
Java中字符编码格式详解

一、前言
在分析Comparable和Comparator的时候,分析到了String类的compareTo方法,String底层是用char[]数组来存放元素,在比较的时候是比较的两个字符串的字符,字符用char来存储,此时,突然想到,Java里面的char可以存放中文吗?后来发现是可以的,并且由此也引出了Java中字符的编码格式问题。
二、Java存储格式
在Java中,如下代码获取了字符'张'的各种编码格式。
import java.io.UnsupportedEncodingException;
public class Test {
public static String getCode(String content, String format) throws UnsupportedEncodingException {
byte[] bytes = content.getBytes(format);
StringBuffer sb = new StringBuffer();
for (int i = 0; i < bytes.length; i++) {
sb.append(Integer.toHexString(bytes[i] & 0xff).toUpperCase() + " ");
}
return sb.toString();
}
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println("gbk : " + getCode("张", "gbk"));
System.out.println("gb2312 : " + getCode("张", "gb2312"));
System.out.println("iso-8859-1 : " + getCode("张", "iso-8859-1"));
System.out.println("unicode : " + getCode("张", "unicode"));
System.out.println("utf-16 : " + getCode("张", "utf-16"));
System.out.println("utf-8 : " + getCode("张", "utf-8"));
}
}
运行结果:
gbk : D5 C5 gb2312 : D5 C5 iso-8859-1 : 3F unicode : FE FF 5F 20 utf-16 : FE FF 5F 20 utf-8 : E5 BC A0
说明:从结果我们可以知道,字符'张'的gbk与gb2312编码是相同的,unicode与utf-16编码时相同的,但是其iso-8859-1、unicode、utf-8编码都是不相同的。那么,在JVM中,字符'张'是按照哪种编码格式进行存储的呢?下面开始我们的分析。
三、探秘思路
1. 查看.class文件常量池的存储格式
测试代码如下
public class Test {
public static void main(String[] args) {
String str = "张";
}
}
使用javap -verbose Test.class进行反编译,发现常量池情况如下:
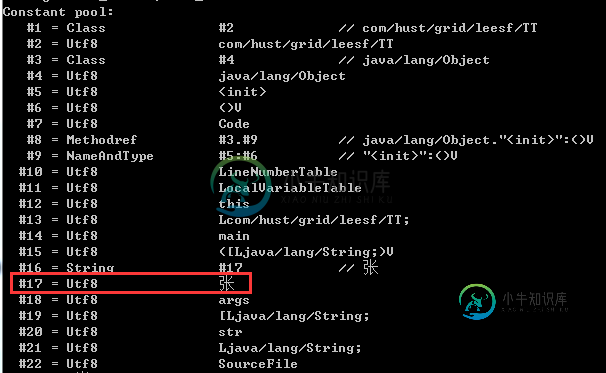
再使用winhex打开class文件,发现字符'张'在常量池的存储如下
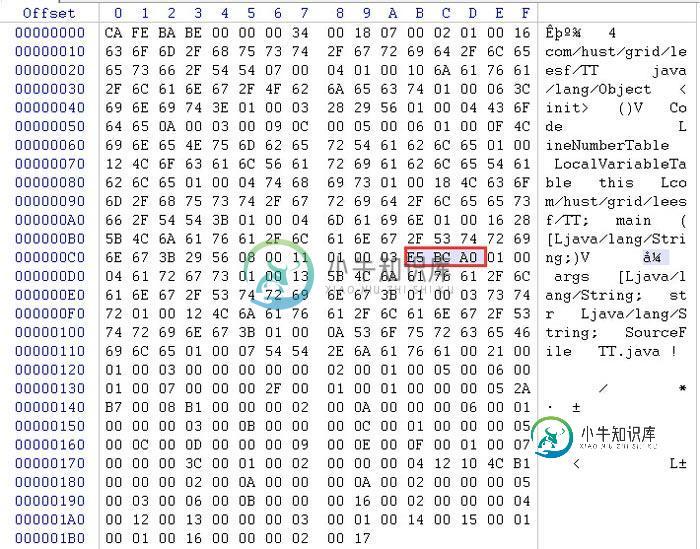
说明:上面两张可以在class文件中是以utf-8的格式存储的。
但是在运行时是否是utf-8格式呢?继续我们的探秘之旅。
2. 在程序中一探究竟
使用如下代码
public class Test {
public static void main(String[] args) {
String str = "张";
System.out.println(Integer.toHexString(str.codePointAt(0)).toUpperCase());
}
}
运行结果:
5F20
说明:根据结果我们知道在运行时JVM是使用的utf-16格式进行存储,utf-16一般是使用2个字节进行存储,如果遇到两个字节无法表示的字符则会使用4个字节表示。之后会另外有篇幅进行介绍,并且我们查看Character类源码时,会发现就是使用的utf-16进行编码的,从两面都找到了我们想要的答案。
3. char类型可以存放中文吗?
根据上面的探索我们已经知道了Java的class文件中字符是以utf-8进行编码的,在JVM运行时则是以utf-16进行编码存储的。而字符'张'可以用两个字节来表示,而char在Java中也是两个字节,故可以存放。
四、总结
经过上面的分析,我们知道:
1. 字符在class文件中是以utf-8格式进行编码的,而在JVM运行时是采用utf-16格式进行编码的。
2. char类型是两个字节,可以用来存放中文。
在此次调用的过程中又查阅了好多关于字符方面的资料,受益匪浅,并且发现特别有意思,接下来会进行分享,所以特此预告下一篇将会进一步来介绍编码以及编码在Java中的问题。敬请期待
-
本文向大家介绍JavaScript字符集编码与解码详谈,包括了JavaScript字符集编码与解码详谈的使用技巧和注意事项,需要的朋友参考一下 一、字符集 1)字符与字节(Character) 字符是各种文字和符号的总称,包括乱码;一个字符对应1~n个字节,一字节对应8位,每位用0或1表示。 2)字符集(Character Set) 字符集是多个字符的集合,每个字符集包含的字符个数不同,常见字符集
-
我有一个Java(Java 7)程序,使用带有属性文件的i18n,但我不能插入表情符号或其他“非普通”字母,因为Java打印
-
本文向大家介绍详解Python当中的字符串和编码,包括了详解Python当中的字符串和编码的使用技巧和注意事项,需要的朋友参考一下 字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数
-
问题 你要在C和Python直接来回转换字符串,但是C中的编码格式并不确定。 例如,可能C中的数据期望是UTF-8,但是并没有强制它必须是。 你想编写代码来以一种优雅的方式处理这些不合格数据,这样就不会让Python奔溃或者破坏进程中的字符串数据。 解决方案 下面是一些C的数据和一个函数来演示这个问题: /* Some dubious string data (malformed UTF-8) *
-
问题内容: 我试图理解Java中的字符编码。Java中的字符使用UTF-16编码以16位存储。因此,当我将包含6个字符的字符串转换为字节时,我将得到如下所示的6个字节,但我希望它是12。是否缺少任何概念? O / p:字符数组的长度为6 根据@Darshan尝试使用UTF-16编码获取字节时,结果也不期望。 问题答案: 在UTF-16版本中,由于插入了一个标记来区分Big Endian(默认)和L
-
问题内容: 我正在使用Java Spring Resttemplate通过get请求获取json。我正在获取的JSON代替了诸如üöä或ß之类的特殊字符。所以我猜字符编码有问题。我在互联网上找不到任何帮助。我现在使用的代码是: 问题答案: 您只需将添加到模板的消息转换器中: