
理解Android硬件加速原理(小白文)

前言
硬件加速,直观上说就是依赖 GPU 实现图形绘制加速,同软硬件加速的区别主要是图形的绘制究竟是 GPU 来处理还是 CPU,如果是GPU,就认为是硬件加速绘制,反之,软件绘制。在 Android 中也是如此,不过相对于普通的软件绘制,硬件加速还做了其他方面优化,不仅仅限定在绘制方面,绘制之前,在如何构建绘制区域上,硬件加速也做出了很大优化,因此硬件加速特性可以从下面两部分来分析:
1、前期策略:如何构建需要绘制的区域
2、后期绘制:单独渲染线程,依赖 GPU 进行绘制
无论是软件绘制还是硬件加速,绘制内存的分配都是类似的,都是需要请求 SurfaceFlinger 服务分配一块内存,只不过硬件加速有可能从FrameBuffer 硬件缓冲区直接分配内存(SurfaceFlinger 一直这么干的),两者的绘制都是在APP端,绘制完成之后同样需要通知SurfaceFlinger 进行合成,在这个流程上没有任何区别,真正的区别在于在 APP 端如何完成UI数据绘制,本文就直观的了解下两者的区别,会涉及部分源码,但不求甚解。
软硬件加速的分歧点
大概从 Android 4.+开始,默认情况下都是支持跟开启了硬件加速的,也存在手机支持硬件加速,但是部分API不支持硬件加速的情况,如果使用了这些API,就需要主关闭硬件加速,或者在 View 层,或者在Activity 层,比如 Canvas 的 clipPath等。但是,View 的绘制是软件加速实现的还是硬件加速实现的,一般在开发的时候并不可见,那图形绘制的时候,软硬件的分歧点究竟在哪呢?举个例子,有个 View 需要重绘,一般会调用 View 的 invalidate,触发重绘,跟着这条线走,去查一下分歧点。
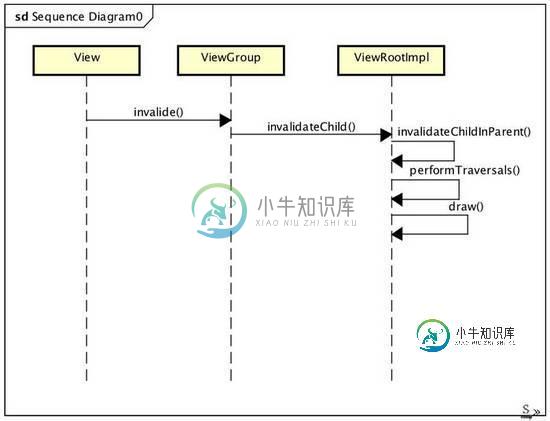
从上面的调用流程可以看出,视图重绘最后会进入ViewRootImpl的draw,这里有个判断点是软硬件加速的分歧点,简化后如下
ViewRootImpl.java
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
<!--关键点1 是否开启硬件加速-->
if (mAttachInfo.mHardwareRenderer != null && mAttachInfo.mHardwareRenderer.isEnabled()) {
...
dirty.setEmpty();
mBlockResizeBuffer = false;
<!--关键点2 硬件加速绘制-->
mAttachInfo.mHardwareRenderer.draw(mView, mAttachInfo, this);
} else {
...
<!--关键点3 软件绘制-->
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {
return;
}
...
关键点1是启用硬件加速的条件,必须支持硬件并且开启了硬件加速才可以,满足,就利用 HardwareRenderer.draw,否则 drawSoftware(软件绘制)。简答看一下这个条件,默认情况下,该条件是成立的,因为4.+之后的手机一般都支持硬件加速,而且在添加窗口的时候,ViewRootImpl 会 enableHardwareAcceleration 开启硬件加速,new HardwareRenderer,并初始化硬件加速环境。
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
<!--根据配置,获取硬件加速的开关-->
// Try to enable hardware acceleration if requested
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
if (hardwareAccelerated) {
...
<!--新建硬件加速图形渲染器-->
mAttachInfo.mHardwareRenderer = HardwareRenderer.create(mContext, translucent);
if (mAttachInfo.mHardwareRenderer != null) {
mAttachInfo.mHardwareRenderer.setName(attrs.getTitle().toString());
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
...
