
Python字典的概念及常见应用实例详解

本文实例讲述了Python字典的概念及常见应用。分享给大家供大家参考,具体如下:
字典的介绍
- 字典的概念
- 字典的创建
- 1. 我们可以通过{}、dict()来创建字典对象。
- 2. 通过 zip()创建字典对象
- 3. 通过 fromkeys 创建值为空的字典
- 字典元素的访问
- 1. 通过 [键] 获得“值”。若键不存在,则抛出异常。
- 2. 通过 get()方法获得“值”。推荐使用。优点是:指定键不存在,返回 None;也可以设
- 3. 列出所有的键值对
- 4. 列出所有的键,列出所有的值
- 5. len() 键值对的个数
- 6. 检测一个“键”是否在字典中
- 字典元素添加、修改、删除
- 1. 给字典新增“键值对”
- 2. 使用 update()
- 3. 字典中元素的删除
- 4. popitem()
- 序列解包
- 序列解包可以用于元组、列表、字典。
- 序列解包用于字典时
- 表格数据使用字典和列表存储,并实现访问
- 字典核心底层原理(重要)
- 将一个键值对放进字典的底层过程
- 扩容
- 根据键查找“键值对”的底层过程
- 用法总结:
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:“键
对象”和“值对象”。可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。
列表中我们通过“下标数字”找到对应的对象。字典中通过“键对象”找到对应的“值
对象”。“键”是任意的不可变数据,比如:整数、浮点数、字符串、元组。但是:列表、
字典、集合这些可变对象,不能作为“键”。并且“键”不可重复。
“值”可以是任意的数据,并且可重复。
一个典型的字典的定义方式:
a = {'name':'gaoqi','age':18,'job':'programmer'}
字典的创建
1. 我们可以通过{}、dict()来创建字典对象。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> b = dict(name='gaoqi',age=18,job='programmer')
>>> a = dict([("name","gaoqi"),("age",18)])
>>> c = {} #空的字典对象
>>> d = dict() #空的字典对象
2. 通过 zip()创建字典对象
>>> k = ['name','age','job']
>>> v = ['gaoqi',18,'techer']
>>> d = dict(zip(k,v))
>>> d
{'name': 'gaoqi', 'age': 18, 'job': 'techer'}
3. 通过 fromkeys 创建值为空的字典
>>> a = dict.fromkeys(['name','age','job'])
>>> a
{'name': None, 'age': None, 'job': None}
字典元素的访问
为了测试各种访问方法,我们这里设定一个字典对象:
a = {'name':'gaoqi','age':18,'job':'programmer'}
1. 通过 [键] 获得“值”。若键不存在,则抛出异常。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a['name']
'gaoqi'
>>> a['age']
18
>>> a['sex']
Traceback (most recent call last):
File "<pyshell#374>", line 1, in <module>
a['sex']
KeyError: 'sex'
2. 通过 get()方法获得“值”。推荐使用。优点是:指定键不存在,返回 None;也可以设
定指定键不存在时默认返回的对象。推荐使用 get()获取“值对象”。
>>> a.get('name')
'gaoqi'
>>> a.get('sex')
>>> a.get('sex','一个男人')
'一个男人'
3. 列出所有的键值对
>>> a.items()
dict_items([('name', 'gaoqi'), ('age', 18), ('job', 'programmer')])
4. 列出所有的键,列出所有的值
>>> a.keys() dict_keys(['name', 'age', 'job']) >>> a.values() dict_values(['gaoqi', 18, 'programmer'])
5. len() 键值对的个数
6. 检测一个“键”是否在字典中
>>> a = {"name":"gaoqi","age":18}
>>> "name" in a
True
字典元素添加、修改、删除
1. 给字典新增“键值对”
如果“键”已经存在,则覆盖旧的键值对;如果“键”不存在,则新增“键值对”。
>>>a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a['address']='西三旗 1 号院'
>>> a['age']=16
>>> a
