
基于python神经卷积网络的人脸识别

本文实例为大家分享了基于神经卷积网络的人脸识别,供大家参考,具体内容如下
1.人脸识别整体设计方案
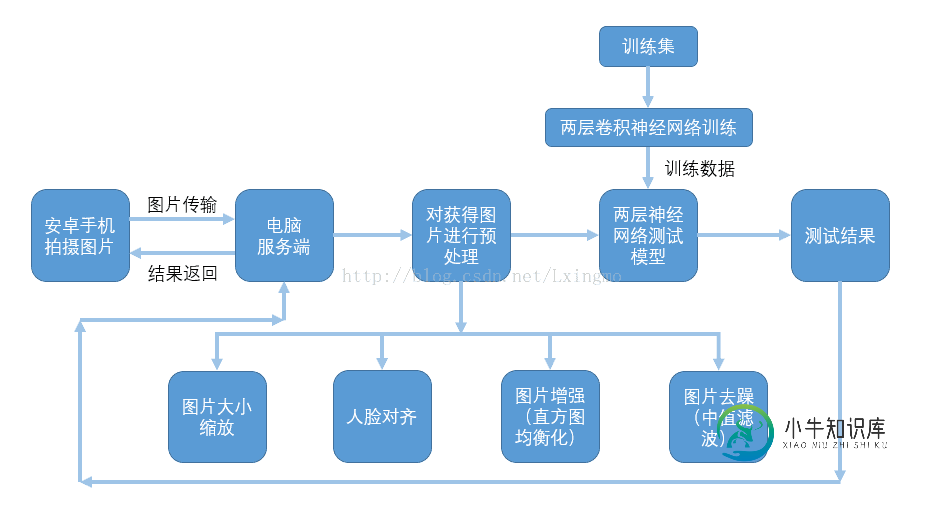
客_服交互流程图:
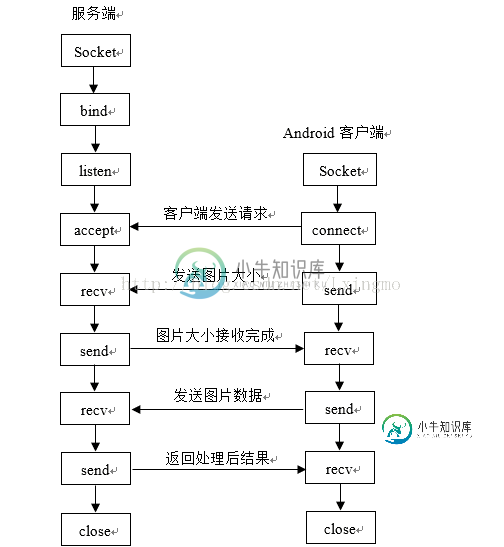
2.服务端代码展示
sk = socket.socket()
# s.bind(address) 将套接字绑定到地址。在AF_INET下,以元组(host,port)的形式表示地址。
sk.bind(("172.29.25.11",8007))
# 开始监听传入连接。
sk.listen(True)
while True:
for i in range(100):
# 接受连接并返回(conn,address),conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。
conn,address = sk.accept()
# 建立图片存储路径
path = str(i+1) + '.jpg'
# 接收图片大小(字节数)
size = conn.recv(1024)
size_str = str(size,encoding="utf-8")
size_str = size_str[2 :]
file_size = int(size_str)
# 响应接收完成
conn.sendall(bytes('finish', encoding="utf-8"))
# 已经接收数据大小 has_size
has_size = 0
# 创建图片并写入数据
f = open(path,"wb")
while True:
# 获取
if file_size == has_size:
break
date = conn.recv(1024)
f.write(date)
has_size += len(date)
f.close()
# 图片缩放
resize(path)
# cut_img(path):图片裁剪成功返回True;失败返回False
if cut_img(path):
yuchuli()
result = test('test.jpg')
conn.sendall(bytes(result,encoding="utf-8"))
else:
print('falue')
conn.sendall(bytes('人眼检测失败,请保持图片眼睛清晰',encoding="utf-8"))
conn.close()
3.图片预处理
1)图片缩放
# 根据图片大小等比例缩放图片 def resize(path): image=cv2.imread(path,0) row,col = image.shape if row >= 2500: x,y = int(row/5),int(col/5) elif row >= 2000: x,y = int(row/4),int(col/4) elif row >= 1500: x,y = int(row/3),int(col/3) elif row >= 1000: x,y = int(row/2),int(col/2) else: x,y = row,col # 缩放函数 res=cv2.resize(image,(y,x),interpolation=cv2.INTER_CUBIC) cv2.imwrite(path,res)
2)直方图均衡化和中值滤波
# 直方图均衡化 eq = cv2.equalizeHist(img) # 中值滤波 lbimg=cv2.medianBlur(eq,3)
3)人眼检测
# -*- coding: utf-8 -*-
# 检测人眼,返回眼睛数据
import numpy as np
import cv2
def eye_test(path):
# 待检测的人脸路径
imagepath = path
# 获取训练好的人脸参数
eyeglasses_cascade = cv2.CascadeClassifier('haarcascade_eye_tree_eyeglasses.xml')
# 读取图片
img = cv2.imread(imagepath)
# 转为灰度图像
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 检测并获取人眼数据
eyeglasses = eyeglasses_cascade.detectMultiScale(gray)
# 人眼数为2时返回左右眼位置数据
if len(eyeglasses) == 2:
num = 0
for (e_gx,e_gy,e_gw,e_gh) in eyeglasses:
cv2.rectangle(img,(e_gx,e_gy),(e_gx+int(e_gw/2),e_gy+int(e_gh/2)),(0,0,255),2)
if num == 0:
x1,y1 = e_gx+int(e_gw/2),e_gy+int(e_gh/2)
else:
x2,y2 = e_gx+int(e_gw/2),e_gy+int(e_gh/2)
num += 1
print('eye_test')
return x1,y1,x2,y2
else:
return False
4)人眼对齐并裁剪
# -*- coding: utf-8 -*-
# 人眼对齐并裁剪
# 参数含义:
# CropFace(image, eye_left, eye_right, offset_pct, dest_sz)
# eye_left is the position of the left eye
# eye_right is the position of the right eye
# 比例的含义为:要保留的图像靠近眼镜的百分比,
# offset_pct is the percent of the image you want to keep next to the eyes (horizontal, vertical direction)
# 最后保留的图像的大小。
# dest_sz is the size of the output image
#
import sys,math
from PIL import Image
from eye_test import eye_test
# 计算两个坐标的距离
def Distance(p1,p2):
dx = p2[0]- p1[0]
dy = p2[1]- p1[1]
return math.sqrt(dx*dx+dy*dy)
# 根据参数,求仿射变换矩阵和变换后的图像。
def ScaleRotateTranslate(image, angle, center =None, new_center =None, scale =None, resample=Image.BICUBIC):
if (scale is None)and (center is None):
return image.rotate(angle=angle, resample=resample)
nx,ny = x,y = center
sx=sy=1.0
if new_center:
(nx,ny) = new_center
if scale:
(sx,sy) = (scale, scale)
cosine = math.cos(angle)
sine = math.sin(angle)
a = cosine/sx
b = sine/sx
c = x-nx*a-ny*b
d =-sine/sy
e = cosine/sy
f = y-nx*d-ny*e
return image.transform(image.size, Image.AFFINE, (a,b,c,d,e,f), resample=resample)
# 根据所给的人脸图像,眼睛坐标位置,偏移比例,输出的大小,来进行裁剪。
def CropFace(image, eye_left=(0,0), eye_right=(0,0), offset_pct=(0.2,0.2), dest_sz = (70,70)):
# calculate offsets in original image 计算在原始图像上的偏移。
offset_h = math.floor(float(offset_pct[0])*dest_sz[0])
offset_v = math.floor(float(offset_pct[1])*dest_sz[1])
# get the direction 计算眼睛的方向。
eye_direction = (eye_right[0]- eye_left[0], eye_right[1]- eye_left[1])
# calc rotation angle in radians 计算旋转的方向弧度。
rotation =-math.atan2(float(eye_direction[1]),float(eye_direction[0]))
# distance between them # 计算两眼之间的距离。
dist = Distance(eye_left, eye_right)
# calculate the reference eye-width 计算最后输出的图像两只眼睛之间的距离。
reference = dest_sz[0]-2.0*offset_h
# scale factor # 计算尺度因子。
scale =float(dist)/float(reference)
# rotate original around the left eye # 原图像绕着左眼的坐标旋转。
image = ScaleRotateTranslate(image, center=eye_left, angle=rotation)
# crop the rotated image # 剪切
crop_xy = (eye_left[0]- scale*offset_h, eye_left[1]- scale*offset_v) # 起点
crop_size = (dest_sz[0]*scale, dest_sz[1]*scale) # 大小
image = image.crop((int(crop_xy[0]),int(crop_xy[1]),int(crop_xy[0]+crop_size[0]),int(crop_xy[1]+crop_size[1])))
# resize it 重置大小
image = image.resize(dest_sz, Image.ANTIALIAS)
return image
def cut_img(path):
image = Image.open(path)
# 人眼识别成功返回True;否则,返回False
if eye_test(path):
print('cut_img')
# 获取人眼数据
leftx,lefty,rightx,righty = eye_test(path)
# 确定左眼和右眼位置
if leftx > rightx:
temp_x,temp_y = leftx,lefty
leftx,lefty = rightx,righty
rightx,righty = temp_x,temp_y
# 进行人眼对齐并保存截图
CropFace(image, eye_left=(leftx,lefty), eye_right=(rightx,righty), offset_pct=(0.30,0.30), dest_sz=(92,112)).save('test.jpg')
return True
else:
print('falue')
return False
4.用神经卷积网络训练数据
