
php使用pthreads v3多线程实现抓取新浪新闻信息操作示例

本文实例讲述了php使用pthreads v3多线程实现抓取新浪新闻信息。分享给大家供大家参考,具体如下:
我们使用pthreads,来写一个多线程的抓取页面小程序,把结果存到数据库里。
数据表结构如下:
CREATE TABLE `tb_sina` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `url` varchar(256) DEFAULT '' COMMENT 'url地址', `title` varchar(128) DEFAULT '' COMMENT '标题', `time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sina新闻';
代码如下:
<?php
class DB extends Worker
{
private static $db;
private $dsn;
private $root;
private $pwd;
public function __construct($dsn, $root, $pwd)
{
$this->dsn = $dsn;
$this->root = $root;
$this->pwd = $pwd;
}
public function run()
{
//创建连接对象
self::$db = new PDO($this->dsn, $this->root, $this->pwd);
//把require放到worker线程中,不要放到主线程中,不然会报错找不到类
require './vendor/autoload.php';
}
//返回一个连接资源
public function getConn()
{
return self::$db;
}
}
class Sina extends Thread
{
private $name;
private $url;
public function __construct($name, $url)
{
$this->name = $name;
$this->url = $url;
}
public function run()
{
$db = $this->worker->getConn();
if (empty($db) || empty($this->url)) {
return false;
}
$content = file_get_contents($this->url);
if (!empty($content)) {
//获取标题,地址,时间
$data = QL\QueryList::Query($content, [
'tit' => ['.c_tit > a', 'text'],
'url' => ['.c_tit > a', 'href'],
'time' => ['.c_time', 'text'],
], '', 'UTF-8', 'GB2312')->getData();
//把获取的数据插入数据库
if (!empty($data)) {
$sql = 'INSERT INTO tb_sina(`url`, `title`, `time`) VALUES';
foreach ($data as $row) {
//修改下时间,新浪的时间格式是这样的04-23 15:30
$time = date('Y') . '-' . $row['time'] . ':00';
$sql .= "('{$row['url']}', '{$row['tit']}', '{$time}'),";
}
$sql = rtrim($sql, ',');
$ret = $db->exec($sql);
if ($ret !== false) {
echo "线程{$this->name}成功插入{$ret}条数据\n";
} else {
var_dump($db->errorInfo());
}
}
}
}
}
//抓取页面地址
$url = 'http://roll.news.sina.com.cn/s/channel.php?ch=01#col=89&spec=&type=&ch=01&k=&offset_page=0&offset_num=0&num=60&asc=&page=';
//创建pool池
