《上海爱数》专题
-
 海康威视热线技术支持工程师
海康威视热线技术支持工程师2022.11.1 自我介绍(面试必问问题!!!) 1.职业规划 2.我看你是山西人,那你为什么想来武汉? 3.有无亲戚朋友在武汉? 4.我看你一志愿投的数据类,都在杭州,那你觉得杭州和武汉哪个好? #海康威视面试#
-
 三七互娱(9.7 海外游戏运营笔试)
三七互娱(9.7 海外游戏运营笔试)选择题10题 单选 1、以下那种游戏类型与其他不同,剑与远征,什么之光?炉石传说,还有个忘了,除了炉石都没玩过ORZ 2、斗罗大陆魂师觉醒里面没有的功能是? 家园养成?,魂环觉醒,战力冲榜,卡牌收集 3、暴雪去年收入最高的游戏? 暗黑破坏神、糖果世界、魔兽、炉石 4、2022上半年海外游戏发行收入最高的公司? 4399、三七、腾讯、网易 5、游戏市场规模排序正确的是? 四个国家,美国,日本,韩国,
-
 海康威视嵌入式软开实习一面
海康威视嵌入式软开实习一面6/1官网投递简历,做了测试 7/6一面,牛客网面试系统,两位面试官,20min 自我介绍 项目介绍 基础知识 调试手段有哪些? uboot启动流程? 为什么启动时关闭icache和dcache? 有接触过USB驱动吗? 用过Makefile吗? gcc的过程,几个阶段,宏定义在那个阶段? uboot的Makefile。 const int * p和const * int p 区别? 堆和栈的区别
-
 23届补录-海康产品二面面经(0621)
23届补录-海康产品二面面经(0621)春招被捞的,一面是6月14号左右,21号9点多早上起来帮导师在写项目的时候,接到的二面电话(就是hr面,如图),因为明天是端午节,问十点多能不能面试,面试内容如下: Q1:你的实习经历这么丰富,请简单介绍下你的校园经历; A1:我就介绍了自己当体育部副部长时的经历,主要是强调自己的领导力、组织协调能力。 Q2:详细介绍以下对你提升最大的实习; A2:主要自己在美团的实习,强调这段实习对自己产品方法
-
 海康嵌入式软件开发实习一面
海康嵌入式软件开发实习一面1.IIC介绍 2.使用通信协议遇到的问题 3.FreeRTOS操作系统移植碰到的问题 4.CPU和MCU的区别 5.8086架构和ARM CM3内核架构 6.MCU的全称 7.蓝牙模块和串口整体通信过程 8.为什么选择海康 9.和前面的硕士相比,你的优势在哪里 10.CPU的组成 11.软件SPI和硬件SPI的区别 12.项目里PID设计和调参过程 简历上学习课程那写了微机原理,然后就被面试官一
-
 海康威视技术支持二面(23春招)
海康威视技术支持二面(23春招)杭州机器人部门 总时长近40分钟,体验非常好,给hr小姐姐点个赞! 问的不难,提问内容跟牛客上其他同学类似,围绕简历出发,跟宝洁八大问类似,但没有那么难,非常实际。 1.春招末期,你有offer情况下,为什么还在找工作? 2.答辩情况如何?毕业没问题吧? 3.目前offer什么情况?春招找了那些公司? 4.是否了解岗位?将来职业规划如何? 5.咱公司对应届生的薪资跟你目前签约的相似,你如何选择?
-
 海康威视 5.30 安全开发实习面试
海康威视 5.30 安全开发实习面试自我介绍 问小论文写的咋样了,达到毕业要求没。 为什么去亚信实习,亚信在哪。 项目中遇到什么困难,最后怎么解决的。 了解计算机网络吗,https协议怎么保证安全的,保证的是哪部分安全。 了解操作系统吗,写过linux内核吗,进程间通讯的方式有哪些。 说一下信号量和自旋锁的区别 在学校里或者公司中最有成就感的事。 你觉得你做安全开发,知识还有哪些欠缺。(我简历上没写安全相关的东西,我确实也不懂安全,
-
怎么在海量数据中找出重复次数最多的一个?