其实到这里软件绘制跟硬件加速的分歧点已经找到了,就是ViewRootImpl在draw 的时候,如果需要硬件加速就利用 HardwareRenderer 进行 draw,否则走软件绘制流程,drawSoftware其实很简单,利用 Surface.lockCanvas,向 SurfaceFlinger 申请一块匿名共享内存内存分配,同时获取一个普通的 SkiaCanvas,用于调用Skia 库,进行图形绘制,
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
final Canvas canvas;
try {
<!--关键点1 -->
canvas = mSurface.lockCanvas(dirty);
..
<!--关键点2 绘制-->
mView.draw(canvas);
..
关键点3 通知SurfaceFlinger进行图层合成
surface.unlockCanvasAndPost(canvas);
} ...
return true; }
drawSoftware 工作完全由 CPU 来完成,不会牵扯到 GPU 的操作,下面重点看下 HardwareRenderer 所进行的硬件加速绘制。
HardwareRenderer 硬件加速绘制模型
开头说过,硬件加速绘制包括两个阶段:构建阶段+绘制阶段,所谓构建就是递归遍历所有视图,将需要的操作缓存下来,之后再交给单独的Render 线程利用 OpenGL 渲染。在 Android 硬件加速框架中,View视图被抽象成 RenderNode 节点,View 中的绘制都会被抽象成一个个DrawOp(DisplayListOp),比如 View 中 drawLine,构建中就会被抽象成一个 DrawLintOp,drawBitmap 操作会被抽象成DrawBitmapOp,每个子 View 的绘制被抽象成DrawRenderNodeOp,每个 DrawOp 有对应的 OpenGL 绘制命令,同时内部也握着绘图所需要的数据。如下所示:
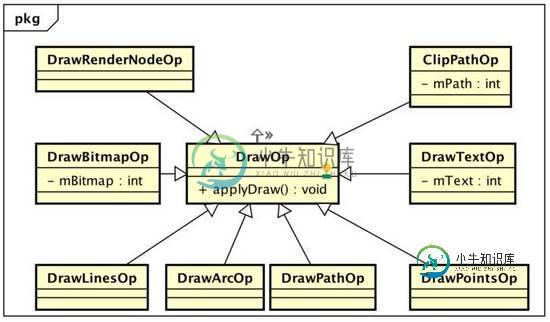
绘图Op抽象
如此以来,每个 View 不仅仅握有自己 DrawOp List,同时还拿着子View的绘制入口,如此递归,便能够统计到所有的绘制Op,很多分析都称为 Display List,源码中也是这么来命名类的,不过这里其实更像是一个树,而不仅仅是List,示意如下:
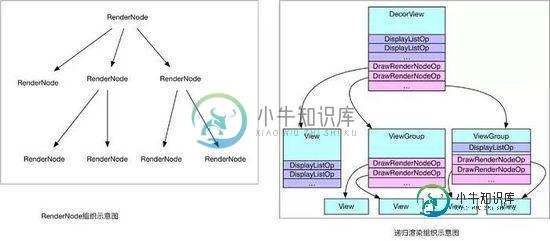
硬件加速.jpg
构建完成后,就可以将这个绘图Op树交给Render线程进行绘制,这里是同软件绘制很不同的地方,软件绘制时,View一般都在主线程中完成绘制,而硬件加速,除非特殊要求,一般都是在单独线程中完成绘制,如此以来就分担了主线程很多压力,提高了UI线程的响应速度。
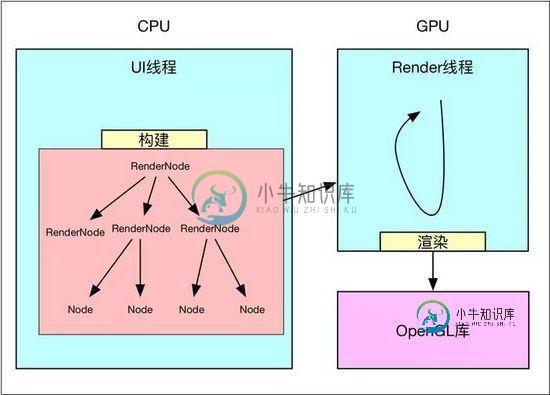
硬件加速模型.jpg
知道整个模型后,就代码来简单了解下实现流程,先看下递归构建RenderNode 树及 DrawOp 集。
利用HardwareRenderer构建DrawOp集
HardwareRenderer 是整个硬件加速绘制的入口,实现是一个ThreadedRenderer 对象,从名字能看出,ThreadedRenderer应该跟一个Render线程息息相关,不过ThreadedRenderer是在UI线程中创建的,那么与UI线程也必定相关,其主要作用:
1、在UI线程中完成DrawOp集构建
2、负责跟渲染线程通信
可见ThreadedRenderer的作用是很重要的,简单看一下实现:
ThreadedRenderer(Context context, boolean translucent) {
...