# -*- coding: utf-8 -*-
from numpy import *
import cv2
import tensorflow as tf
# 图片大小
TYPE = 112*92
# 训练人数
PEOPLENUM = 42
# 每人训练图片数
TRAINNUM = 15 #( train_face_num )
# 单人训练人数加测试人数
EACH = 21 #( test_face_num + train_face_num )
# 2维=>1维
def img2vector1(filename):
img = cv2.imread(filename,0)
row,col = img.shape
vector1 = zeros((1,row*col))
vector1 = reshape(img,(1,row*col))
return vector1
# 获取人脸数据
def ReadData(k):
path = 'face_flip/'
train_face = zeros((PEOPLENUM*k,TYPE),float32)
train_face_num = zeros((PEOPLENUM*k,PEOPLENUM))
test_face = zeros((PEOPLENUM*(EACH-k),TYPE),float32)
test_face_num = zeros((PEOPLENUM*(EACH-k),PEOPLENUM))
# 建立42个人的训练人脸集和测试人脸集
for i in range(PEOPLENUM):
# 单前获取人
people_num = i + 1
for j in range(k):
#获取图片路径
filename = path + 's' + str(people_num) + '/' + str(j+1) + '.jpg'
#2维=>1维
img = img2vector1(filename)
#train_face:每一行为一幅图的数据;train_face_num:储存每幅图片属于哪个人
train_face[i*k+j,:] = img/255
train_face_num[i*k+j,people_num-1] = 1
for j in range(k,EACH):
#获取图片路径
filename = path + 's' + str(people_num) + '/' + str(j+1) + '.jpg'
#2维=>1维
img = img2vector1(filename)
# test_face:每一行为一幅图的数据;test_face_num:储存每幅图片属于哪个人
test_face[i*(EACH-k)+(j-k),:] = img/255
test_face_num[i*(EACH-k)+(j-k),people_num-1] = 1
return train_face,train_face_num,test_face,test_face_num
# 获取训练和测试人脸集与对应lable
train_face,train_face_num,test_face,test_face_num = ReadData(TRAINNUM)
# 计算测试集成功率
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
# 神经元权重
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 神经元偏置
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 卷积
def conv2d(x, W):
# stride [1, x_movement, y_movement, 1]
# Must have strides[0] = strides[3] = 1
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# 最大池化,x,y步进值均为2
def max_pool_2x2(x):
# stride [1, x_movement, y_movement, 1]
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# define placeholder for inputs to network
xs = tf.placeholder(tf.float32, [None, 10304])/255. # 112*92
ys = tf.placeholder(tf.float32, [None, PEOPLENUM]) # 42个输出
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(xs, [-1, 112, 92, 1])
# print(x_image.shape) # [n_samples, 112,92,1]
# 第一层卷积层
W_conv1 = weight_variable([5,5, 1,32]) # patch 5x5, in size 1, out size 32
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 112x92x32
h_pool1 = max_pool_2x2(h_conv1) # output size 56x46x64
# 第二层卷积层
W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 56x46x64
h_pool2 = max_pool_2x2(h_conv2) # output size 28x23x64
# 第一层神经网络全连接层
W_fc1 = weight_variable([28*23*64, 1024])
b_fc1 = bias_variable([1024])