{'name': 'gaoqi', 'age': 16, 'job': 'programmer', 'address': '西三旗 1 号院'}
2. 使用 update()
将新字典中所有键值对全部添加到旧字典对象上。如果 key 有重复,则直接覆盖。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> b = {'name':'gaoxixi','money':1000,'sex':'男的'}
>>> a.update(b)
>>> a
{'name': 'gaoxixi', 'age': 18, 'job': 'programmer', 'money': 1000, 'sex': '男的'}
3. 字典中元素的删除
可以使用 del()方法;或者 clear()删除所有键值对;pop()删除指定键值对,并返回对应的“值对象”;
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> del(a['name'])
>>> a
{'age': 18, 'job': 'programmer'}
>>> b = a.pop('age')
>>> b
18
4. popitem()
随机删除和返回该键值对。字典是“无序可变序列”,因此没有第一个元
素、最后一个元素的概念;popitem 弹出随机的项,因为字典并没有"最后的元素"或者其
他有关顺序的概念。若想一个接一个地移除并处理项,这个方法就非常有效(因为不用首先
获取键的列表)。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> a.popitem()
('job', 'programmer')
>>> a
{'name': 'gaoqi', 'age': 18}
>>> a.popitem()
('age', 18)
>>> a
{'name': 'gaoqi'}
序列解包
序列解包可以用于元组、列表、字典。
序列解包可以让我们方便的对多个变量赋值。
>>> x,y,z=(20,30,10) >>> x 20 >>> y 30 >>> z 10 >>> (a,b,c)=(9,8,10) >>> a 9 >>> [a,b,c]=[10,20,30] >>> a 10 >>> b 20
序列解包用于字典时
默认是对“键”进行操作; 如果需要对键值对操作,则需要使用items();如果需要对“值”进行操作,则需要使用 values();
>>> s = {'name':'gaoqi','age':18,'job':'teacher'}
>>> name,age,job=s #默认对键进行操作
>>> name
'name'
>>> name,age,job=s.items() #对键值对进行操作
>>> name
('name', 'gaoqi')
>>> name,age,job=s.values() #对值进行操作
>>> name
'gaoqi'
表格数据使用字典和列表存储,并实现访问
| 姓名 | 年龄 | 薪资 | 城市 |
|---|---|---|---|
| 高小一 | 18 | 30000 | 北京 |
| 高小二 | 19 | 20000 | 上海 |
| 高小五 | 20 | 10000 | 深圳 |
源代码(mypy_09.py):
r1 = {"name":"高小一","age":18,"salary":30000,"city":"北京"}
r2 = {"name":"高小二","age":19,"salary":20000,"city":"上海"}
r3 = {"name":"高小五","age":20,"salary":10000,"city":"深圳"}
tb = [r1,r2,r3]
#获得第二行的人的薪资
print(tb[1].get("salary"))
#打印表中所有的的薪资
for i in range(len(tb)): # i -->0,1,2
print(tb[i].get("salary"))
#打印表的所有数据
for i in range(len(tb)):
print(tb[i].get("name"),tb[i].get("age"),tb[i].get("salary"),tb[i].get("city"))
字典核心底层原理(重要)
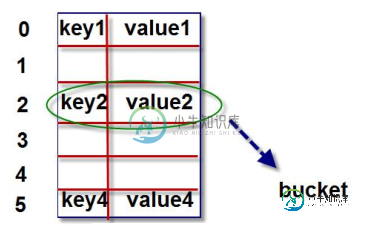
字典对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组),数组的
每个单元叫做 bucket。每个 bucket 有两部分:一个是键对象的引用,一个是值对象的引
用。
由于,所有 bucket 结构和大小一致,我们可以通过偏移量来读取指定 bucket。
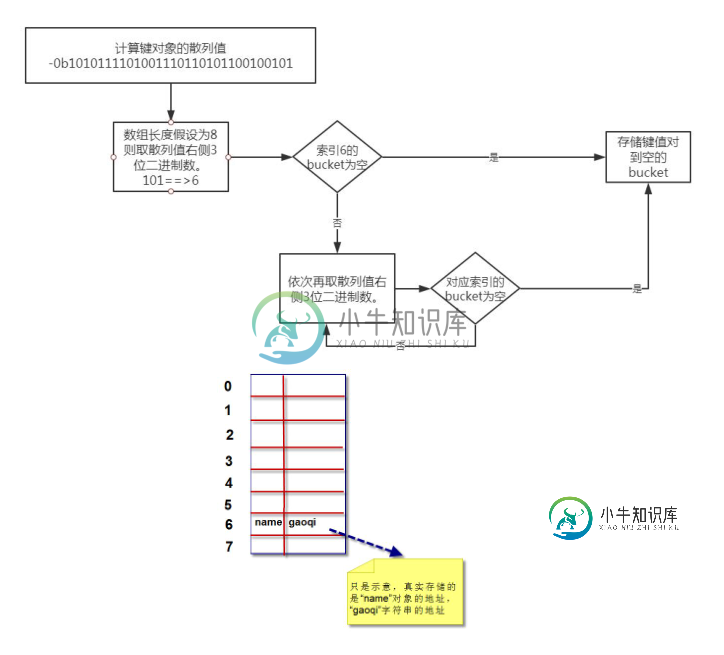
将一个键值对放进字典的底层过程
>>> a = {}
>>>
a["name"]="gaoqi"
假设字典 a 对象创建完后,数组长度为 8:
我们要把”name”=”gaoqi”这个键值对放到字典对象 a 中,首先第一步需要计算
键”name”的散列值。Python 中可以通过 hash()来计算。
>>> bin(hash("name"))
'-0b1010111101001110110101100100101'
