListCover-userName']").text
item["img"] = li.find_element_by_xpath(".//div[@class='DyListCover-imgWrap']//img").get_attribute("src")
item['class-name'] = li.find_element_by_xpath(".//span[@class='DyListCover-zone']").text
item["click-hot"] = li.find_element_by_xpath(".//span[@class='DyListCover-hot']").text
item["click-hot"] = re.sub(r'\n','',item['click-hot'])
# 保存数据
self.save_csv(item)
# 返回是否有下一页和下一页的点击事件的标签,
return next_page,is_next_url
def save_csv(self,item):
# 将提取存放到csv文件中的内容连接为csv格式文件
str = ','.join([i for i in item.values()])
with open('./douyu.csv','a',encoding='utf-8') as f:
if self.start_csv:
f.write("用户id,image,所属类,点击热度\n")
self.start_csv = False
# 将字符串写入csv文件
f.write(str)
f.write('\n')
print("save success")
def run(self):
# 启动chrome并定位到相应页面
self.driver.get(self.start_url)
while True:
# 开始提取数据,并获取下一页的元素
next_page,is_next = self.get_content()
if is_next!='false':
break
# 点击下一页
next_page.click()
if __name__=='__main__':
douyu_spider = Douyu()
douyu_spider.run()
到此这篇关于python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解的文章就介绍到这了,更多相关python爬虫实现自动翻页爬取某鱼数据内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
本文向大家介绍python爬虫实现爬取同一个网站的多页数据的实例讲解,包括了python爬虫实现爬取同一个网站的多页数据的实例讲解的使用技巧和注意事项,需要的朋友参考一下 对于一个网站的图片、文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错。Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取。本文小编带领大家通过python爬虫获取获取总页数并更改url的方法,实
-
本文向大家介绍利用C#实现网络爬虫,包括了利用C#实现网络爬虫的使用技巧和注意事项,需要的朋友参考一下 网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具。 接下来就介绍一下爬虫的简单实现。 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载完毕为止。 下面开始逐步分析爬虫的实现。 1. 待下载集合与已下载集合 为了保存需要下载的URL
-
本文向大家介绍python爬虫实现中英翻译词典,包括了python爬虫实现中英翻译词典的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python爬虫实现中英翻译词典的具体代码,供大家参考,具体内容如下 通过根据某平台的翻译资源,提取出翻译信息,并展示出来,包括输入,翻译,输出三个过程,主要利用python语言实现(python3.6),抓取信息展示。 以上就是本文的全部内容,希望对
-
本文向大家介绍Python使用爬虫爬取静态网页图片的方法详解,包括了Python使用爬虫爬取静态网页图片的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python使用爬虫爬取静态网页图片的方法。分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了。这篇就清晰地讲解一下利用Python爬虫的理论基础。 首
-
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
本文向大家介绍scrapy实践之翻页爬取的实现,包括了scrapy实践之翻页爬取的实现的使用技巧和注意事项,需要的朋友参考一下 安装 Scrapy的安装很简单,官方文档也有详细的说明 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 。这里不详细说明了。 在scrapy框架中,spider具有以下几个功能 1. 定义初始爬
-
本文向大家介绍Python爬虫爬取美剧网站的实现代码,包括了Python爬虫爬取美剧网站的实现代码的使用技巧和注意事项,需要的朋友参考一下 一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间。之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了。但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