# [n_samples, 28, 23, 64] ->> [n_samples, 28*23*64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 28*23*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 第二层神经网络全连接层
W_fc2 = weight_variable([1024, PEOPLENUM])
b_fc2 = bias_variable([PEOPLENUM])
prediction = tf.nn.softmax((tf.matmul(h_fc1_drop, W_fc2) + b_fc2))
# 交叉熵损失函数
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = tf.matmul(h_fc1_drop, W_fc2)+b_fc2, labels=ys))
regularizers = tf.nn.l2_loss(W_fc1) + tf.nn.l2_loss(b_fc1) +tf.nn.l2_loss(W_fc2) + tf.nn.l2_loss(b_fc2)
# 将正则项加入损失函数
cost += 5e-4 * regularizers
# 优化器优化误差值
train_step = tf.train.AdamOptimizer(1e-4).minimize(cost)
sess = tf.Session()
init = tf.global_variables_initializer()
saver = tf.train.Saver()
sess.run(init)
# 训练1000次,每50次输出测试集测试结果
for i in range(1000):
sess.run(train_step, feed_dict={xs: train_face, ys: train_face_num, keep_prob: 0.5})
if i % 50 == 0:
print(sess.run(prediction[0],feed_dict= {xs: test_face,ys: test_face_num,keep_prob: 1}))
print(compute_accuracy(test_face,test_face_num))
# 保存训练数据
save_path = saver.save(sess,'my_data/save_net.ckpt')
5.用神经卷积网络测试数据
# -*- coding: utf-8 -*- # 两层神经卷积网络加两层全连接神经网络 from numpy import * import cv2 import tensorflow as tf # 神经网络最终输出个数 PEOPLENUM = 42 # 2维=>1维 def img2vector1(img): row,col = img.shape vector1 = zeros((1,row*col),float32) vector1 = reshape(img,(1,row*col)) return vector1 # 神经元权重 def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) # 神经元偏置 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) # 卷积 def conv2d(x, W): # stride [1, x_movement, y_movement, 1] # Must have strides[0] = strides[3] = 1 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') # 最大池化,x,y步进值均为2 def max_pool_2x2(x): # stride [1, x_movement, y_movement, 1] return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME') # define placeholder for inputs to network xs = tf.placeholder(tf.float32, [None, 10304])/255. # 112*92 ys = tf.placeholder(tf.float32, [None, PEOPLENUM]) # 42个输出 keep_prob = tf.placeholder(tf.float32) x_image = tf.reshape(xs, [-1, 112, 92, 1]) # print(x_image.shape) # [n_samples, 112,92,1] # 第一层卷积层 W_conv1 = weight_variable([5,5, 1,32]) # patch 5x5, in size 1, out size 32 b_conv1 = bias_variable([32]) h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # output size 112x92x32 h_pool1 = max_pool_2x2(h_conv1) # output size 56x46x64 # 第二层卷积层 W_conv2 = weight_variable([5,5, 32, 64]) # patch 5x5, in size 32, out size 64 b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output size 56x46x64 h_pool2 = max_pool_2x2(h_conv2) # output size 