
java排查一个线上死循环cpu暴涨的过程分析

问题,打一个页面cpu暴涨,打开一次就涨100%,一会系统就卡的不行了。
排查方法,因为是线上的linux,没有用jvm监控工具rim链接上去。
只好用命令排查:
top cpu排序,一个java进程cpu到500%了,什么鬼.....
查到对应java进程
jps || ps -aux | grep 端口
pid=13455
查看进程中线程使用情况 T排序 查看cpu占用time最高的线程编号
top -Hp 13455
有个线程9877 的时间一直在爆涨
获取线程十六进制地址9877 (十六进制一定要小写)
printf "%x\n" 9877
执行 jstack 13455|grep -10 2695(线程十六进制号)
如果想查看完整信息,可导出文本,查找
jstack -l 9839 > jstack.log-9893
"qtp750044075-25" #25 prio=5 os_prio=0 tid=0x00007f83354e5000 nid=0x2695 runnable [0x00007f830e5d8000] java.lang.Thread.State: RUNNABLE at java.text.DateFormatSymbols.<init>(DateFormatSymbols.java:145) at sun.util.locale.provider.DateFormatSymbolsProviderImpl.getInstance(DateFormatSymbolsProviderImpl.java:85) at java.text.DateFormatSymbols.getProviderInstance(DateFormatSymbols.java:364) at java.text.DateFormatSymbols.getInstance(DateFormatSymbols.java:340) at java.util.Calendar.getDisplayName(Calendar.java:2110) at java.text.SimpleDateFormat.subFormat(SimpleDateFormat.java:1125) at java.text.SimpleDateFormat.format(SimpleDateFormat.java:966) at java.text.SimpleDateFormat.format(SimpleDateFormat.java:936) at java.text.DateFormat.format(DateFormat.java:345) at com.huiwan.gdata.modules.gdata.util.TimeUtil.getDay(TimeUtil.java:383) at com.huiwan.gdata.modules.gdata.publ.retain.service.impl.Retain3ServiceImpl.act(Retain3ServiceImpl.java:119) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:317) .......略 Locked ownable synchronizers: - None
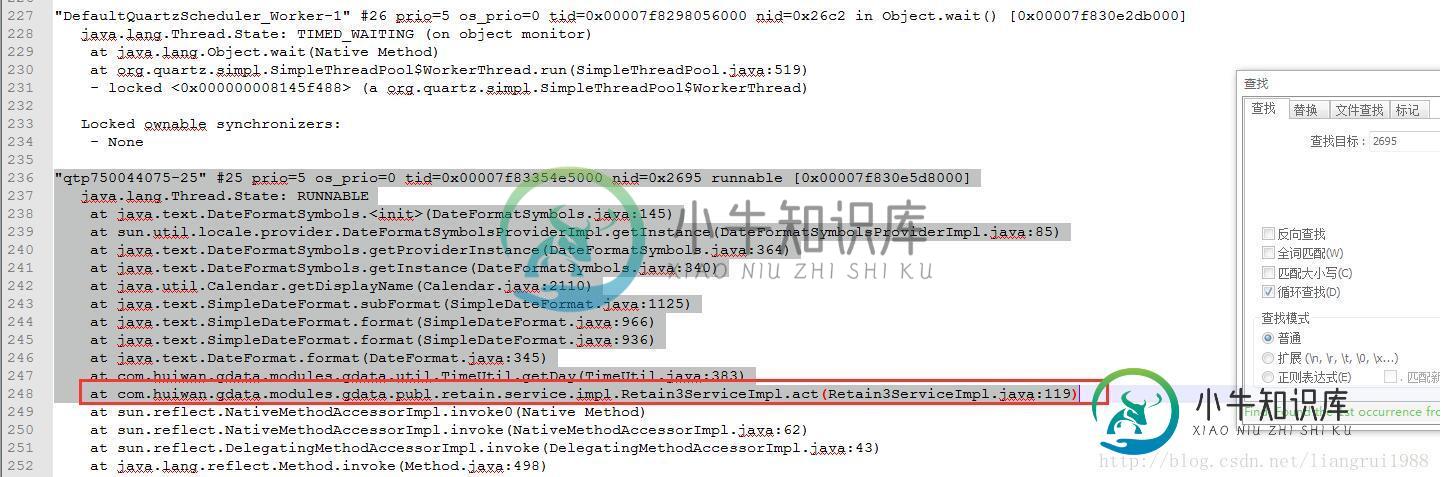
定住到
Retain3ServiceImpl.java:119
这行,马的,有人写了个while循环,用字符串时间比较,之前表是date类型,后改为datetime类型,多了00:00:00永远也没一样的时间,一直在那while.....还搞了个json对象默认加0......
改了这里的代码,就好了,cpu就没上去了.
