
pandas中read_csv、rolling、expanding用法详解

如下所示:
import pandas as pd
from pandas import DataFrame
series = pd.read_csv('daily-min-temperatures.csv',header=0, index_col=0,
parse_dates=True,squeeze=True)
temps = DataFrame(series.values)
width = 3
shifted = temps.shift(width-1)
print(shifted)
window = shifted.rolling(window=width)
dataframe = DataFrame()
dataframe = pd.concat([window.min(),window.mean(),window.max(),temps],axis=1)
dataframe.columns=['min','mean','max','t+1']
print(dataframe.head(5))
read_csv中参数用法:
当设置 header=None 时,则认为csv文件没有列索引,为其添加相应范围的索引,range(1,1200)指建立索引号从1开始最大到1199的列索引,当数据长度超过范围时,索引沿列数据的右侧对齐。
obj=pd.read_csv('testdata.csv',header=0,names=range(1,4))
当设置 header=0 时,则认为csv文件数据第一行是列索引,将用新的列索引替换旧的列索引。
obj=pd.read_csv('testdata.csv',index_col=0,usecols=[1,2,3])
当设置 index_col=0 时,则是csv文件数据的指定数据中的第一列是行索引,usecols指选中数据的对应列数,[1,2,3]指第2列到第4列。
obj=pd.read_csv('testdata.csv',index_col=0,usecols=5)
用usecols选择前n行数据进行后续处理,n为正整型。
rolling用法:
源代码
def rolling(self, *args, **kwargs): """ Return a rolling grouper, providing rolling functionality per group. """ from pandas.core.window import RollingGroupby return RollingGroupby(self, *args, **kwargs) @Substitution(name="groupby") @Appender(_common_see_also)
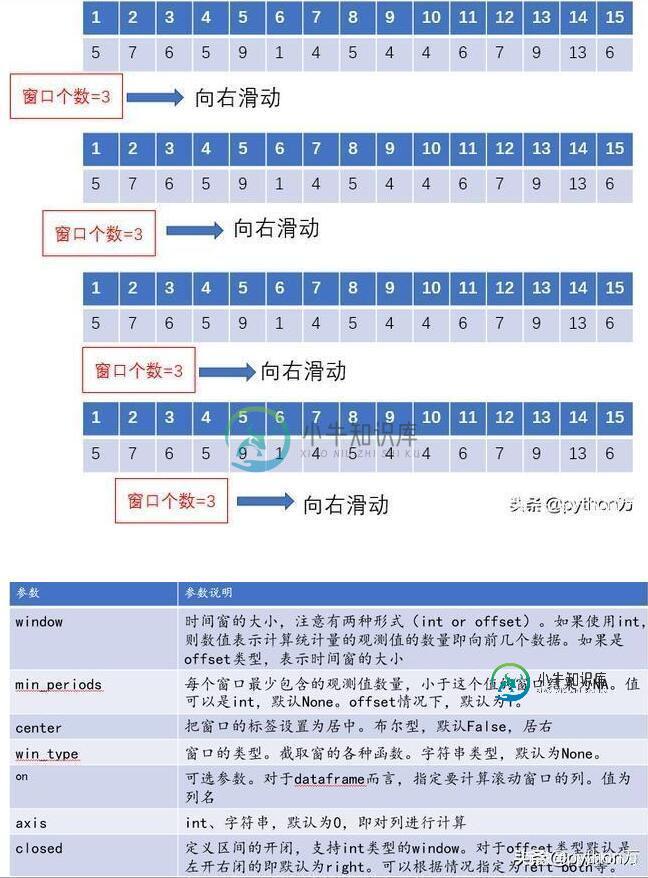
用法代码演示
上面我们介绍了滑动窗口的概念及实现函数的参数,下面我们通过代码演示,依次展示各参数的作用。
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
index=pd.date_range('20190116','20190130')
data=[4,8,6,5,9,1,4,5,2,4,6,7,9,13,6]
ser_data=pd.Series(data,index=index)
print(ser_data)
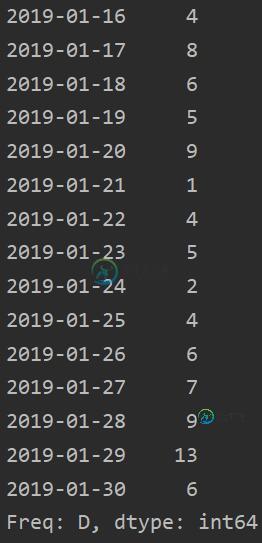
加入rolling使用时间窗后及具体原理
ser_data.rolling(3).mean()

