
带你学习Python如何实现回归树模型

所谓的回归树模型其实就是用树形模型来解决回归问题,树模型当中最经典的自然还是决策树模型,它也是几乎所有树模型的基础。虽然基本结构都是使用决策树,但是根据预测方法的不同也可以分为两种。第一种,树上的叶子节点就对应一个预测值和分类树对应,这一种方法称为回归树。第二种,树上的叶子节点对应一个线性模型,最后的结果由线性模型给出。这一种方法称为模型树。
今天我们先来看看其中的回归树。
回归树模型
CART算法的核心精髓就是我们每次选择特征对数据进行拆分的时候,永远对数据集进行二分。无论是离散特征还是连续性特征,一视同仁。CART还有一个特点是使用GINI指数而不是信息增益或者是信息增益比来选择拆分的特征,但是在回归问题当中用不到这个。因为回归问题的损失函数是均方差,而不是交叉熵,很难用熵来衡量连续值的准确度。
在分类树当中,我们一个叶子节点代表一个类别的预测值,这个类别的值是落到这个叶子节点当中训练样本的类别的众数,也就是出现频率最高的类别。在回归树当中,叶子节点对应的自然就是一个连续值。这个连续值是落到这个节点的训练样本的均值,它的误差就是这些样本的均方差。
另外,之前我们在选择特征的划分阈值的时候,对阈值的选择进行了优化,只选择了那些会引起预测类别变化的阈值。但是在回归问题当中,由于预测值是一个浮点数,所以这个优化也不存在了。整体上来说,其实回归树的实现难度比分类树是更低的。
实战
我们首先来加载数据,我们这次使用的是scikit-learn库当中经典的波士顿房价预测的数据。关于房价预测,kaggle当中也有一个类似的比赛,叫做:house-prices-advanced-regression-techniques。不过给出的特征更多,并且存在缺失等情况,需要我们进行大量的特征工程。感兴趣的同学可以自行研究一下。
首先,我们来获取数据,由于sklearn库当中已经有数据了,我们可以直接调用api获取,非常简单:
import numpy as np import pandas as pd from sklearn.datasets import load_boston boston = load_boston() X, y = boston.data, boston.target
我们输出前几条数据查看一下:
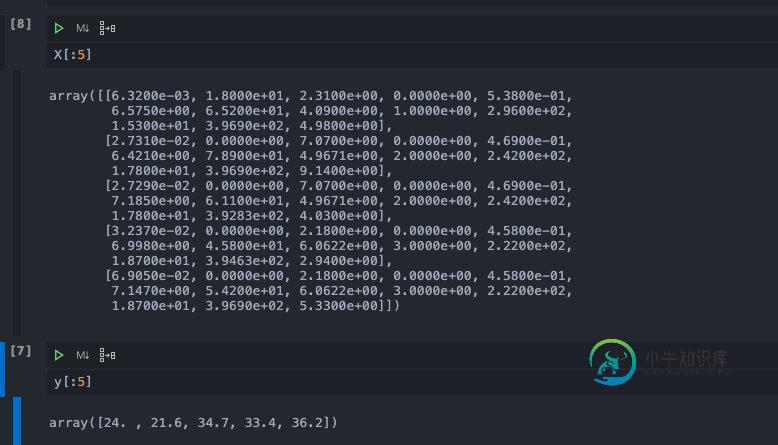
这个数据质量很高,sklearn库已经替我们做完了数据筛选与特征工程,直接拿来用就可以了。为了方便我们传递数据,我们将X和y合并在一起。由于y是一维的数组形式是不能和二维的X合并的,所以我们需要先对y进行reshape之后再进行合并。
y = y.reshape(-1, 1) X = np.hstack((X, y))
hstack函数可以将两个np的array横向拼接,与之对应的是vstack,是将两个array纵向拼接,这个也是常规操作。合并之后,y作为新的一列添加在了X的后面。数据搞定了,接下来就要轮到实现模型了。
在实现决策树的主体部分之前,我们先来实现两个辅助函数。第一个辅助函数是计算一批样本的方差和,第二个辅助函数是获取样本的均值,也就是子节点的预测值。
def node_mean(X): return np.mean(X[:, -1]) def node_variance(X): return np.var(X[:, -1]) * X.shape[0]
这个搞定了之后,我们继续实现根据阈值拆分数据的函数。这个也可以复用之前的代码:
from collections import defaultdict def split_dataset(X, idx, thred): split_data = defaultdict(list) for x in X: split_data[x[idx] < thred].append(x) return list(split_data.values()), list(split_data.keys())
接下来是两个很重要的函数,分别是get_thresholds和split_variance。顾名思义,第一个函数用来获取阈值,前面说了由于我们做的是回归模型,所以理论上来说特征的每一个取值都可以作为切分的依据。但是也不排除可能会存在多条数据的特征值相同的情况,所以我们对它进行去重。第二个函数是根据阈值对数据进行拆分,返回拆分之后的方差和。
def get_thresholds(X, i): return set(X[:, i].tolist()) # 每次迭代方差优化的底线 MINIMUM_IMPROVE = 2.0 # 每个叶子节点最少样本数 MINIMUM_SAMPLES = 10 def split_variance(dataset, idx, threshold): left, right = [], [] n = dataset.shape[0] for data in dataset: if data[idx] < threshold: left.append(data) else: right.append(data) left, right = np.array(left), np.array(right) # 预剪枝 # 如果拆分结果有一边过少,则返回None,防止过拟合 if len(left) < MINIMUM_SAMPLES or len(right) < MINIMUM_SAMPLES: return None # 拆分之后的方差和等于左子树的方差和加上右子树的方差和 # 因为是方差和而不是均方差,所以可以累加 return node_variance(left) + node_variance(right)
这里我们用到了MINIMUM_SAMPLES这个参数,它是用来预剪枝用的。由于我们是回归模型,如果不对决策树的生长加以限制,那么很有可能得到的决策树的叶子节点和训练样本的数量一样多。这显然就陷入了过拟合了,对于模型的效果是有害无益的。所以我们要限制每个节点的样本数量,这个是一个参数,我们可以根据需要自行调整。
接下来,就是特征和阈值筛选的函数了。我们需要开发一个函数来遍历所有可以拆分的特征和阈值,对数据进行拆分,从所有特征当中找到最佳的拆分可能。
def choose_feature_to_split(dataset):
n = len(dataset[0])-1
m = len(dataset)
# 记录最佳方差,特征和阈值
var_ = node_variance(dataset)
bestVar = float('inf')
feature = -1
thred = None
for i in range(n):
threds = get_thresholds(dataset, i)
for t in threds:
# 遍历所有的阈值,计算每个阈值的variance
v = split_variance(dataset, i, t)
# 如果v等于None,说明拆分过拟合了,跳过
if v is None:
continue
if v < bestVar:
bestVar, feature, thred = v, i, t
# 如果最好的拆分效果达不到要求,那么就不拆分,控制子树的数量
if var_ - bestVar < MINIMUM_IMPROVE:
return None, None
return feature, thred
和上面一样,这个函数当中也用到了一个预剪枝的参数MINIMUM_IMPROVE,它衡量的是每一次生成子树带来的收益。当某一次生成子树带来的收益小于某个值的时候,说明收益很小,并不划算,所以我们就放弃这次子树的生成。这也是预剪枝的一种。
这些都搞定了之后,就可以来建树了。建树的过程和之前类似,只是我们这一次的数据当中没有特征的name,所以我们去掉特征名称的相关逻辑。
def create_decision_tree(dataset):
dataset = np.array(dataset)
# 如果当前数量小于10,那么就不再继续划分了
if dataset.shape[0] < MINIMUM_SAMPLES:
return node_mean(dataset)
# 记录最佳拆分的特征和阈值
fidx, th = choose_feature_to_split(dataset)
if fidx is None:
return th
node = {}
node['feature'] = fidx
node['threshold'] = th
# 递归建树
split_data, vals = split_dataset(dataset, fidx, th)
for data, val in zip(split_data, vals):
node[val] = create_decision_tree(data)
return node