本文向大家介绍怎么在海量数据中找出重复次数最多的一个?相关面试题,主要包含被问及怎么在海量数据中找出重复次数最多的一个?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
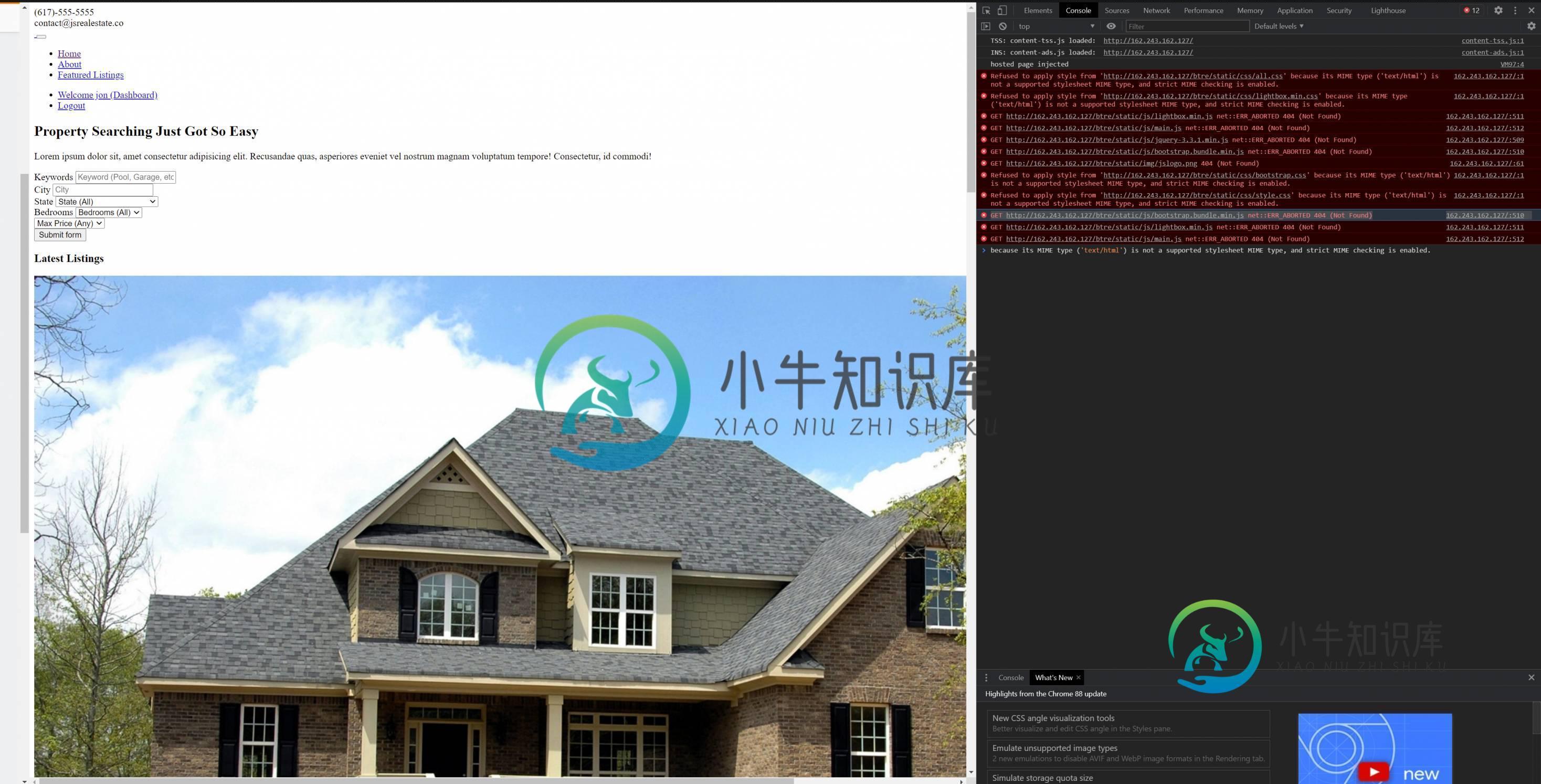 Nginx数字海洋部署中加载静态文件时出现问题
Nginx数字海洋部署中加载静态文件时出现问题Django初学者在这里... 在最终部署到数字海洋液滴时加载静态文件时遇到问题 我用的是Nginx和Gunicorn。 我遵循了Traversy Media的教程,但我无法通过我的Digital Ocean ipv4在浏览器中显示静态文件。检查后,它会抛出这些多个错误。 这是我的nginx设置 这是我的枪角设置 我曾多次尝试在终端中运行collectstatic,但它不起任何作用。。表示它有“0
-
Spring启动(数据)海森布格与检测数据库驱动程序
在开发Spring BootRESTendpoint时,我的应用程序会遇到奇怪的(heisenbug)行为。我为每个endpoint项目制作了单独的模块,这也可能与此相关。在细节上,它可以运行一次,但在重新运行后会失败,可能运行一个endpoint,但不会运行另一个,反之亦然。 描述: 无法确定数据库类型 NONE 的嵌入式数据库驱动程序类 行动: 如果你想要一个嵌入式数据库,请在类路径上放置一个