<!--新建native node-->
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
<!--新建NativeProxy-->
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
ProcessInitializer.sInstance.init(context, mNativeProxy);
loadSystemProperties();
}
从上面代码看出,ThreadedRenderer中有一个RootNode用来标识整个DrawOp树的根节点,有个这个根节点就可以访问所有的绘制Op,同时还有个RenderProxy对象,这个对象就是用来跟渲染线程进行通信的句柄,看一下其构造函数:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())
, mContext(nullptr) {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
mDrawFrameTask.setContext(&mRenderThread, mContext);
}
从RenderThread::getInstance()可以看出,RenderThread是一个单例线程,也就是说,每个进程最多只有一个硬件渲染线程,这样就不会存在多线程并发访问冲突问题,到这里其实环境硬件渲染环境已经搭建好好了。下面就接着看ThreadedRenderer的draw函数,如何构建渲染Op树:
@Override
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
attachInfo.mIgnoreDirtyState = true;
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
<!--关键点1:构建View的DrawOp树-->
updateRootDisplayList(view, callbacks);
<!--关键点2:通知RenderThread线程绘制-->
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
...
}
只关心关键点1 updateRootDisplayList,构建RootDisplayList,其实就是构建View的DrawOp树,updateRootDisplayList会进而调用根View的updateDisplayListIfDirty,让其递归子View的updateDisplayListIfDirty,从而完成DrawOp树的创建,简述一下流程:
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
<!--更新-->
updateViewTreeDisplayList(view);
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
<!--获取DisplayListCanvas-->
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
<!--利用canvas缓存Op-->
final int saveCount = canvas.save();
canvas.translate(mInsetLeft, mInsetTop);
callbacks.onHardwarePreDraw(canvas);
canvas.insertReorderBarrier();
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
callbacks.onHardwarePostDraw(canvas);
canvas.restoreToCount(saveCount);
mRootNodeNeedsUpdate = false;
} finally {
<!--将所有Op填充到RootRenderNode-->
mRootNode.end(canvas);
}
}
}
利用View的RenderNode获取一个DisplayListCanvas
利用DisplayListCanvas构建并缓存所有的DrawOp
将DisplayListCanvas缓存的DrawOp填充到RenderNode
将根View的缓存DrawOp设置到RootRenderNode中,完成构建
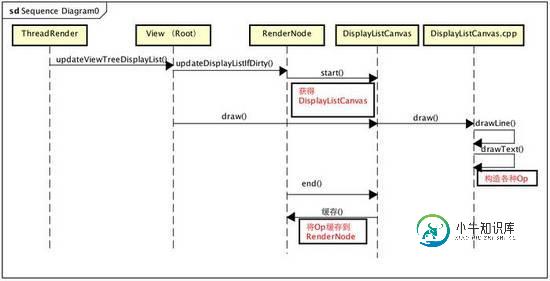
绘制流程
简单看一下View递归构建DrawOp,并将自己填充到
@NonNull
public RenderNode updateDisplayListIfDirty() {
final RenderNode renderNode = mRenderNode;
...
