
apache集成php5.6方法分享

apache对php的支持是通过apache的mod_php5模块来支持的,这点与nginx不同。nginx是通过第三方的fastcgi处理器才可以对php进行解析。
如果源码编译安装php的话,需要在编译时指定--with-apxs2=/usr/local/apache2/bin/apxs表示告诉编译器通过apache的mod_php5模块来提供对php的解析。
同时php安装的最后一步make install时,我们会看到将动态链接库libphp5.so拷贝到apache2的安装目录的modules目录下,并且还需要在httpd.conf配置文件中添加LoadModule语句来动态将libphp5.so模块加载进来,从而实现Apache对php的支持。
php与apache集成需要以下几个步骤:
1、安装libiconv库
2、php源码安装
3、配置apache使其支持php
4、测试php
一、安装libiconv库
libiconv库为需要做转换的应用程序提供了一个iconv命令,以实现一个字符编码到另一个字符编码的转换,比如它可以将UTF8编码转换成GB18030编码,反过来也行。
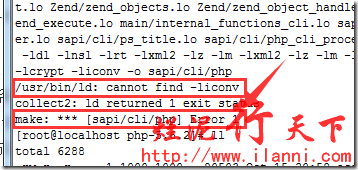
php与apache集成时一定要安装libiconv库,否则在make时系统会报错。报错信息如下:
make: *** [sapi/cli/php] Error 1
/usr/bin/ld: cannot find -liconv
collect2: ld returned 1 exit status
make: *** [sapi/cli/php] Error 1
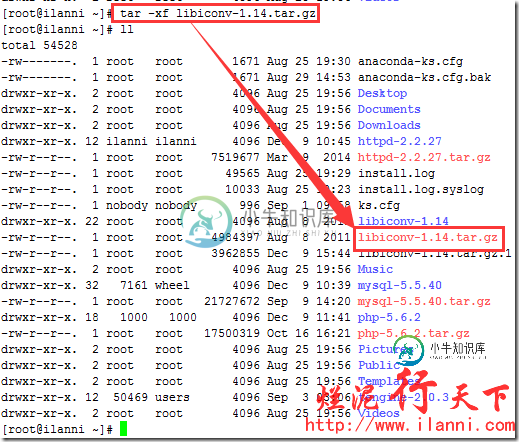
现在开始正式安装libiconv库,首先下载libiconv库,如下:
wget http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.14.tar.gz