min_periods用法
如上图所示,当窗口开始滑动时,第一个时间点和第二个时间点的时间为空,这是因为这里窗口长度为3,他们前面的数都不够3,所以到2019-01-18时,他的数据就是2019-01-16到2019-01-18三天的均值。那么有人就会这样想,在计算2019-01-16序列的窗口数据时,虽然不够窗口长度3,但是至少有当天的数据,那么能否就用当天的数据代表窗口数据呢?答案是肯定的,这里我们可以通过min_periods参数控制,表示窗口最少包含的观测值,小于这个值的窗口长度显示为空,等于和大于时有值,如下所示:
表示窗口最少包含的观测值为1
ser_data.rolling(3,min_periods=1).mean()
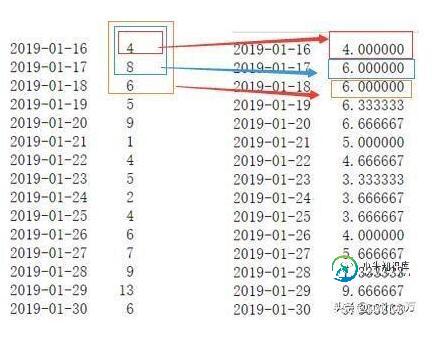
expanding用法
征用前面全部的数据

代码详解
import pandas as pd
from pandas import DataFrame
series = pd.read_csv('daily-min-temperatures.csv',header=0, index_col=0,
parse_dates=True,squeeze=True)
temps = DataFrame(series.values)
window = temps.expanding()
dataframe = DataFrame()
dataframe = pd.concat([window.min(),window.mean(),window.max(),temps.shift(-1)],axis=1)
dataframe.columns=['min','mean','max','t+1']
print(dataframe.head(5))
输出结果
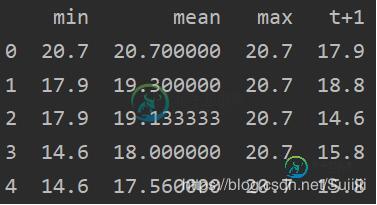
expanding可去除NaN值
以上这篇pandas中read_csv、rolling、expanding用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍pandas 测试read_csv,包括了pandas 测试read_csv的使用技巧和注意事项,需要的朋友参考一下 示例
-
问题内容: 因此,我正在从NOAA读取站代码csv文件,如下所示: 前两列包含气象站代码,有时它们的前导零。当熊猫在未指定dtype的情况下导入它们时,它们将变成整数。没什么大不了的,因为我可以遍历数据帧索引并用类似的东西替换它们,”%06d” % i因为它们始终是六位数字,但是您知道…这是懒惰的方式。 使用以下代码获取csv: 一切都很好,但是当我尝试使用此方法阅读时: 要么 我收到一个讨厌的错
-
问题内容: 我有一个csv文件,当我使用过滤列并使用多个索引时,该文件输入不正确。 我希望df1和df2除了丢失的虚拟列外应该相同,但这些列的标签错误。日期也被解析为日期。 使用列号而不是名称给我同样的问题。我可以通过在read_csv步骤之后删除虚拟列来解决此问题,但是我试图了解出了什么问题。我正在使用熊猫0.10.1。 编辑:修复错误的标头用法。 问题答案: @chip的答案完全错过了两个关键
-
我从数据帧创建了一个文件,如下所示: 数据帧中的数据类型 给出: 当我尝试使用读取新创建的文件时,它会给我错误: Dtype警告:列(5)具有混合类型。在导入时指定 dtype 选项或设置 low_memory=False。交互性=交互性,编译器=编译器,结果=结果) 如何避免此错误?出现此错误是因为我在或时做错了什么吗?
-
现在,返回另一个的方法,如上面MWE中的,返回另一个,这很好。但是,我还希望欺骗链接方法,如或在最后生成一个。到目前为止,我失败了,因为和类似的类型是,而我的包装器试图从它们的输出中构造,而不“等待”或表达式的任何其他最后部分。有什么想法可以解决这个问题吗? 谢了。
-
EXPANDING COLLECTION ExpandingCollection is a material design card peek/pop controller We specialize in the designing and coding of custom UI for Mobile Apps and Websites. Stay tuned for the latest up
-
本文向大家介绍对pandas中apply函数的用法详解,包括了对pandas中apply函数的用法详解的使用技巧和注意事项,需要的朋友参考一下 最近在使用apply函数,总结一下用法。 apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素。 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了
-
本文向大家介绍解决pandas使用read_csv()读取文件遇到的问题,包括了解决pandas使用read_csv()读取文件遇到的问题的使用技巧和注意事项,需要的朋友参考一下 如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.