我们来完整测试一下建树,首先我们需要对原始数据进行拆分。将原始数据拆分成训练数据和测试数据,由于我们的场景比较简单,就不设置验证数据了。
拆分数据不用我们自己实现,sklearn当中提供了相应的工具,我们直接调用即可:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=23)
我们一般用到的参数就两个,一个是test_size,它可以是一个整数也可以是一个浮点数。如果是整数,代表的是测试集的样本数量。如果是一个0-1.0的浮点数,则代表测试集的占比。random_state是生成随机数的时候用到的随机种子。
我们输出一下生成的树,由于数据量比较大,可以看到一颗庞大的树结构。建树的部分实现了之后,最后剩下的就是预测的部分了。
预测部分的代码和之前分类树相差不大,整体的逻辑完全一样,只是去掉了feature_names的相关逻辑。
def classify(node, data):
key = node['feature']
pred = None
thred = node['threshold']
if isinstance(node[data[key] < thred], dict):
pred = classify(node[data[key] < thred], data)
else:
pred = node[data[key] < thred]
# 放置pred为空,挑选一个叶子节点作为替补
if pred is None:
for key in node:
if not isinstance(node[key], dict):
pred = node[key]
break
return pred
由于这个函数一次只能接受一条数据,如果我们想要批量预测的话还不行,所以最好的话再实现一个批量预测的predict函数比较好。
def predict(node, X): y_pred = [] for x in X: y = classify(node, x) y_pred.append(y) return np.array(y_pred)
后剪枝
后剪枝的英文原文是post-prune,但是翻译成事后剪枝也有点奇怪。anyway,我们就用后剪枝这个词好了。
在回归树当中,我们利用的思想非常朴素,在建树的时候建立一棵尽量复杂庞大的树。然后在通过测试集对这棵树进行修剪,修剪的逻辑也非常简单,我们判断一棵子树存在分叉和没有分叉单独成为叶子节点时的误差,如果修剪之后误差更小,那么我们就减去这棵子树。
整个剪枝的过程和建树的过程一样,从上到下,递归执行。
整个逻辑很好理解,我们直接来看代码:
def is_dict(node): return isinstance(node, dict) def prune(node, testData): testData = np.array(testData) if testData.shape[0] == 0: return node # 拆分数据 split_data, _ = split_dataset(testData, node['feature'], node['threshold']) # 对左右子树递归修剪 if is_dict(node[0]): node[0] = prune(node[0], split_data[0]) if is_dict(node[1]) and len(split_data) > 1: node[1] = prune(node[1], split_data[1]) # 如果左右都是叶子节点,那么判断当前子树是否需要修剪 if len(split_data) > 1 and not is_dict(node[0]) and not is_dict(node[1]): # 计算修剪前的方差和 baseError = np.sum(np.power(np.array(split_data[0])[:, -1] - node[0], 2)) + np.sum(np.power(np.array(split_data[1])[:, -1] - node[1], 2)) # 计算修剪后的方差和 meanVal = (node[0] + node[1]) / 2 mergeError = np.sum(np.power(meanVal - testData[:, -1], 2)) if mergeError < baseError: return meanVal else: return node return node