// start 获取一个 DisplayListCanvas 用于绘制 硬件加速
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
// 是否是textureView
final HardwareLayer layer = getHardwareLayer();
if (layer != null && layer.isValid()) {
canvas.drawHardwareLayer(layer, 0, 0, mLayerPaint);
} else if (layerType == LAYER_TYPE_SOFTWARE) {
// 是否强制软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
// 如果仅仅是ViewGroup,并且自身不用绘制,直接递归子View
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
dispatchDraw(canvas);
} else {
<!--调用自己draw,如果是ViewGroup会递归子View-->
draw(canvas);
}
}
} finally {
<!--缓存构建Op-->
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
return renderNode;
}
TextureView跟强制软件绘制的View比较特殊,有额外的处理,这里不关心,直接看普通的draw,假如在View onDraw中,有个drawLine,这里就会调用DisplayListCanvas的drawLine函数,DisplayListCanvas及RenderNode类图大概如下
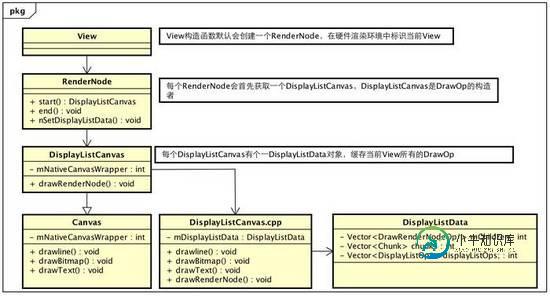
硬件加速类图
DisplayListCanvas的drawLine 函数最终会进入DisplayListCanvas.cpp的drawLine,
void DisplayListCanvas::drawLines(const float* points, int count, const SkPaint& paint) {
points = refBuffer<float>(points, count);
addDrawOp(new (alloc()) DrawLinesOp(points, count, refPaint(&paint)));
}
可以看到,这里构建了一个DrawLinesOp,并添加到DisplayListCanvas的缓存列表中去,如此递归便可以完成DrawOp树的构建,在构建后利用RenderNode的end函数,将DisplayListCanvas中的数据缓存到RenderNode中去:
public void end(DisplayListCanvas canvas) {
canvas.onPostDraw();
long renderNodeData = canvas.finishRecording();
<!--将DrawOp缓存到RenderNode中去-->
nSetDisplayListData(mNativeRenderNode, renderNodeData);
// canvas 回收掉]
canvas.recycle();
mValid = true;
}
如此,便完成了DrawOp树的构建,之后,利用RenderProxy向RenderThread发送消息,请求OpenGL线程进行渲染。
RenderThread渲染UI到Graphic Buffer
DrawOp树构建完毕后,UI线程利用RenderProxy向RenderThread线程发送一个DrawFrameTask任务请求,RenderThread被唤醒,开始渲染,大致流程如下:
- 首先进行DrawOp的合并
- 接着绘制特殊的Layer
- 最后绘制其余所有的DrawOpList
- 调用swapBuffers将前面已经绘制好的图形缓冲区提交给Surface Flinger合成和显示。
不过再这之前先复习一下绘制内存的由来,毕竟之前DrawOp树的构建只是在普通的用户内存中,而部分数据对于SurfaceFlinger都是不可见的,之后又绘制到共享内存中的数据才会被SurfaceFlinger合成,之前分析过软件绘制的UI是来自匿名共享内存,那么硬件加速的共享内存来自何处呢?到这里可能要倒回去看看 ViewRootImlp
private void performTraversals() {
...
if (mAttachInfo.mHardwareRenderer != null) {
try {
hwInitialized = mAttachInfo.mHardwareRenderer.initialize(
mSurface);
if (hwInitialized && (host.mPrivateFlags
& View.PFLAG_REQUEST_TRANSPARENT_REGIONS) == 0) {
mSurface.allocateBuffers();
}
} catch (OutOfResourcesException e) {
handleOutOfResourcesException(e);
return;
}
}
....
/**
* Allocate buffers ahead of time to avoid allocation delays during rendering
* @hide
*/
public void allocateBuffers() {