由于数组长度为 8,我们可以拿计算出的散列值的最右边 3 位数字作为偏移量,即
“101”,十进制是数字 5。我们查看偏移量 5,对应的 bucket 是否为空。如果为空,则
将键值对放进去。如果不为空,则依次取右边 3 位作为偏移量,即“100”,十进制是数字
4。再查看偏移量为 4 的 bucket 是否为空。直到找到为空的 bucket 将键值对放进去。流
程图如下:
扩容
python 会根据散列表的拥挤程度扩容。“扩容”指的是:创造更大的数组,将原有内容
拷贝到新数组中。
接近 2/3 时,数组就会扩容。
根据键查找“键值对”的底层过程
我们明白了,一个键值对是如何存储到数组中的,根据键对象取到值对象,理解起来就
简单了。
>>> a.get("name")
'gaoqi'
当我们调用 a.get(“name”),就是根据键“name”查找到“键值对”,从而找到值
对象“gaoqi”。
第一步,我们仍然要计算“name”对象的散列值:
>>> bin(hash("name"))
'-0b1010111101001110110101100100101'
和存储的底层流程算法一致,也是依次取散列值的不同位置的数字。 假设数组长度为
8,我们可以拿计算出的散列值的最右边 3 位数字作为偏移量,即“101”,十进制是数字
5。我们查看偏移量 5,对应的 bucket 是否为空。如果为空,则返回 None。如果不为空,
则将这个 bucket 的键对象计算对应散列值,和我们的散列值进行比较,如果相等。则将对
应“值对象”返回。如果不相等,则再依次取其他几位数字,重新计算偏移量。依次取完后,
仍然没有找到。则返回 None。流程图如下:

用法总结:
- 键必须可散列
(1) 数字、字符串、元组,都是可散列的。
(2) 自定义对象需要支持下面三点:- 支持 hash()函数
- 支持通过__eq__()方法检测相等性。
- 若 a==b 为真,则 hash(a)==hash(b)也为真。
- 字典在内存中开销巨大,典型的空间换时间。
- 键查询速度很快
- 往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字典的同时进行字典的修改。
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python字典操作技巧汇总》、《Python列表(list)操作技巧总结》、《Python函数使用技巧总结》、《Python数据结构与算法教程》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
-
什么是仓库 在 Git 的概念中,仓库,就是你存在.git目录的那个文件夹内的所有文件,包括隐藏的文件,Git程序会再当前目录以及上级目录查找是否存在.git文件,如果存在,则会将.git目录存在的文件夹开始下的所有文件当成你需要管理的文件,所以,我们如果想将某个文件夹当做一个Git仓库,你可以在那个文件夹下通过终端(Window为Cmd或者PoewrShell或者Bash)来执行 git ini
-
本文向大家介绍python字典操作实例详解,包括了python字典操作实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python字典操作实例的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
本文向大家介绍详解Python中映射类型(字典)操作符的概念和使用,包括了详解Python中映射类型(字典)操作符的概念和使用的使用技巧和注意事项,需要的朋友参考一下 映射类型操作符 (1)标准类型操作符 字典可以和所有的标准类型操作符一起工作,但却不支持像拼接(concatenation)和重复(repetition)这样的操作。这些操作对序列有意义,可对映射类型行不通。
-
概括来说,从 Saga 内触发异步操作(Side Effect)总是由 yield 一些声明式的 Effect 来完成的 (你也可以直接 yield Promise,但是这会让测试变得困难,就像我们在第一节中看到的一样)。 一个 Saga 所做的实际上是组合那些所有的 Effect,共同实现所需的控制流。 最简单的是只需把 yield 一个接一个地放置,就可对 yield 过的 Effect 进行
-
本文向大家介绍Docker 镜像、容器、仓库的概念及应用详解,包括了Docker 镜像、容器、仓库的概念及应用详解的使用技巧和注意事项,需要的朋友参考一下 Docker 镜像、容器、仓库的概念 Docker镜像 Docker镜像(Image)类似于虚拟机的镜像,可以将他理解为一个面向Docker引擎的只读模板,包含了文件系统。 例如:一个镜像可以完全包含了Ubuntu操作系统环境,可以把它称作一个
-
本文向大家介绍Python字典简介以及用法详解,包括了Python字典简介以及用法详解的使用技巧和注意事项,需要的朋友参考一下 老规矩以下方法环境2.7.x,请3.x以上版本的朋友记得格式print(输出内容放入括号内) 字典的基本组成以及用法 首先来说说字典是由key键与value值一一对应来组成字典的基本结构 key键不能由list列表,dict字典等多元素命名, key是唯一属性又可以称一对