28x23x64 # 第一层神经网络全连接层 W_fc1 = weight_variable([28*23*64, 1024]) b_fc1 = bias_variable([1024]) # [n_samples, 28, 23, 64] ->> [n_samples, 28*23*64] h_pool2_flat = tf.reshape(h_pool2, [-1, 28*23*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 第二层神经网络全连接层 W_fc2 = weight_variable([1024, PEOPLENUM]) b_fc2 = bias_variable([PEOPLENUM]) prediction = tf.nn.softmax((tf.matmul(h_fc1_drop, W_fc2) + b_fc2)) sess = tf.Session() init = tf.global_variables_initializer() # 下载训练数据 saver = tf.train.Saver() saver.restore(sess,'my_data/save_net.ckpt') # 返回签到人名 def find_people(people_num): if people_num == 41: return '任童霖' elif people_num == 42: return 'LZT' else: return 'another people' def test(path): # 获取处理后人脸 img = cv2.imread(path,0)/255 test_face = img2vector1(img) print('true_test') # 计算输出比重最大的人及其所占比重 prediction1 = sess.run(prediction,feed_dict={xs:test_face,keep_prob:1}) prediction1 = prediction1[0].tolist() people_num = prediction1.index(max(prediction1))+1 result = max(prediction1)/sum(prediction1) print(result,find_people(people_num)) # 神经网络输出最大比重大于0.5则匹配成功 if result > 0.50: # 保存签到数据 qiandaobiao = load('save.npy') qiandaobiao[people_num-1] = 1 save('save.npy',qiandaobiao) # 返回 人名+签到成功 print(find_people(people_num) + '已签到') result = find_people(people_num) + ' 签到成功' else: result = '签到失败' return result
神经卷积网络入门简介
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Kriz
-
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络
-
在了解了机器学习概念之后,现在可以将注意力转移到深度学习概念上。深度学习是机器学习的一个分支。深度学习实现的示例包括图像识别和语音识别等应用。 以下是两种重要的深度神经网络 - 卷积神经网络 递归神经网络 在本章中,我们将重点介绍CNN - 卷积神经网络。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。CNN与其他普通神经网络之间的主要区别在于
-
主要内容:卷积神经网络深度学习是机器学习的一个分支,它是近几十年来研究人员突破的关键步骤。深度学习实现的示例包括图像识别和语音识别等应用。 下面给出了两种重要的深度神经网络 - 卷积神经网络 递归神经网络。 在本章中,我们将关注第一种类型,即卷积神经网络(CNN)。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。 CNN与任何其他普通神经网络之间的主要区别在于CNN
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Krizhev
-
在“多层感知机的从零开始实现”一节里我们构造了一个含单隐藏层的多层感知机模型来对Fashion-MNIST数据集中的图像进行分类。每张图像高和宽均是28像素。我们将图像中的像素逐行展开,得到长度为784的向量,并输入进全连接层中。然而,这种分类方法有一定的局限性。 图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。 对于大尺寸的输入图像,使用全连接层容易造成模型过大
-
下午好在第一阶段,在卷积神经网络(输入层)的输入上,我们接收一个源图像(因此是手写英文字母的图像)。首先,我们使用一个从左到右的nxn窗口来扫描图像并在内核(卷积矩阵)上乘法来构建特征映射?但没有人写过内核应该具有什么样的精确值(换句话说,我应该将从n*n窗口检索到的数据相乘到什么样的内核值)。是否适合在这个用于边缘检测的卷积核上乘以数据?有许多卷积核(浮雕、高斯滤波器、边缘检测、角度检测等)?但
-
我有32760个音频频谱,计算维度=72(#帧)x 40(#频段),我试图将其输入“宽”卷积神经网络(第一层是4个不同conv层的合奏)。这些频谱没有深度,因此它们可以表示为72 x 40 2D数字浮点数组,因此分类器的X输入是一个32760个元素长的数组,每个元素都是这些72 x 40 x 1频谱之一。Y输入是一个标签数组,一个热编码,有32760个元素。 当尝试使用 我得到以下错误: 以下是我