
JAVA实现基于皮尔逊相关系数的相似度详解

最近在看《集体智慧编程》,相比其他机器学习的书籍,这本书有许多案例,更贴近实际,而且也很适合我们这种准备学习machinelearning的小白。
这本书我觉得不足之处在于,里面没有对算法的公式作讲解,而是直接用代码去实现,所以给想具体了解该算法带来了不便,所以想写几篇文章来做具体的说明。以下是第一篇,对皮尔逊相关系数作讲解,并采用了自己比较熟悉的java语言做实现。
皮尔逊数学公式如下,来自维基百科。
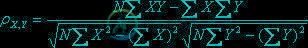
其中,E是数学期望,cov表示协方差,\sigma_X和\sigma_Y是标准差。
化简后得:
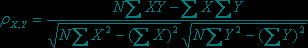

皮尔逊相似度计算的算法还是很简单的,实现起来也不难。只要求变量X、Y、乘积XY,X的平方,Y的平方的和。我的代码所使用的数据测试集来自《集体智慧编程》一书。代码如下:
package pearsonCorrelationScore;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
/**
* @author shenchao
*
* 皮尔逊相关度评价
*
* 以《集体智慧编程》一书用户评价相似度数据集做测试
*/
public class PearsonCorrelationScore {
private Map<String, Map<String, double>> dataset = null;
public PearsonCorrelationScore() {
initDataSet();
}
/**
* 初始化数据集
*/
private void initDataSet() {
dataset = new HashMap<String, Map<String, double>>();
// 初始化Lisa Rose 数据集
Map<String, double> roseMap = new HashMap<String, double>();
roseMap.put("Lady in the water", 2.5);
roseMap.put("Snakes on a Plane", 3.5);
roseMap.put("Just My Luck", 3.0);
roseMap.put("Superman Returns", 3.5);
roseMap.put("You, Me and Dupree", 2.5);
roseMap.put("The Night Listener", 3.0);
dataset.put("Lisa Rose", roseMap);
// 初始化Jack Matthews 数据集
Map<String, double> jackMap = new HashMap<String, double>();
jackMap.put("Lady in the water", 3.0);
jackMap.put("Snakes on a Plane", 4.0);
jackMap.put("Superman Returns", 5.0);
jackMap.put("You, Me and Dupree", 3.5);
jackMap.put("The Night Listener", 3.0);
dataset.put("Jack Matthews", jackMap);
// 初始化Jack Matthews 数据集
Map<String, double> geneMap = new HashMap<String, double>();
geneMap.put("Lady in the water", 3.0);
geneMap.put("Snakes on a Plane", 3.5);
geneMap.put("Just My Luck", 1.5);
geneMap.put("Superman Returns", 5.0);
geneMap.put("You, Me and Dupree", 3.5);
geneMap.put("The Night Listener", 3.0);
dataset.put("Gene Seymour", geneMap);
}
public Map<String, Map<String, double>> getDataSet() {
return dataset;
}
/**
* @param person1
* name
* @param person2
* name
* @return 皮尔逊相关度值
*/
public double sim_pearson(String person1, String person2) {
// 找出双方都评论过的电影,(皮尔逊算法要求)
List<String> list = new ArrayList<String>();
for (Entry<String, double> p1 : dataset.get(person1).entrySet()) {
if (dataset.get(person2).containsKey(p1.getKey())) {
list.add(p1.getKey());
}
}
double sumX = 0.0;
double sumY = 0.0;
double sumX_Sq = 0.0;
double sumY_Sq = 0.0;
double sumXY = 0.0;
int N = list.size();
for (String name : list) {
Map<String, double> p1Map = dataset.get(person1);
Map<String, double> p2Map = dataset.get(person2);
sumX += p1Map.get(name);
sumY += p2Map.get(name);
sumX_Sq += Math.pow(p1Map.get(name), 2);
sumY_Sq += Math.pow(p2Map.get(name), 2);
sumXY += p1Map.get(name) * p2Map.get(name);
}
double numerator = sumXY - sumX * sumY / N;
double denominator = Math.sqrt((sumX_Sq - sumX * sumX / N)
* (sumY_Sq - sumY * sumY / N));
// 分母不能为0
if (denominator == 0) {
return 0;
}
return numerator / denominator;
}
public static void main(String[] args) {
PearsonCorrelationScore pearsonCorrelationScore = new PearsonCorrelationScore();
System.out.println(pearsonCorrelationScore.sim_pearson("Lisa Rose",
"Jack Matthews"));
}
}
将各个测试集的数据反映到二维坐标面中,如下所示:
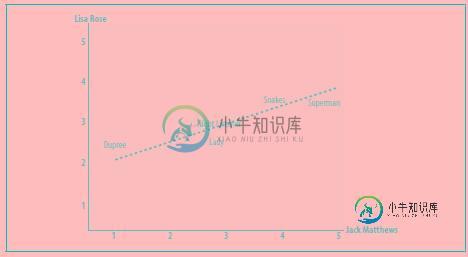
上述程序求得的值实际上就为该直线的斜率。其斜率的区间在[-1,1]之间,其绝对值的大小反映了两者相似度大小,斜率越大,相似度越大,当相似度为1时,该直线为一条对角线。
总结
以上就是本文关于JAVA实现基于皮尔逊相关系数的相似度详解的全部内容,希望对大家有所帮助。如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
-
本文向大家介绍Python 余弦相似度与皮尔逊相关系数 计算实例,包括了Python 余弦相似度与皮尔逊相关系数 计算实例的使用技巧和注意事项,需要的朋友参考一下 夹角余弦(Cosine) 也可以叫余弦相似度。 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。 (1)在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式: (2) 两个n维
-
我有火花数据帧,其中我有2个col让我们col1和col2与双精度数据类型。我想计算斯卡拉(在火花会话中)中的皮尔逊相关系数。
-
问题内容: 我需要计算BLEU分数来识别两个句子是否相似。我阅读了一些文章,这些文章主要涉及测量机器翻译准确性的BLEU分数。但是我需要BLEU分数来找出句子中相似度。相同的语言[英语]。(ie)(两个句子都是英语)。感谢您的期待。 问题答案: 好吧,如果您只是想计算BLEU分数,那很简单。将一个句子作为参考翻译,将另一个作为候选翻译。
-
我正在试图找出设置实体图的最佳方法。我将基于下面的图像进行解释。 TBLParentCustomer:此表存储主要客户的信息,主要客户可以是企业或消费者。(使用查找表TBLCustomerType标识这些客户。) TBLChildCustomer:此表存储主客户下的客户。主要业务客户可以有授权员工和授权代表,主要消费客户可以有授权用户。(它们是使用查找表TBLCustomerType标识的。) T
-
计算两个数据集的相关性是统计中的常用操作。在MLlib中提供了计算多个数据集两两相关的方法。目前支持的相关性方法有皮尔森(Pearson)相关和斯皮尔曼(Spearman)相关。 Statistics提供方法计算数据集的相关性。根据输入的类型,两个RDD[Double]或者一个RDD[Vector],输出将会是一个Double值或者相关性矩阵。下面是一个应用的例子。 import org.
-
问题内容: 我计算了两个文档的tf / idf值。以下是tf / idf值: 这些文件就像: 如何使用这些值来计算余弦相似度? 我知道我应该计算点积,然后找到距离并除以点积。如何使用我的值来计算? 还有一个问题: 两个文档的字数相同是否重要? 问题答案: a * b是点积 一些细节: 是。在某种程度上,a和b必须具有相同的长度。但是a和b通常具有稀疏表示,您只需要存储非零条目,就可以更快地计算范数