
最佳的JavaScript错误处理实践

不管你的技术水平如何,错误或异常是应用程序开发者生活的一部分。Web开发的不连贯性留下了许多错误能够发生并确实已经发生的地方。解决的关键在于处理任何不可预见的(或可预见的错误),来控制用户的体验。利用JavaScript,就有多种技术和语言特色可以用来正确地解决任何问题。
在 JavaScript 中处理错误很危险。如果你相信墨菲定律,会出错的终究会出错!在这篇文章中,我会深入研究 JavaScript 中的错误处理。我会涉及到一些陷阱和好的实践。最后我们会讨论异步代码处理和 Ajax。
我认为 JavaScript 的事件驱动模型给这门语言添加了丰富的含义。我认为这种浏览器的事件驱动引擎和报错机制没什么区别。每当发生错误,就相当于在某个时间点抛出一个事件。理论上说,我们在 JavaScript 中可以像处理普通事件一样去处理抛错事件。如果对你来说这听起来很陌生,那请集中注意力开始学习下面的旅程。本文只针对客户端的 JavaScript。
示例
本文章中用到的代码示例在 GitHub 上可以得到,目前页面是这个样子的:

单击每个按钮都会引发一个错误。它模拟产生一个 TypeError 型的 exception。下面是对这样一个模块的定义及单元测试。
function error() {
var foo = {};
return foo.bar();
}
首先,这个函数定义了一个空的对象 foo。请注意,bar() 方法没有在任何地方定义。我们用单元测试来验证这确实会引发报错。
it('throws a TypeError', function () {
should.throws(target, TypeError);
});
这个单元测试使用 Mocha 和 Should.js 库中的测试断言。Mocha 是一个运行测试框架,should.js 是一个断言库。如果你不太熟悉,可以在线免费浏览他们的文档。一个测试用例通常以 it('description') 开始,以 should 中断言的通过或者失败结束。用这套框架的好处就是可以在 node 里进行单元测试,而不必非在浏览器里。我建议大家认真对待这些测试,因为它们验证了 JavaScript 中很多关键的基本概念。
如上所示, error() 定义了一个空对象,然后试图去调用其中的方法。因为在这个对象中不存在 bar() 这个方法,它会抛出一个异常。相信我,在像 JavaScript 这种动态语言里,任何人都有可能犯这类错误。
不好的示范
先来看看不佳的错误处理方式。我处理错误的动作抽象出来,绑定在按钮上。下面是处理程序的单元测试的样子:
function badHandler(fn) {
try {
return fn();
} catch (e) { }
return null;
}
这个处理函数接收一个回调函数 fn 作为依赖。接着在处理程序的内部调用了这个函数。这个单元测试示例了如何使用这个方法。
it('returns a value without errors', function() {
var fn = function() {
return 1;
};
var result = target(fn);
result.should.equal(1);
});
it('returns a null with errors', function() {
var fn = function() {
throw Error('random error');
};
var result = target(fn);
should(result).equal(null);
});
就像你看到的那样,如果发生了错误,这个诡异的处理方法会返回一个 null。这个回调函数 fn() 会指向一个合法的方法或者错误。下面的单击处理事件完成了剩下的部分。
(function (handler, bomb) {
var badButton = document.getElementById('bad');
if (badButton) {
badButton.addEventListener('click', function () {
handler(bomb);
console.log('Imagine, getting promoted for hiding mistakes');
});
}
}(badHandler, error));
糟糕的是我刚刚得到的是个 null。这让我在想确定到底发生了什么错误的时候非常迷茫。这种发生错误就沉默的策略覆盖了从用户体验设计到数据损坏的各个环节。随之而来令人沮丧的一面就是,我必须花费好几个小时调试但是却看不到 try-catch 代码块里的错误。这种诡异的处理隐藏掉了代码中所有的报错,它假设一切都是正常的。这在某些不注重代码质量的团队中,能够顺利的执行。但是,这些被隐藏的错误最终会迫使你花几个小时来调试代码。在一种依赖于调用栈的多层解决方案中,有可能可以确定错误来自于何处。可能在极少数情况下对 try-catch 做故障静默处理是合适的。但是如果遇到错误就去处理,也不是一个好方案。
这种失败即沉默的策略会促使你在代码中对错误做更好的处理。JavaScript 提供了更优雅的方式来处理这类问题。
不易读的方案
继续,接下来来看看不太好理解的处理方式。我将会跳过与 DOM 紧耦合的部分。这部分与我们刚刚看过的不好的处理方式没什么不同。重点是下面单元测试中处理异常的部分。
function uglyHandler(fn) {
try {
return fn();
} catch (e) {
throw Error('a new error');
}
}
it('returns a new error with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
should.throws(function () {
target(fn);
}, Error);
});
比起刚刚不好的处理方式,有一个很好的进步。异常在调用堆栈中被抛出。我喜欢的地方是错误从堆栈中解放出来,这对于调试有巨大的帮助。抛出一个异常,解释器就会在调用堆栈中一级级查看找到下一个处理函数。这就提供了很多机会在调用堆栈的顶层去处理错误。不幸的是,因为他是一种不太好理解的错误,我看不到了原始错误的信息。所以我必须沿着调用栈找过去,找到最原始的异常。但是至少我知道抛出异常的地方发生了一个错误。
这种不易读的错误处理虽然无伤大雅但是却使得代码难以理解。让我们看看浏览器如何处理错误的。
调用栈
那么,抛出异常的一种方式就是在调用堆栈的顶层添加 try...catch 代码块。比如说:
function main(bomb) {
try {
bomb();
} catch (e) {
// Handle all the error things
}
}
但是,记得我说过浏览器是事件驱动的吗?是的,JavaScript 中的一个异常不过就是一个事件。解释器会在发生异常当前的上下文处停止程序,并抛出异常。为了证实这一点,下面写了一个我们能够看到的全局的事件处理函数 onerror。它看上去就是这个样子:
window.addEventListener('error', function (e) {
var error = e.error;
console.log(error);
});
这个事件处理函数在执行环境中捕获错误。错误事件会在各种各样的地方产生各种错误。这种方式的重点是在代码中集中处理错误。就像其他的事件一样,你可以用一个全局的处理函数去处理各种不同的错误。这使得错误处理只有一个单一的目标,如果你遵守 SOLID (single responsibility 单一职责, open-closed 开闭, Liskov substitution 代换, interface segregation 界面分离 and dependency inversion 依赖倒置) 原则。你可以在任何时候注册错误处理函数。解释器会循环执行这些函数。代码从充满 try...catch 的语句中解放出来,变得易于调试。这种做法的关键是像处理 JavaScript 普通事件一样处理发生的错误。
现在,有了一种方法,用全局处理函数来显示出调用栈,我们可以用它来做什么?终究,我们要利用调用栈。
记录下调用栈
调用栈在处理修复 bug 上非常有用。好消息是浏览器提供了这个信息。就算目前,error 对象的 stack 属性并不是标准,但是在比较新的浏览器里都普遍支持这个属性。
所以,我们能够做的很酷的事情就是把它给服务器打印出来:
window.addEventListener('error', function (e) {
var stack = e.error.stack;
var message = e.error.toString();
if (stack) {
message += '\n' + stack;
}
var xhr = new XMLHttpRequest();
xhr.open('POST', '/log', true);
xhr.send(message);
});
在代码示例中可能不太明显,但这个事件处理程序会被前面的错误代码触发。如上所述,每个处理程序都有一个单一的目的,它使代码 DRY(don't repeat yourself 不重复制造轮子)。我感兴趣的是如何在服务器上捕获这些消息。
下面是 node 运行时的截图:
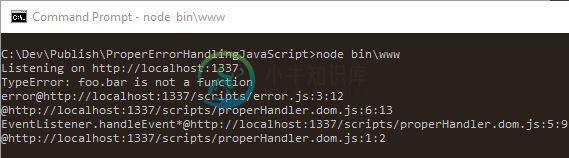
调用堆栈对调试代码很有帮助。永远不要低估调用栈的作用。
异步处理
哦,处理异步代码相当危险!JavaScript 将异步代码从当前的执行环境中带出来。这意味着下面这种 try...catch 语句有个问题。
function asyncHandler(fn) {
try {
setTimeout(function () {
fn();
}, 1);
} catch (e) { }
}
这个单元测试还有剩下的部分:
it('does not catch exceptions with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
failedPromise(function() {
target(fn);
}).should.be.rejectedWith(TypeError);
});
function failedPromise(fn) {
return new Promise(function(resolve, reject) {
reject(fn);
});
}
我必须用一个 promise 来结束这个处理程序,以验证异常。注意,尽管我的代码都在 try...catch 中,但是还是出现了未处理的异常。是的,try...catch 只在一个单独的执行环境中有作用。当异常被抛出时,解释器的执行环境已经不是当前的 try-catch 块了。这一行为的发生与 Ajax 调用相似。所以,现在有了两种选择。一种可选方案就是在异步回调中捕捉异常:
setTimeout(function () {
try {
fn();
} catch (e) {
// Handle this async error
}
}, 1);
这种方法虽然有用,但是还有很大的提升空间。首先,try...catch 代码块在代码中处处出现。事实上,上世纪 70 年代编程调用,他们希望他们的代码能够回退。另外,V8 引擎不鼓励 在函数中使用 try…catch 代码块 (V8 是 Chrome 浏览器和 Node 使用的 JavaScript 引擎)。他们推荐在调用堆栈顶层写这些捕获异常的代码块。
所以,这告诉我们什么?我上面说过的,在任何执行上下文中的全局错误处理程序是有必要的。如果你将一个错误处理程序添加到 window 对象,那就是说,您已经完成了!遵守 DRY 和 SOLID 的原则不是很好吗?一个全局错误处理程序将保持你的代码易读和干净。
下面就是服务器端异常处理打印的报告。注意,如果你使用的示例中的代码,输出的内容可能会根据你使用的浏览器不同有少许不同。
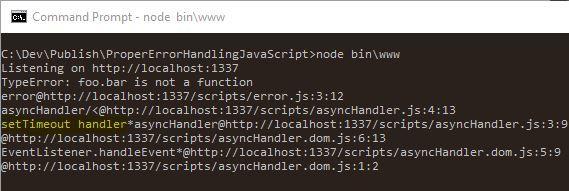
这个处理函数甚至可以告诉我哪个错误是出自于异步代码。它告诉我错误来自于 setTimeout() 处理函数。太酷了!