$pool = new Pool(5, 'DB', ['mysql:dbname=test;host=192.168.33.226', 'root', '']);
//获取100个分页数据
for ($ix = 1; $ix <= 100; $ix++) {
$pool->submit(new Sina($ix, $url . $ix));
}
//循环收集垃圾,阻塞主线程,等待子线程结束
while ($pool->collect()) ;
$pool->shutdown();
由于使用到了QueryList,大家可以通过composer进行安装。
composer require jaeger/querylist
不过安装的版本是3.2,在我的php7.2下会有问题,由于each()已经被废弃,所以修改下源码,each()全换成foreach()就好了。
运行结果如下:
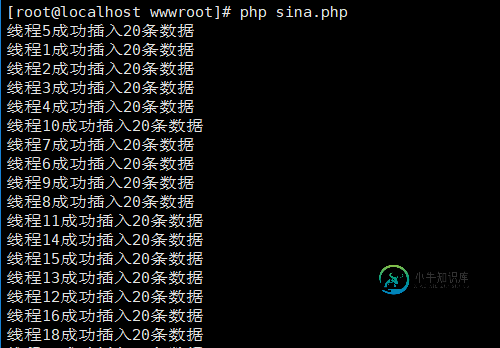
数据也保存进了数据库
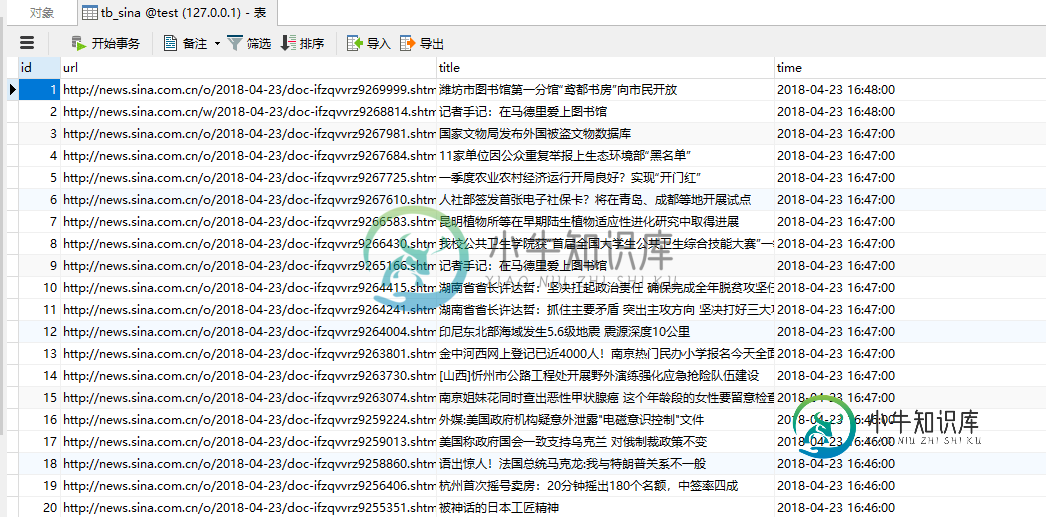
当然大家也可以再次通过url,拿到具体的页面内容,这里就不做演示了,有兴趣的可以自已去实现。
更多关于PHP相关内容感兴趣的读者可查看本站专题:《PHP进程与线程操作技巧总结》、《PHP网络编程技巧总结》、《PHP基本语法入门教程》、《PHP数组(Array)操作技巧大全》、《php字符串(string)用法总结》、《php+mysql数据库操作入门教程》及《php常见数据库操作技巧汇总》
希望本文所述对大家PHP程序设计有所帮助。
-
本文向大家介绍PHP使用Pthread实现的多线程操作实例,包括了PHP使用Pthread实现的多线程操作实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP使用Pthread实现的多线程操作。分享给大家供大家参考,具体如下: 希望本文所述对大家php程序设计有所帮助。
-
本文向大家介绍使用Ruby程序实现web信息抓取的教程,包括了使用Ruby程序实现web信息抓取的教程的使用技巧和注意事项,需要的朋友参考一下 网站不再单单迎合人类读者。许多站点现在支持一些 API,这些 API 使计算机程序能够获取信息。屏幕抓取 —— 将 HTML 页面解析为更容易理解的表单的省时技术 — 仍然很方便。但使用 API 简化 Web 数据提取的机会在快速增多。根据 Program
-
本文向大家介绍python实现多线程抓取知乎用户,包括了python实现多线程抓取知乎用户的使用技巧和注意事项,需要的朋友参考一下 需要用到的包: beautifulsoup4 html5lib image requests redis PyMySQL pip安装所有依赖包: 运行环境需要支持中文 测试运行环境python3.5,不保证其他运行环境能完美运行 需要安装mysql和redis 配置
-
本文向大家介绍Java爬虫 信息抓取的实现,包括了Java爬虫 信息抓取的实现的使用技巧和注意事项,需要的朋友参考一下 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点时间写了个demo供演示使用。 思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据。技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么
-
本文向大家介绍使用Python程序抓取新浪在国内的所有IP的教程,包括了使用Python程序抓取新浪在国内的所有IP的教程的使用技巧和注意事项,需要的朋友参考一下 数据分析,特别是网站分析中需要对访问者的IP进行分析,分析IP中主要是区分来访者的省份+城市+行政区数据,考虑到目前纯真IP数据库并没有把这些数据做很好的区分,于是寻找了另外一个可行的方案(当然不是花钱买哈)。解决方案就是抓取新浪的IP
-
本文向大家介绍asp.net实现遍历Request的信息操作示例,包括了asp.net实现遍历Request的信息操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了asp.net实现遍历Request的信息操作。分享给大家供大家参考,具体如下: #需求: 在服务端获取从客户端发送过来的所有数据信息; #方案: 1、服务端代码 2、使用postman模拟发送数据 1)、query_