
Java 中HashCode作用_动力节点Java学院整理

第1 部分 hashCode的作用
Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的。对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢?通过迭代来equals()是否相等。数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化)。比如我们向HashSet插入1000数据,难道我们真的要迭代1000次,调用1000次equals()方法吗?hashCode提供了解决方案。怎么实现?我们先看hashCode的源码(Object)。
public native int hashCode();
它是一个本地方法,它的实现与本地机器有关,这里我们暂且认为他返回的是对象存储的物理位置(实际上不是,这里写是便于理解)。当我们向一个集合中添加某个元素,集合会首先调用hashCode方法,这样就可以直接定位它所存储的位置,若该处没有其他元素,则直接保存。若该处已经有元素存在,就调用equals方法来匹配这两个元素是否相同,相同则不存,不同则散列到其他位置。这样处理,当我们存入大量元素时就可以大大减少调用equals()方法的次数,极大地提高了效率。
所以hashCode在上面扮演的角色为寻域(寻找某个对象在集合中区域位置)。hashCode可以将集合分成若干个区域,每个对象都可以计算出他们的hash码,可以将hash码分组,每个分组对应着某个存储区域,根据一个对象的hash码就可以确定该对象所存储区域,这样就大大减少查询匹配元素的数量,提高了查询效率。
如何理解hashCode的作用:
以java.lang.Object来理解,JVM每new一个Object,它都会将这个Object丢到一个Hash哈希表中去,这样的话,下次做Object的比较或者取这个对象的时候,它会根据对象的hashcode再从Hash表中取这个对象。这样做的目的是提高取对象的效率。具体过程是这样:
1.new Object(),JVM根据这个对象的Hashcode值,放入到对应的Hash表对应的Key上,如果不同的对象确产生了相同的hash值,也就是发生了Hash key相同导致冲突的情况,那么就在这个Hash key的地方产生一个链表,将所有产生相同hashcode的对象放到这个单链表上去,串在一起。
2.比较两个对象的时候,首先根据他们的hashcode去hash表中找他的对象,当两个对象的hashcode相同,那么就是说他们这两个对象放在Hash表中的同一个key上,那么他们一定在这个key上的链表上。那么此时就只能根据Object的equal方法来比较这个对象是否equal。当两个对象的hashcode不同的话,肯定他们不能equal.
java.lang.Object中对hashCode的约定:
1. 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,则对该对象调用hashCode方法多次,它必须始终如一地返回同一个整数。
2. 如果两个对象根据equals(Object o)方法是相等的,则调用这两个对象中任一对象的hashCode方法必须产生相同的整数结果。
3. 如果两个对象根据equals(Object o)方法是不相等的,则调用这两个对象中任一个对象的hashCode方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
有一个概念要牢记,两个相等对象的equals方法一定为true, 但两个hashcode相等的对象不一定是相等的对象。
所以hashcode相等只能保证两个对象在一个HASH表里的同一条HASH链上,继而通过equals方法才能确定是不是同一对象,如果结果为true, 则认为是同一对象在插入,否则认为是不同对象继续插入。
第2部分 hashCode对于一个对象的重要性
一个对象的HashCode就是一个简单的Hash算法的实现,虽然它和那些真正的复杂的Hash算法相比还不能叫真正的算法,它如何实现它,不仅仅是程序员的编程水平问题, 而是关系到你的对象在存取是性能的非常重要的关系.有可能,不同的HashCode可能会使你的对象存取产生,成百上千倍的性能差别。先来看一下,在JAVA中两个重要的数据结构:HashMap和Hashtable,虽然它们有很大的区别,如继承关系不同,对value的约束条件(是否允许null)不同,以及线程安全性等有着特定的区别,但从实现原理上来说,它们是一致的。所以,只以Hashtable来说明:
在java中,存取数据的性能,一般来说当然是首推数组,但是在数据量稍大的容器选择中,Hashtable将有比数据性能更高的查询速度。具体原因看下面的内容,Hashtable在存储数据时,一般先将该对象的HashCode和0x7FFFFFFF做与操作,因为一个对象的HashCode可以为负数,这样操作后可以保证它为一个正整数。然后以Hashtable的长度取模,得到该对象在Hashtable中的索引。
int index = (hash & 0x7FFFFFFF) % tab.length;
这个对象就会直接放在Hashtable的每index位置,对于写入,这和数据一样,把一个对象放在其中的第index位置,但如果是查询,经过同样的算法,Hashtable可以直接从第index取得这个对象,而数组却要做循环比较.所以对于数据量稍大时,Hashtable的查询比数据具有更高的性能。
既然一个对象可以根据HashCode直接定位它在Hashtable中的位置,那么为什么Hashtable还要用key来做映射呢?这就是关系Hashtable性能问题的最重要的问题:Hash冲突。
常见的Hash冲突是不同对象最终产生了相同的索引,而一种非常甚至绝对少见的Hash冲突是,如果一组对象的个数大过了int 范围,而HashCode的长度只能在int范围中,所以肯定要有同一组的元素有相同的HashCode,这样无论如何他们都会有相同的 索引。当然这种极端的情况是极少见的,可以暂不考虑,但是对于同的HashCode经过取模,则会产生相同的索引,或者不同 的对象却具有相同的HashCode,当然具有相同的索引。所以对于索引相同的对象,在该index位置存放了多个值,这些值要想能正确区分,就要依靠key来识别。事实上一个设计各好的HashTable,一般来说会比较平均地分布每个元素,因为Hashtable的长度总是比实际元素的个数按一 定比例进行自增(装填因子一般为0.75)左右,这样大多数的索引位置只有一个对象,而很少的位置会有几个元素,所以 Hashtable中的每个位置存放的是一个链表,对于只有一个对象是位置,链表只有一个首节点(Entry),Entry的next为null。然后有hashCode,key,value属性保存了该位置的对象的HashCode,key和value(对象本身),如果有相同索引的对象进来则 会进入链表的下一个节点。如果同一个索引中有多个对象,根据HashCode和key可以在该链表中找到一个和查询的key相匹配的对象。
从上面我看可以看到,对于HashMap和Hashtable的存取性能有重大影响的首先是应该使该数据结构中的元素尽量大可能具有不同的HashCode,虽然这并不能保证不同的HashCode产生不同的index,但相同的HashCode一定产生相同的index,从而影响 产生Hash冲突。
对于一个象,如果具有很多属性,把所有属性都参与散列,显然是一种笨拙的设计。因为对象的HashCode()方法几乎无所不在 地被自动调用,如equals比较,如果太多的对象参与了散列。那么需要的操作常数时间将会增加很大。所以,挑选哪些属性参与散列绝对是一个编程水平的问题。
我们知道,每次调用HashCode方法方法,都要重新 对方法内的参与散列的对象重新计算一次它们的HashCode的运算,如果一个对象的属性没有改变,仍然要每次都进行计算, 所以如果设置一个标记来缓存当前的散列码,只要当参与散列的对象改变时才重新计算,否则调用缓存的hashCode,这可以 从很大程度上提高性能。默认的实现是将对象内部地址转化为整数作为HashCode,这当然能保证每个对象具有不同的HasCode,因为不同的对象内部地 址肯定不同,但java语言并不能让程序员获取对象内部地址,所以,让每个对象产生不同的HashCode有着很多可研究 的技术。如果从多个属性中采样出能具有平均分布的hashCode的属性,这是一个性能和多样性相矛盾的地方,如果所有属性都参与散 列,当然hashCode的多样性将大大提高,但牺牲了性能,而如果只能少量的属性采样散列,极端情况会产生大量的散列冲突 ,如对"人"的属性中,如果用性别而不是姓名或出生日期,那将只有两个或几个可选的hashcode值,将产生一半以上的散列 冲突.所以如果可能的条件下,专门产生一个序列用来生成HashCode将是一个好的选择(当然产生序列的性能要比所有属性参 与散列的性能高的情况下才行,否则还不如直接用所有属性散列). 如何对HashCode的性能和多样性求得一个平衡,可以参考相关算法设计的书,其实并不一定要求非常的优秀,只要能尽最大 可能减少散列值的聚集。重要的是我们应该记得HashCode对于我们的程序性能有着重要的影响,在程序设计时应该时时加以注 意.