解压libiconv库,如下:
tar -xf libiconv-1.14.tar.gz
安装libiconv库,首先查看安装帮助信息。如下:
./configure --help
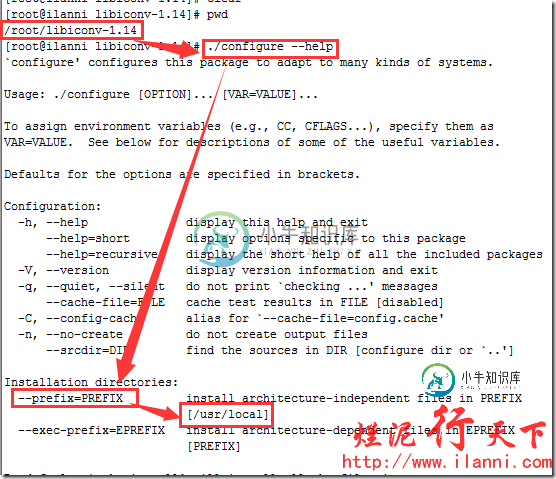
通过上图的帮助,我们可以看到libiconv库默认的安装路径为/usr/local。现在开始安装libiconv库,如下:
./configure --prefix=/usr/local
make && make install
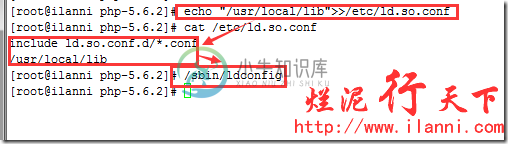
libiconv库安装完毕后,建议把/usr/local/lib库加入到到/etc/ld.so.conf文件中,然后使用/sbin/ldconfig使其生效。如下:
echo "/usr/local/lib">>/etc/ld.so.conf
/sbin/ldconfig
如果没有进行此步操作的话,在安装php执行make install,系统就会报错。报错信息如下:
/root/php-5.6.2/sapi/cli/php: error while loading shared libraries: libiconv.so.2: cannot open shared object file: No such file or directory
二、php源码安装
下载并编译php命令如下:
wget http://mirrors.sohu.com/php/php-5.6.2.tar.gz
./configure --enable-fpm --enable-mbstring --with-mysql=/usr/local/mysql --with-iconv-dir=/usr/local --with-apxs2=/usr/local/apache2/bin/apxs
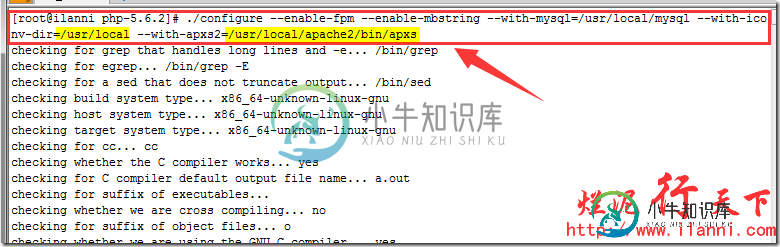
注意上述命令中--enable-fpm的作用是开启php的fastcgi功能,即开启php-fpm功能。
--with-mysql=/usr/local/mysql是启用php支持mysql的功能,/usr/local/mysql是mysql数据库的安装路径。
--enable-mbstring表示启用mbstring模块mbstring模块的主要作用在于检测和转换编码,提供对应的多字节操作的字符串函数。目前php内部的编码只支持ISO-8859-*、EUC-JP、UTF-8,其他的编码的语言是没办法在php程序上正确显示的,所以我们要启用mbstring模块。
--with-iconv-dir=/usr/local指定php存放libiconv库的位置。
--with-apxs2=/usr/local/apache2/bin/apxs指定php查找apache的位置。
编译完毕后,我们再来make。在make时,我们注意要加上-liconv参数。如果不加上-liconv参数,系统在make编译会报错。报错信息如下:
Generating phar.php
php-5.3.16/sapi/cli/php: error while loading shared libraries: libiconv.so.2: cannot open shared object file: No such file or directory
使用命令如下:
make ZEND_EXTRA_LIBS='-liconv'
我们也可以通过修改Makefile文件,在ZEND_EXTRA_LIBS行加入-liconv。如下:
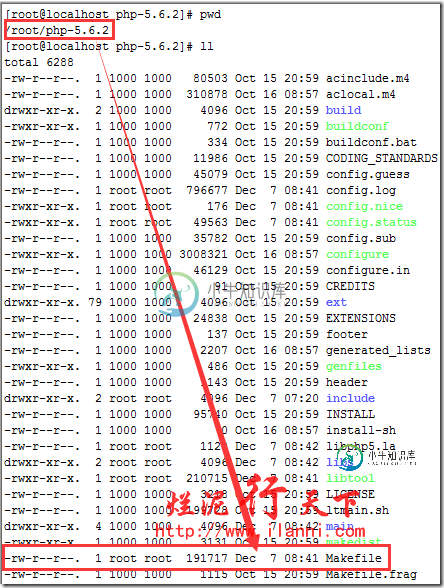
vi Makefile

make install
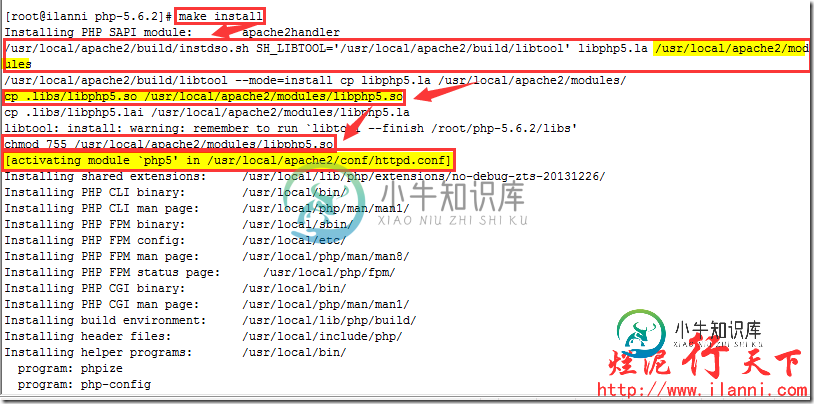
通过上图,我们可以很明显的看到apache配置文件httpd中启用php支持,同时也把libphp5.so文件复制到apache的模块目录下。
三、配置apache使其支持php
php安装完毕后,我们就可以通过修改apache的配置文件httpd.conf来使其支持php。
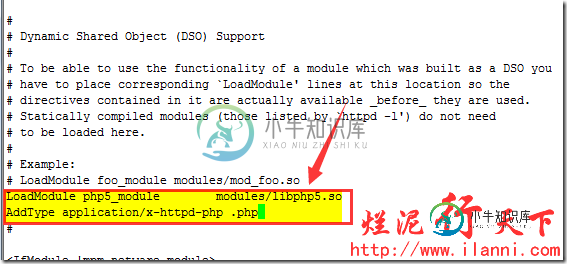
我们只需要在httpd.conf文件中加入如下两行代码:
LoadModule php5_module modules/libphp5.so
AddType application/x-httpd-php .php
注意,其中LoadModule php5_module modules/libphp5.so行,我们查看httpd.conf文件时会发现该行已经存在。那是因为在安装php时,添加的。现在我们只需要添加AddType application/x-httpd-php .php行即可。
vi /usr/local/apache2/conf/httpd.conf
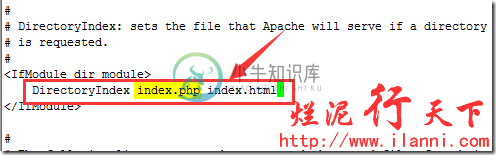
除此之外,我们还需要修改apache的默认主页文件,添加index.php。内容如下:
echo "<?php phpinfo();?>">/usr/local/apache2/htdocs/index.php
cat /usr/local/apache2/htdocs/index.php