错误是每一个应用程序的一部分,但是适当的错误处理却不是。在处理错误这件事上至少有两种方法。一种是失败即沉默的方案,即在代码中忽略错误。另一种是快速发现和解决错误的方法,即在错误处停止并且重现。我想我已经把我赞成哪一种及为什么赞成表达地很清楚。我的选择:不要隐藏问题。没有人会为你程序中的意外事件去指责你。这是可以接受的,去打断点、重现、给用户一个尝试。在一个并不完美的世界中,给自己一个机会是很重要的。错误是不可避免的,为了解决错误你做的事情才是重要的。合理地运用JavaScript的错误处理特色和自动灵活的译码可以使用户的体验更顺畅,同时也让开发方的诊断工作变得更轻松。
-
现在我打算创建一个更好的错误处理的“应用程序”框架,我试图寻找最佳实践,但没有找到任何 泽西文档:https://Jersey.java.net/nonav/documentation/1.9/user-guide.html#D4E443 Internet上的几个搜索:http://www.codingpedia.org/ama/error-handing-in-rest-api-with-jer
-
问题内容: 我想知道 在go中处理多层抽象错误 的最佳方法是什么。每当我必须在程序中添加新的级别抽象时,都必须将错误代码从较低级别传输到较高级别。从而日志文件中有重复的通讯,或者我必须记住删除低级别的通讯形式并将其转移到更高级别。下面简单地举例。我跳过了创建每个对象的简短代码,但是我认为您理解我的问题 结果在日志文件中,我得到重复的帖子 反过来,如果我仅将某些部分转移到更高的级别而没有其他日志,那
-
问题内容: 现在我的页面看起来像这样: 我的工作方式可行,但是对于显而易见的事情却非常繁琐和乏味:假设我在代码中间的某个地方调用了一个函数,或者想检查变量的值,或者验证数据库查询返回有效结果,如果失败,我想输出错误?我将不得不制作另一个if / else块,并将所有代码移到新的if块内。这似乎不是一种明智的处理方式。 我一直在阅读有关try / catch的内容,并一直在考虑将我的所有代码放入tr
-
问题内容: 如果我的应用程序崩溃了,它会挂起几秒钟,然后Android告诉我该应用程序崩溃了,需要关闭。所以我当时想用通用的方式捕获应用程序中的所有异常: 并做一个新的解释,说明应用程序立即崩溃(并且还使用户有机会发送包含错误详细信息的邮件),而不是由于Android而造成了延迟。是否有更好的方法来实现这一目标? 更新: 我使用的是启用了ART的Nexus 5,但我没有注意到我以前遇到的崩溃(我最
-
问题内容: 几天前我才开始尝试使用node.js。我意识到只要程序中有未处理的异常,Node就会终止。这与我所见过的普通服务器容器不同,在普通服务器容器中,当发生未处理的异常时,只有工作线程死亡,并且容器仍然能够接收请求。这引起了一些问题: 是唯一有效的预防方法吗? 在执行异步过程期间也会捕获未处理的异常吗? 是否存在已经构建的模块(例如发送电子邮件或写入文件),在未捕获的异常的情况下可以利用该模
-
并创建一个新的,解释应用程序立即崩溃(并给用户发送包含错误详细信息的邮件的机会),而不是由于Android造成的延迟。有没有更好的方法来实现这一点,或者这是不鼓励的? 更新:我使用的Nexus 5启用了ART功能,我没有注意到应用程序崩溃时的延迟(我最初说的“挂起”)。我想既然现在一切都是本机代码,崩溃就会立即发生,同时得到所有的崩溃信息。也许Nexus5只是速度很快:)不管怎样,这在未来的And
-
因此,我有一个Javascript脚本,它在一个循环中将小的分数相加,它有可能将0.2加到0.1。然后,这个值被输入到另一个函数,但问题是,我需要0.3来精确输入,而不是0.3000000000000004。 什么是最简单的方法,以确保数字是正确和准确的。注意,它可能得到0.25+0.125等,被添加到简单的四舍五入到小数点1不会解决问题。 也有可能添加0.2+0.1000000000000000
-
问题内容: 我开始考虑在我的Django应用程序中进行适当的异常处理,并且我的目标是使它尽可能地易于使用。出于用户友好的目的,我暗示用户必须始终就确切的错误之处获得详细的说明。 使用状态为200的JSON响应进行常规响应,并返回(适当的!)4xx / 5xx响应以获取错误。它们也可以携带JSON有效负载,因此您的服务器端可以添加有关错误的其他详细信息。 我试图用这个答案中的关键词来搜索谷歌,但我的