请记住:如果你想有效的使用HashMap,你就必须重写在其的HashCode()。
还有两条重写HashCode()的原则:
1.不必对每个不同的对象都产生一个唯一的hashcode,只要你的HashCode方法使get()能够得到put()放进去的内容就可以了。即“不为一原则”。
2.生成hashcode的算法尽量使hashcode的值分散一些, 不要很多hashcode都集中在一个范围内,这样有利 于提高HashMap的性能。即“分散原则”。
至于第二条原则的具体原因,有兴趣者可以参考Bruce Eckel的《Thinking in Java》,在那里有对HashMap内部实现原理的介绍,这里就不赘述了。
第3部分 hashCode与equals
在Java中hashCode的实现总是伴随着equals,他们是紧密配合的,你要是自己设计了其中一个,就要设计另外一个。当然在多数情况下,这两个方法是不用我们考虑的,直接使用默认方法就可以帮助我们解决很多问题。但是在有些情况,我们必须要自己动手来实现它,才能确保程序更好的运作。
对于equals,我们必须遵循如下规则:
对称性:如果x.equals(y)返回是“true”,那么y.equals(x)也应该返回是“true”。
反射性:x.equals(x)必须返回是“true”。
类推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那么z.equals(x)也应该返回是“true”。
一致性:如果x.equals(y)返回是“true”,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是“true”。
任何情况下,x.equals(null),永远返回是“false”;x.equals(和x不同类型的对象)永远返回是“false”。
对于hashCode,我们应该遵循如下规则:
1. 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,则对该对象调用hashCode方法多次,它必须始终如一地返回同一个整数。
2. 如果两个对象根据equals(Object o)方法是相等的,则调用这两个对象中任一对象的hashCode方法必须产生相同的整数结果。
3. 如果两个对象根据equals(Object o)方法是不相等的,则调用这两个对象中任一个对象的hashCode方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
至于两者之间的关联关系,我们只需要记住如下即可:
如果x.equals(y)返回“true”,那么x和y的hashCode()必须相等。
如果x.equals(y)返回“false”,那么x和y的hashCode()有可能相等,也有可能不等。
理清了上面的关系我们就知道他们两者是如何配合起来工作的。先看下图:
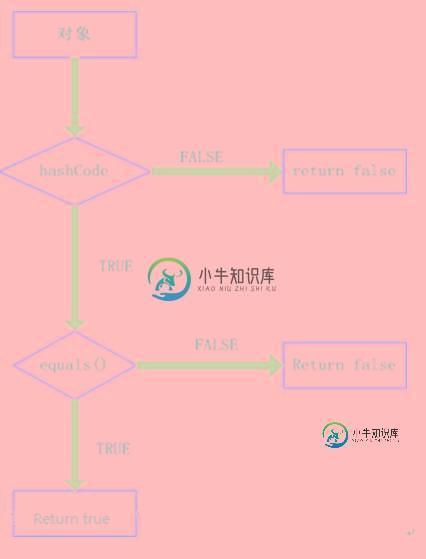
整个处理流程是:
1、判断两个对象的hashcode是否相等,若不等,则认为两个对象不等,完毕,若相等,则比较equals。
2、若两个对象的equals不等,则可以认为两个对象不等,否则认为他们相等。
实例:
package com.weakHashMap;
/**
* 重新实现了hashCode方法和equals方法
* @ClassName: Person
*
*
*/
public class Person {
private int age;
private int sex; // 0:男,1:女
private String name;
private final int PRIME = 37;
Person(int age ,int sex ,String name){
this.age = age;
this.sex = sex;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getSex() {
return sex;
}
public void setSex(int sex) {
this.sex = sex;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public int hashCode() {
System.out.println("调用hashCode方法...........");
int hashResult = 1;
hashResult = (hashResult + Integer.valueOf(age).hashCode() + Integer.valueOf(sex).hashCode()) * PRIME;
hashResult = PRIME * hashResult + ((name == null) ? 0 : name.hashCode());
System.out.println("name:"+name +" hashCode:" + hashResult);
return hashResult;
}
/**
* 重写hashCode()
*/
public boolean equals(Object obj) {
System.out.println("调用equals方法...........");
if(obj == null){
return false;
}
if(obj.getClass() != this.getClass()){
return false;
}
if(this == obj){
return true;
}
Person person = (Person) obj;
if(getAge() != person.getAge() || getSex()!= person.getSex()){
return false;
}
if(getName() != null){
if(!getName().equals(person.getName())){
return false;
}
}
else if(person != null){
return false;
