
深入了解Java GC的工作原理

JVM学习笔记之JVM内存管理和JVM垃圾回收的概念,JVM内存结构由堆、栈、本地方法栈、方法区等部分组成,另外JVM分别对新生代下载地址 和旧生代采用不同的垃圾回收机制。
首先来看一下JVM内存结构,它是由堆、栈、本地方法栈、方法区等部分组成,结构图如下所示。
JVM学习笔记 JVM内存管理和JVM垃圾回收
JVM内存组成结构
JVM内存结构由堆、栈、本地方法栈、方法区等部分组成,结构图如下所示:
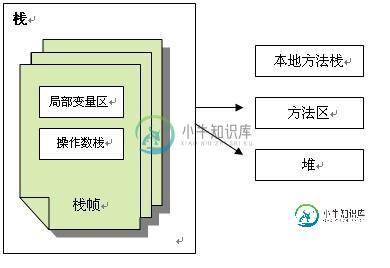
1)堆
所有通过new创建的对象的内存都在堆中分配,其大小可以通过-Xmx和-Xms来控制。堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区,最后Survivor由FromSpace和ToSpace组成,结构图如下所示:
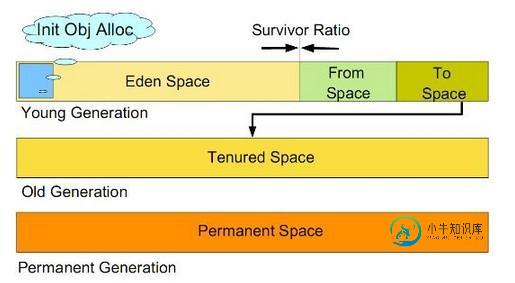
新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中,新生代大小可以由-Xmn来控制,也可以用-XX:SurvivorRatio来控制Eden和Survivor的比例旧生代。用于存放新生代中经过多次垃圾回收仍然存活的对象
2)栈
每个线程执行每个方法的时候都会在栈中申请一个栈帧,每个栈帧包括局部变量区和操作数栈,用于存放此次方法调用过程中的临时变量、参数和中间结果
3)本地方法栈
用于支持native方法的执行,存储了每个native方法调用的状态
4)方法区
存放了要加载的类信息、静态变量、final类型的常量、属性和方法信息。JVM用持久代(PermanetGeneration)来存放方法区,可通过-XX:PermSize和-XX:MaxPermSize来指定最小值和最大值。介绍完了JVM内存组成结构,下面我们再来看一下JVM垃圾回收机制下载地址 。
JVM垃圾回收机制
JVM分别对新生代和旧生代采用不同的垃圾回收机制
新生代的GC:
新生代通常存活时间较短,因此基于Copying算法来进行回收,所谓Copying算法就是扫描出存活的对象,并复制到一块新的完全未使用的空间中,对应于新生代,就是在Eden和FromSpace或ToSpace之间copy。新生代采用空闲指针的方式来控制GC触发,指针保持最后一个分配的对象在新生代区间的位置,当有新的对象要分配内存时,用于检查空间是否足够,不够就触发GC。当连续分配对象时,对象会逐渐从eden到survivor,最后到旧生代,
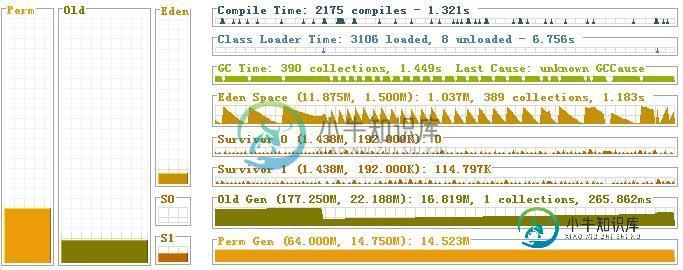
用javavisualVM来查看,能明显观察到新生代满了后,会把对象转移到旧生代,然后清空继续装载,当旧生代也满了后,就会报outofmemory的异常,如下图所示:
在执行机制上JVM提供了串行GC(SerialGC)、并行回收GC(ParallelScavenge)和并行GC(ParNew)
1)串行GC
在整个扫描和复制过程采用单线程的方式来进行,适用于单CPU、新生代空间较小及对暂停时间要求不是非常高的应用上,是client级别默认的GC方式,可以通过-XX:+UseSerialGC来强制指定
2)并行回收GC
在整个扫描和复制过程采用多线程的方式来进行,适用于多CPU、对暂停时间要求较短的应用上,是server级别默认采用的GC方式,可用-XX:+UseParallelGC来强制指定,用-XX:ParallelGCThreads=4来指定线程数