补充知识:记一次线上Java程序导致服务器CPU占用率过高的问题排除过程
1、故障现象
客服同事反馈平台系统运行缓慢,网页卡顿严重,多次重启系统后问题依然存在,使用top命令查看服务器情况,发现CPU占用率过高。
2、CPU占用过高问题定位
2.1、定位问题进程
使用top命令查看资源占用情况,发现pid为14063的进程占用了大量的CPU资源,CPU占用率高达776.1%,内存占用率也达到了29.8%
[ylp@ylp-web-01 ~]$ top top - 14:51:10 up 233 days, 11:40, 7 users, load average: 6.85, 5.62, 3.97 Tasks: 192 total, 2 running, 190 sleeping, 0 stopped, 0 zombie %Cpu(s): 97.3 us, 0.3 sy, 0.0 ni, 2.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 16268652 total, 5114392 free, 6907028 used, 4247232 buff/cache KiB Swap: 4063228 total, 3989708 free, 73520 used. 8751512 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 14063 ylp 20 0 9260488 4.627g 11976 S 776.1 29.8 117:41.66 java
2.2、定位问题线程
使用ps -mp pid -o THREAD,tid,time命令查看该进程的线程情况,发现该进程的多个线程占用率很高
[ylp@ylp-web-01 ~]$ ps -mp 14063 -o THREAD,tid,time USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME ylp 361 - - - - - - 02:05:58 ylp 0.0 19 - futex_ - - 14063 00:00:00 ylp 0.0 19 - poll_s - - 14064 00:00:00 ylp 44.5 19 - - - - 14065 00:15:30 ylp 44.5 19 - - - - 14066 00:15:30 ylp 44.4 19 - - - - 14067 00:15:29 ylp 44.5 19 - - - - 14068 00:15:30 ylp 44.5 19 - - - - 14069 00:15:30 ylp 44.5 19 - - - - 14070 00:15:30 ylp 44.5 19 - - - - 14071 00:15:30 ylp 44.6 19 - - - - 14072 00:15:32 ylp 2.2 19 - futex_ - - 14073 00:00:46 ylp 0.0 19 - futex_ - - 14074 00:00:00 ylp 0.0 19 - futex_ - - 14075 00:00:00 ylp 0.0 19 - futex_ - - 14076 00:00:00 ylp 0.7 19 - futex_ - - 14077 00:00:15
从输出信息可以看出,14065~14072之间的线程CPU占用率都很高
2.3、查看问题线程堆栈
挑选TID为14065的线程,查看该线程的堆栈情况,先将线程id转为16进制,使用printf "%x\n" tid命令进行转换
[ylp@ylp-web-01 ~]$ printf "%x\n" 14065
36f1
再使用jstack命令打印线程堆栈信息,命令格式:jstack pid |grep tid -A 30
[ylp@ylp-web-01 ~]$ jstack 14063 |grep 36f1 -A 30 "GC task thread#0 (ParallelGC)" prio=10 tid=0x00007fa35001e800 nid=0x36f1 runnable "GC task thread#1 (ParallelGC)" prio=10 tid=0x00007fa350020800 nid=0x36f2 runnable "GC task thread#2 (ParallelGC)" prio=10 tid=0x00007fa350022800 nid=0x36f3 runnable "GC task thread#3 (ParallelGC)" prio=10 tid=0x00007fa350024000 nid=0x36f4 runnable "GC task thread#4 (ParallelGC)" prio=10 tid=0x00007fa350026000 nid=0x36f5 runnable "GC task thread#5 (ParallelGC)" prio=10 tid=0x00007fa350028000 nid=0x36f6 runnable "GC task thread#6 (ParallelGC)" prio=10 tid=0x00007fa350029800 nid=0x36f7 runnable "GC task thread#7 (ParallelGC)" prio=10 tid=0x00007fa35002b800 nid=0x36f8 runnable "VM Periodic Task Thread" prio=10 tid=0x00007fa3500a8800 nid=0x3700 waiting on condition JNI global references: 392
从输出信息可以看出,此线程是JVM的gc线程。此时可以基本确定是内存不足或内存泄露导致gc线程持续运行,导致CPU占用过高。