}
return true;
}
}
package com.weakHashMap;
import java.util.HashSet;
import java.util.Set;
/**
*
* @ClassName: test1
* TODO *
*
*/
public class test extends Person{
/**
* @param age
* @param sex
* @param name
*/
test(int age, int sex, String name) {
super(age, sex, name);
// TODO Auto-generated constructor stub
}
public static void main(String[] args){
Set<Person> set = new HashSet<Person>();
Person p1 = new Person(11, 1, "张三");
Person p2 = new Person(12, 1, "李四");
Person p3 = new Person(11, 1, "张三");
Person p4 = new Person(11, 1, "李四");
//只验证p1、p3
System.out.println("p1 == p3? :" + (p1 == p3));
System.out.println("p1.equals(p3)?:"+p1.equals(p3));
System.out.println("-----------------------分割线--------------------------");
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
System.out.println("set.size()="+set.size());
}
}
结果:
p1 == p3? :false 调用equals方法........... p1.equals(p3)?:true -----------------------分割线-------------------------- 调用hashCode方法........... name:张三 hashCode:792686 调用hashCode方法........... name:李四 hashCode:861227 调用hashCode方法........... name:张三 hashCode:792686 调用equals方法........... 调用hashCode方法........... name:李四 hashCode:859858 set.size()=3
可以看到张三的两次hashCode相同,调用equals进行匹配,最后hashCode 和 equals 都返回true,则不添加。
以上所述是小编给大家介绍的Java 中HashCode作用_动力节点Java学院整理,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对小牛知识库网站的支持!
-
本文向大家介绍Java接口的作用_动力节点Java学院整理,包括了Java接口的作用_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 1. 接口是一种规范 很好,你已经知道接口是一种规范了! 下面这张图是我们生活中遇到的接口:电源插座接口。 2. 为什么需要规范呢? 因为有了接口规范: • 任何电器只有有符合规范的插头,就可以获得电力 • 任何厂家(西门子插座,TCL插座,公牛插
-
本文向大家介绍Java死锁_动力节点Java学院整理,包括了Java死锁_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 死锁是两个甚至多个线程被永久阻塞时的一种运行局面,这种局面的生成伴随着至少两个线程和两个或者多个资源。在这里我已写好一个简单的程序,它将会引起死锁方案然后我们就会明白如何分析它。 Java死锁范例 ThreadDeadlock.java 在上面的程序中同步线程
-
本文向大家介绍Java多态(动力节点Java学院整理),包括了Java多态(动力节点Java学院整理)的使用技巧和注意事项,需要的朋友参考一下 什么是多态 1. 面向对象的三大特性:封装、继承、多态。从一定角度来看,封装和继承几乎都是为多态而准备的。这是我们最后一个概念,也是最重要的知识点。 2. 多态的定义:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行
-
本文向大家介绍Java中StringBuffer和StringBuilder_动力节点Java学院整理,包括了Java中StringBuffer和StringBuilder_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 下面先给大家介绍下String、StringBuffer、StringBuilder区别,具体详情如下所示: StringBuffer、StringBuilde
-
本文向大家介绍ztree简介_动力节点Java学院整理,包括了ztree简介_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 【简介】 zTree 是利用 JQuery 的核心代码,实现一套能完成大部分常用功能的 Tree 插件 zTree是一个依靠jQuery实现的多功能“树插件”。优异的性能、灵活的配置、多种功能的组合是zTree最大优点。 官方文档:http://www.t
-
本文向大家介绍ThreadLocal简介_动力节点Java学院整理,包括了ThreadLocal简介_动力节点Java学院整理的使用技巧和注意事项,需要的朋友参考一下 ThreadLocal,直译为“线程本地”或“本地线程”,如果你真的这么认为,那就错了!其实,它就是一个容器,用于存放线程的局部变量,我认为应该叫做 ThreadLocalVariable(线程局部变量)才对,真不理解为什么当初 S