最后,我们对修剪之后的效果做一下验证:
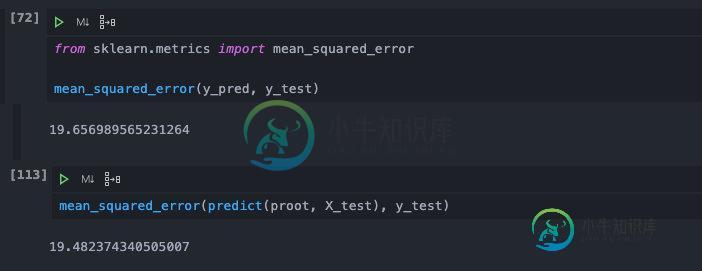
从图中可以看到,修剪之前我们在测试数据上的均方差是19.65,而修剪之后降低到了19.48。从数值上来看是有效果的,只是由于我们的训练数据比较少,同时进行了预剪枝,影响了后剪枝的效果。但是对于实际的机器学习工程来说,一个方法只要是有明确效果的,在代价可以承受的范围内,它就是有价值的,千万不能觉得提升不明显,而随便否定一个方法。
这里计算均方差的时候用到了sklearn当中的一个库函数mean_square_error,从名字当中我们也可以看得出来它的用途,它可以对两个Numpy的array计算均方差。
总结
关于回归树模型的相关内容到这里就结束了,我们不仅亲手实现了模型,而且还在真实的数据集上做了实验。如果你是亲手实现的模型的代码,相信你一定会有很多收获。
虽然从实际运用来说我们几乎不会使用树模型来做回归任务,但是回归树模型本身是非常有意义的。因为在它的基础上我们发展出了很多效果更好的模型,比如大名鼎鼎的GBDT。因此理解回归树对于我们后续进阶的学习是非常重要的。在深度学习普及之前,其实大多数高效果的模型都是以树模型为基础的,比如随机森林、GBDT、Adaboost等等。可以说树模型撑起了机器学习的半个时代,这么说相信大家应该都能理解它的重要性了吧。
今天的文章就到这里,如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。
以上就是带你学习Python如何实现回归树模型的详细内容,更多关于Python实现回归树模型的资料请关注小牛知识库其它相关文章!
-
本文向大家介绍python实现机器学习之元线性回归,包括了python实现机器学习之元线性回归的使用技巧和注意事项,需要的朋友参考一下 一、理论知识准备 1.确定假设函数 如:y=2x+7 其中,(x,y)是一组数据,设共有m个 2.误差cost 用平方误差代价函数 3.减小误差(用梯度下降) 二、程序实现步骤 1.初始化数据 x、y:样本 learning rate:学习率 循环次数loopNu
-
本文向大家介绍python实现机器学习之多元线性回归,包括了python实现机器学习之多元线性回归的使用技巧和注意事项,需要的朋友参考一下 总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便。 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: 特别需要注意的是要弄清:矩阵的形状 在梯度下降的时候,计算两个偏导值,这里面的矩阵形状变化需要注意。 梯度下降数学式子
-
本文向大家介绍如何在python中实现线性回归,包括了如何在python中实现线性回归的使用技巧和注意事项,需要的朋友参考一下 线性回归是基本的统计和机器学习技术之一。经济,计算机科学,社会科学等等学科中,无论是统计分析,或者是机器学习,还是科学计算,都有很大的机会需要用到线性模型。建议先学习它,然后再尝试更复杂的方法。 本文主要介绍如何逐步在Python中实现线性回归。而至于线性回归的数学推导、
-
本文向大家介绍PyTorch学习笔记之回归实战,包括了PyTorch学习笔记之回归实战的使用技巧和注意事项,需要的朋友参考一下 本文主要是用PyTorch来实现一个简单的回归任务。 编辑器:spyder 1.引入相应的包及生成伪数据 其中torch.linspace是为了生成连续间断的数据,第一个参数表示起点,第二个参数表示终点,第三个参数表示将这个区间分成平均几份,即生成几个数据。因为torch
-
本文向大家介绍Python基于numpy模块实现回归预测,包括了Python基于numpy模块实现回归预测的使用技巧和注意事项,需要的朋友参考一下 代码如下 上面的一段代码利用numpy生成数据序列,并实现了1阶回归,并画出预测效果图,图形如下: 将代码改一下,实现2阶、3阶回归预测,只需要model = np.polyfit(t, y, deg =2)即可,同理3阶模型就把deg改为3即可。 2
-
关联规则:关联规则反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。Apriori算法利用频繁项集生成关联规则。它基于频繁项集的子集也必须是频繁项集的概念。频繁项集是支持值大于阈值(support)的项集。