synchronized (mLock) {
checkNotReleasedLocked();
nativeAllocateBuffers(mNativeObject);
}
}
可以看出,对于硬件加速的场景,内存分配的时机会稍微提前,而不是像软件绘制事,由Surface的lockCanvas发起,主要目的是:避免在渲染的时候再申请,一是避免分配失败,浪费了CPU之前的准备工作,二是也可以将渲染线程个工作简化,在分析Android窗口管理分析(4):Android View绘制内存的分配、传递、使用的时候分析过,在分配成功后,如果有必要,会进行一次UI数据拷贝,这是局部绘制的根基,也是保证DrawOp可以部分执行的基础,到这里内存也分配完毕。不过,还是会存在另一个问题,一个APP进程,同一时刻会有过个Surface绘图界面,但是渲染线程只有一个,那么究竟渲染那个呢?这个时候就需要将Surface与渲染线程(上下文)绑定。
static jboolean android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
sp<ANativeWindow> window = android_view_Surface_getNativeWindow(env, jsurface);
return proxy->initialize(window);
}
首先通过android_view_Surface_getNativeWindowSurface获取Surface,在Native层,Surface对应一个ANativeWindow,接着,通过RenderProxy类的成员函数initialize将前面获得的ANativeWindow绑定到RenderThread
bool RenderProxy::initialize(const sp<ANativeWindow>& window) {
SETUP_TASK(initialize);
args->context = mContext;
args->window = window.get();
return (bool) postAndWait(task);
}
仍旧是向渲染线程发送消息,让其绑定当前Window,其实就是调用CanvasContext的initialize函数,让绘图上下文绑定绘图内存:
bool CanvasContext::initialize(ANativeWindow* window) {
setSurface(window);
if (mCanvas) return false;
mCanvas = new OpenGLRenderer(mRenderThread.renderState());
mCanvas->initProperties();
return true;
}
CanvasContext通过setSurface将当前要渲染的Surface绑定到到RenderThread中,大概流程是通过eglApi获得一个EGLSurface,EGLSurface封装了一个绘图表面,进而,通过eglApi将EGLSurface设定为当前渲染窗口,并将绘图内存等信息进行同步,之后通过RenderThread绘制的时候才能知道是在哪个窗口上进行绘制。这里主要是跟OpenGL库对接,所有的操作最终都会归结到eglApi抽象接口中去。假如,这里不是Android,是普通的Java平台,同样需要相似的操作,进行封装处理,并绑定当前EGLSurface才能进行渲染,因为OpenGL是一套规范,想要使用,就必须按照这套规范走。之后,再创建一个OpenGLRenderer对象,后面执行OpenGL相关操作的时候,其实就是通过OpenGLRenderer来进行的。

绑定流程
上面的流程走完,有序DrawOp树已经构建好、内存也已分配好、环境及场景也绑定成功,剩下的就是绘制了,不过之前说过,真正调用OpenGL绘制之前还有一些合并操作,这是Android硬件加速做的优化,回过头继续走draw流程,其实就是走OpenGLRenderer的drawRenderNode进行递归处理:
void OpenGLRenderer::drawRenderNode(RenderNode* renderNode, Rect& dirty, int32_t replayFlags) {
...
<!--构建deferredList-->
DeferredDisplayList deferredList(mState.currentClipRect(), avoidOverdraw);
DeferStateStruct deferStruct(deferredList, *this, replayFlags);
<!--合并及分组-->
renderNode->defer(deferStruct, 0);
<!--绘制layer-->
flushLayers();
startFrame();
<!--绘制 DrawOp树-->
deferredList.flush(*this, dirty);
...
}
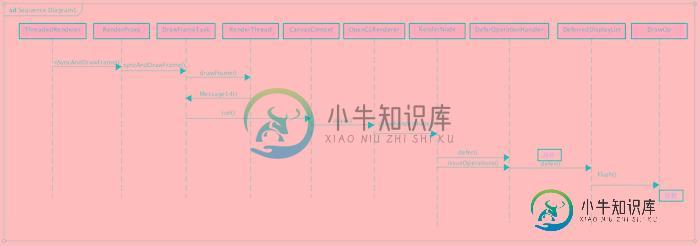
硬件加速渲染流程
先看下renderNode->defer(deferStruct, 0),合并操作,DrawOp树并不是直接被绘制的,而是首先通过DeferredDisplayList进行一个合并优化,这个是Android硬件加速中采用的一种优化手段,不仅可以减少不必要的绘制,还可以将相似的绘制集中处理,提高绘制速度。
void RenderNode::defer(DeferStateStruct& deferStruct, const int level) {