四、测试php
以上修改完毕后,我们重新启动apache,使用如下命令:
/etc/init.d/httpd graceful
注意该命令可以优雅的重启apache。

打开站点,如下:
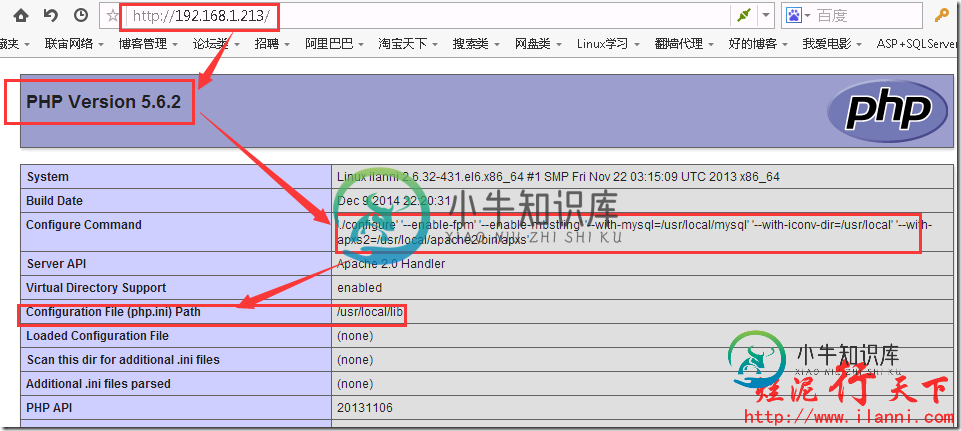
通过上图,我们可以很明显的看到apache已经支持php。
-
我需要实现下面的数据流。我有一个kafka主题,它有9个分区。我可以用9个并行级别阅读这个主题。我还有3个节点Flink集群。这个集群的每个节点都有24个任务槽。 首先,我想传播我的kafka,每个服务器有3个分区,如下所示。顺序没关系,我只转换kafka消息并发送DB。 第二件事是,我想在保存NoSQL DB的同时提高并行度。如果我增加并行度48,因为发送DB是IO操作,它不会消耗CPU,我想确
-
本文向大家介绍Spring 应用中集成 Apache Shiro的方法,包括了Spring 应用中集成 Apache Shiro的方法的使用技巧和注意事项,需要的朋友参考一下 这一篇文章涵盖了将 Shiro 集成到基于 Spring 的应用程序的方法。 Shiro 的 Java Bean兼容性使它非常适合通过 Spring XML 或其他基于 Spring 的配置机制进行配置。Shiro 的应用程
-
我正在学习如何将kafka与apache camel集成,我遇到了以下错误。我在c:/inbox文件夹中创建了一个文件,并希望使用kafka Consumer使用其中的文本。我使用的是apache Camel3.1.0版本。下面是我的代码 下面是我得到的错误
-
Apache Cassandra 的 Bolt API 实现 这个库提供了 Apache Cassandra 之上的核心 storm bolt . 提供简单的 DSL 来 map storm Tuple 到 Cassandra Query Language Statement (Cassandra 查询语言 Statement). Configuration (配置) 以下属性可能会传递给 sto
-
针对 Apache Solr 的 Storm 和 Trident 集成. 该软件包包括一个 bolt和 trident state,它们可以使 Storm topology 将 storm tuples 的内容索引到 Solr collections. Index Storm tuples 到 Solr collection 中 bolt 和 trident state 使用一个提供的 mappe
-
Hive 提供了 streaming API, 它允许将数据连续地写入 Hive. 传入的数据可以用小批量 record 的方式连续提交到现有的 Hive partition 或 table 中. 一旦提交了数据,它就可以立即显示给所有的 hive 查询. 有关 Hive Streaming API 的更多信息请参阅 https://cwiki.apache.org/confluence/disp
-
Storm组件和 HDFS 文件系统交互. Usage 以下示例将pipe(“|”)分隔的文件写入HDFS路径hdfs://localhost:54310/foo。 每1000个 tuple 之后,它将同步文件系统,使该数据对其他HDFS客户端可见。当它们达到5MB大小时,它将旋转文件。 // use "|" instead of "," for field delimiter RecordFo
-
Storm/Trident integration for Apache HBase Usage The main API for interacting with HBase is the org.apache.storm.hbase.bolt.mapper.HBaseMapper interface: public interface HBaseMapper extends Serializa