3)并行GC
与旧生代的并发GC配合使用
旧生代的GC:
旧生代与新生代不同,对象存活的时间比较长,比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并,要么标记出来便于下次进行分配,总之就是要减少内存碎片带来的效率损耗。在执行机制上JVM提供了串行GC(SerialMSC)、并行GC(parallelMSC)和并发GC(CMS),具体算法细节还有待进一步深入研究。
以上各种GC机制是需要组合使用的,指定方式由下表所示:

以上就是小编为大家带来的深入了解Java GC的工作原理全部内容了,希望大家多多支持小牛知识库~
-
此指令可与锁前缀一起使用,以允许指令原子执行。为了简化与处理器总线的接口,目的操作数接收一个写周期,而不考虑比较的结果。如果比较失败,则写回目标操作数;否则,将源操作数写入目标。 我很难理解最后一句(但可能也很难理解整个图表) 写回什么? 源操作数是什么?是吗?据我所知,这个CAS指令只接受一个操作数(内存目标)。 如果有人能重新措辞和/或解释关于无条件写入的这一点,我将不胜感激。
-
logstash 已经拥有数以百计的插件,并提供了一站式的部署方式,极大的方便了新手入门。但在实际运用上,我们终究会碰上其他人还没碰到过,或者碰到过但没公布出来完整解决方案的问题。可能是某些环境适配,可能是某个环节的性能不佳,可能是某处硬编码设置不合理,等等等等。这时候,了解一些 logstash 的代码逻辑,了解 logstash 之所以做出当前选择的缘由。是有助于解决实际问题的。 此外,log
-
正如标题所解释的,我有一个非常基本的编程问题,但我还没有找到。过滤掉所有(非常聪明的)“为了理解递归,你必须首先理解递归。”各种在线线程的回复我仍然不太明白。 当我们面对不知道自己不知道的事情时,我们可能会提出错误的问题或错误地提出正确的问题。我将分享我的“想法”。我的问题是希望有类似观点的人能够分享一些知识,帮助我打开递归灯泡! 以下是函数(语法用Swift编写): 我们将使用2和5作为参数:
-
问题内容: 我试图了解如何使用Golang和forks。情况如下,我在写一个依赖于library的库,这不是我的。 由于缺少我需要的一些方法,因此将其分叉到。但是,我不能只是这样做,库引用了自己,所以它坏了。 在本文中,他们提供了可能的解决方案: 现在,这充其量是hacky。从库代码中无法得知依赖项来自其他存储库。任何使用我的图书馆的人都无法使其正常运行。 由于dep有望成为正式的依赖管理器。我发
-
在这本教程的一开始 (第 6 章, 构建脚本基础) 你已经学习了如何创建简单的任务. 然后你也学习了如何给这些任务加入额外的行为, 以及如何在任务之间建立依赖关系. 这些仅仅是用来构建简单的任务. Gradle 可以创建更为强大复杂的任务. 这些任务可以有它们自己的属性和方法. 这一点正是和 Ant targets 不一样的地方. 这些强大的任务既可以由你自己创建也可以使用 Gradle 内建好的
-
本文向大家介绍深入了解Java atomic原子类的使用方法和原理,包括了深入了解Java atomic原子类的使用方法和原理的使用技巧和注意事项,需要的朋友参考一下 在讲atomic原子类之前先看一个小例子: 最终的输出结果为100,可见这个程序是线程安全的。如果把AtomicInteger换成变量i的话,那最终结果就不确定了。 打开AtomicInteger的源码可以看到: volatile关