DeferOperationHandler handler(deferStruct, level);
issueOperations<DeferOperationHandler>(deferStruct.mRenderer, handler);
}
RenderNode::defer其实内含递归操作,比如,如果当前RenderNode代表DecorView,它就会递归所有的子View进行合并优化处理,简述一下合并及优化的流程及算法,其实主要就是根据DrawOp树构建DeferedDisplayList,defer本来就有延迟的意思,对于DrawOp的合并有两个必要条件,
1:两个DrawOp的类型必须相同,这个类型在合并的时候被抽象为Batch ID,取值主要有以下几种
enum OpBatchId {
kOpBatch_None = 0, // Don't batch
kOpBatch_Bitmap,
kOpBatch_Patch,
kOpBatch_AlphaVertices,
kOpBatch_Vertices,
kOpBatch_AlphaMaskTexture,
kOpBatch_Text,
kOpBatch_ColorText,
kOpBatch_Count, // Add other batch ids before this
};
2:DrawOp的Merge ID必须相同,Merge ID没有太多限制,由每个DrawOp自定决定,不过好像只有DrawPatchOp、DrawBitmapOp、DrawTextOp比较特殊,其余的似乎不需要考虑合并问题,即时是以上三种,合并的条件也很苛刻
在合并过程中,DrawOp被分为两种:需要合的与不需要合并的,并分别缓存在不同的列表中,无法合并的按照类型分别存放在Batch* mBatchLookup[kOpBatch_Count]中,可以合并的按照类型及MergeID存储到TinyHashMap<mergeid_t, DrawBatch*> mMergingBatches[kOpBatch_Count]中,示意图如下:
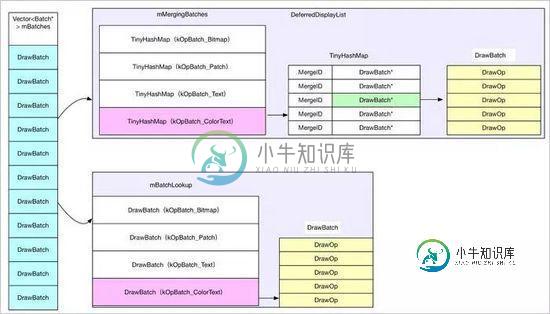
DrawOp合并操作.jpg
合并之后,DeferredDisplayList Vector<Batch> mBatches包含全部整合后的绘制命令,之后渲染即可,需要注意的是这里的合并并不是多个变一个,只是做了一个集合,主要是方便使用各资源纹理等,比如绘制文字的时候,需要根据文字的纹理进行渲染,而这个时候就需要查询文字的纹理坐标系,合并到一起方便统一处理,一次渲染,减少资源加载的浪费,当然对于理解硬件加速的整体流程,这个合并操作可以完全无视,甚至可以直观认为,构建完之后,就可以直接渲染,它的主要特点是在另一个Render线程使用OpenGL进行绘制,这个是它最重要的特点*。而mBatches中所有的DrawOp都会通过OpenGL被绘制到GraphicBuffer中,最后通过swapBuffers通知SurfaceFlinger合成。
总结
软件绘制同硬件合成的区别主要是在绘制上,内存分配、合成等整体流程是一样的,只不过硬件加速相比软件绘制算法更加合理,同时减轻了主线程的负担。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍浅谈Android硬件加速原理与实现简介,包括了浅谈Android硬件加速原理与实现简介的使用技巧和注意事项,需要的朋友参考一下 在手机客户端尤其是Android应用的开发过程中,我们经常会接触到“硬件加速”这个词。由于操作系统对底层软硬件封装非常完善,上层软件开发者往往对硬件加速的底层原理了解很少,也不清楚了解底层原理的意义,因此常会有一些误解,如硬件加速是不是通过特殊算法实现页面
-
如果你想深入了解光环板的硬件设计,可以下载光环板的硬件原理图。 硬件原理图下载
-
这简直快把我逼疯了,我找不到任何帮助。对于模拟器,我还是个新手,对于Android Studio更是如此。我的问题是:我安装了Android Studio。下载了SDK更新,包括HAXM一个,并建立了我自己的AVD。在尝试启动我的AVD或者甚至是已经存在的starter AVD时,我得到一个错误,说明“emulator:error:x86仿真当前需要硬件加速!” 有没有人对一个完整的Android
-
本文档为您详细阐释 MIP 页面的加速原理。 经过精心设计的 JavaScript 为了去除臃肿的客户端脚本,MIP 文件不允许自定义 JavaScript 。对一些强依赖 JavaScript 的功能(如:广告、统计和交互),MIP 提供与 MIP Runtime 兼容封装好的组件来实现。 JavaScript 引用原则: 目前 MIP 不允许用户自定义 JavaScript ,需要用 MIP
-
本文向大家介绍小白谈谈对JS原型链的理解,包括了小白谈谈对JS原型链的理解的使用技巧和注意事项,需要的朋友参考一下 原型链理解起来有点绕了,网上资料也是很多,每次晚上睡不着的时候总喜欢在网上找点原型链和闭包的文章看,效果极好。 不要纠结于那一堆术语了,那除了让你脑筋拧成麻花,真的不能帮你什么。简单粗暴点看原型链吧,想点与代码无关的事,比如人、妖以及人妖。 1)人是人他妈生的,妖是妖他妈生的。人和妖
-
问题内容: 我一直在花一些时间研究Java的硬件加速功能,但我仍然有些困惑,因为我在网上直接找到的任何站点都没有明确回答我所遇到的一些问题。因此,这是我对Java硬件加速的疑问: 1)在Eclipse版本3.6.0中,具有Mac OS X的最新Java更新(我认为是1.6u10),默认情况下是否启用硬件加速?我在某处读过 应该指示是否启用了硬件加速,并且当在我的主Canvas实例上运行以进行绘制时