所以接下来我们要找的内存方面的问题
3、内存问题定位
3.1、使用jstat -gcutil命令查看进程的内存情况
[ylp@ylp-web-01 ~]$ jstat -gcutil 14063 2000 10 S0 S1 E O P YGC YGCT FGC FGCT GCT 0.00 0.00 100.00 99.99 26.31 42 21.917 218 1484.830 1506.747 0.00 0.00 100.00 99.99 26.31 42 21.917 218 1484.830 1506.747 0.00 0.00 100.00 99.99 26.31 42 21.917 219 1496.567 1518.484 0.00 0.00 100.00 99.99 26.31 42 21.917 219 1496.567 1518.484 0.00 0.00 100.00 99.99 26.31 42 21.917 219 1496.567 1518.484 0.00 0.00 100.00 99.99 26.31 42 21.917 219 1496.567 1518.484 0.00 0.00 100.00 99.99 26.31 42 21.917 219 1496.567 1518.484 0.00 0.00 100.00 99.99 26.31 42 21.917 220 1505.439 1527.355 0.00 0.00 100.00 99.99 26.31 42 21.917 220 1505.439 1527.355 0.00 0.00 100.00 99.99 26.31 42 21.917 220 1505.439 1527.355
从输出信息可以看出,Eden区内存占用100%,Old区内存占用99.99%,Full GC的次数高达220次,并且频繁Full GC,Full GC的持续时间也特别长,平均每次Full GC耗时6.8秒(1505.439/220)。根据这些信息,基本可以确定是程序代码上出现了问题,可能存在不合理创建对象的地方
3.2、分析堆栈
使用jstack命令查看进程的堆栈情况
[ylp@ylp-web-01 ~]$ jstack 14063 >>jstack.out
把jstack.out文件从服务器拿到本地后,用编辑器查找带有项目目录并且线程状态是RUNABLE的相关信息,从图中可以看出ActivityUtil.java类的447行正在使用HashMap.put()方法

3.3、代码定位
打开项目工程,找到ActivityUtil类的477行,代码如下:

找到相关同事了解后,这段代码会从数据库中获取配置,并根据数据库中remain的值进行循环,在循环中会一直对HashMap进行put操作。
查询数据库中的配置,发现remain的数量巨大

至此,问题定位完毕。
以上这篇java排查一个线上死循环cpu暴涨的过程分析就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍一次Mysql死锁排查过程的全纪录,包括了一次Mysql死锁排查过程的全纪录的使用技巧和注意事项,需要的朋友参考一下 前言 之前接触到的数据库死锁,都是批量更新时加锁顺序不一致而导致的死锁,但是上周却遇到了一个很难理解的死锁。借着这个机会又重新学习了一下mysql的死锁知识以及常见的死锁场景。在多方调研以及和同事们的讨论下终于发现了这个死锁问题的成因,收获颇多。虽然是后端程序员,我们
-
本文向大家介绍MySQL redo死锁问题排查及解决过程分析,包括了MySQL redo死锁问题排查及解决过程分析的使用技巧和注意事项,需要的朋友参考一下 问题背景 周一上班,首先向同事了解了一下上周的测试情况,被告知在多实例场景下 MySQL Server hang 住,无法测试下去,原生版本不存在这个问题,而新版本上出现了这个问题,不禁心头一颤,心中不禁感到奇怪,还好现场环境还在,为排查问题提
-
我需要编写一个扩展Thread类的应用程序。我的类在实例化时接受一个整数(即100)<代码>(MyThread myt=新的MyThread(100);) 这个整数将是这个类循环并打印消息的次数。消息应该是“线程正在运行…100”。100将是我传入构造函数的任何数字。如果数字是150,那么输出应该是“线程正在运行…100”。我应该使用main方法来测试这个类。在主线程中,我将启动两个线程,一个线程
-
本文向大家介绍iOS使用 CABasicAnimation 实现简单的跑马灯(无cpu暴涨),包括了iOS使用 CABasicAnimation 实现简单的跑马灯(无cpu暴涨)的使用技巧和注意事项,需要的朋友参考一下 网上找了几个,但都有cup暴涨的情况发生,于是利用CABasicAnimation 简单的实现一个跑马灯,实现简单,可自己定制 以上就是本文的全部内容,希望对大家的学习有所帮助,也
-
问题内容: 我正在使用从队列中连续读取的线程。 就像是: 停止此线程的最佳方法是什么? 我看到两个选择: 1-由于已弃用,因此我可以实现使用原子检查条件变量的方法。 2-将死亡事件对象或类似的对象发送到队列。当线程获取死亡事件时,它退出。 我更喜欢第一种方法,但是,我不知道何时调用该方法,因为可能有某种方法进入队列,并且停止信号可能首先到达(这是不希望的)。 有什么建议? 问题答案: 该(或因为它
-
本文向大家介绍查询Sqlserver数据库死锁的一个存储过程分享,包括了查询Sqlserver数据库死锁的一个存储过程分享的使用技巧和注意事项,需要的朋友参考一下 使用sqlserver作为数据库的应用系统,都避免不了有时候会产生死锁, 死锁出现以后,维护人员或者开发人员大多只会通过sp_who来查找死锁的进程,然后用sp_kill杀掉。利用sp_who_lock这个存储过程,可以很方便的知道哪个