-
 海尔智家 数据分析岗 秋招提前批 一面面经 06.14
海尔智家 数据分析岗 秋招提前批 一面面经 06.14首先说一下面试感受,一共三个面试官,全程20多分钟,问问题主要从业务的层面上 问题汇总: 1、自我介绍 2、说一下比赛的项目 3、BERT的具体原理? 4、说一下chinese-wwm-bert模型的改进? 5、说一下roberta为什么去除掉NSP任务? 6、比赛赛题的业务场景?一直问为什么这么做,能用来做什么?(我有点杠。。。) 7、现在有文本、图片、数值的数据你来怎么处理? 反问:
-
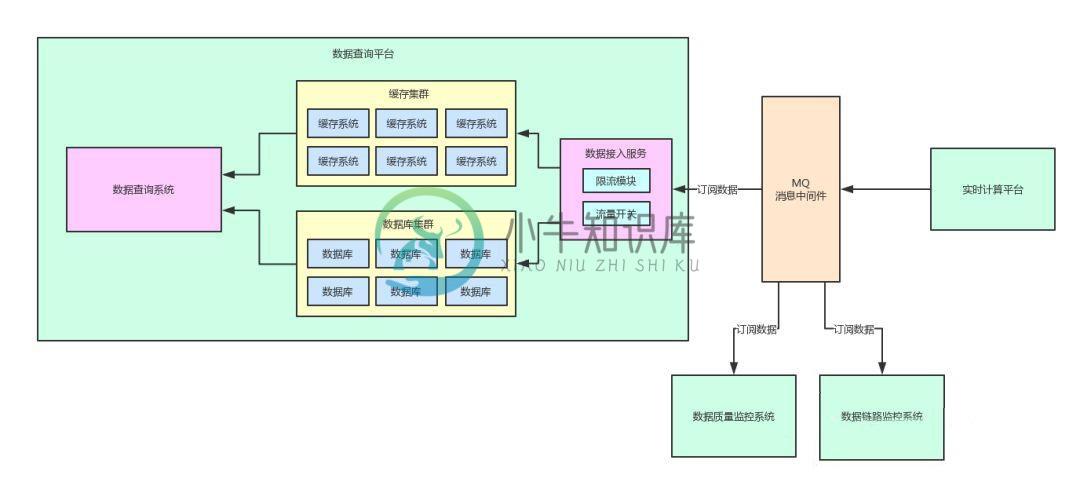 高并发+海量数据情况下如何实现系统解耦?【下】
高并发+海量数据情况下如何实现系统解耦?【下】主要内容:一、前情提示,二、基于消息中间件的队列消费模型,三、基于消息中间件的“Pub/Sub”模型,四、RabbitMQ中的exchange到底是个什么东西?,五、默认的exchange,六、将消息投递到fanout exchange,七、绑定自己的队列到exchange上去消费,八、整体架构图一、前情提示 上一篇文章《高并发+海量数据下如何实现系统解耦?【中】》分析了一下如何利用消息中间件对系统进行解耦处理。 同时,我们也提到了使用消息中间件还有利于一份数据被多个系统同时订阅,供多个系统来使
-
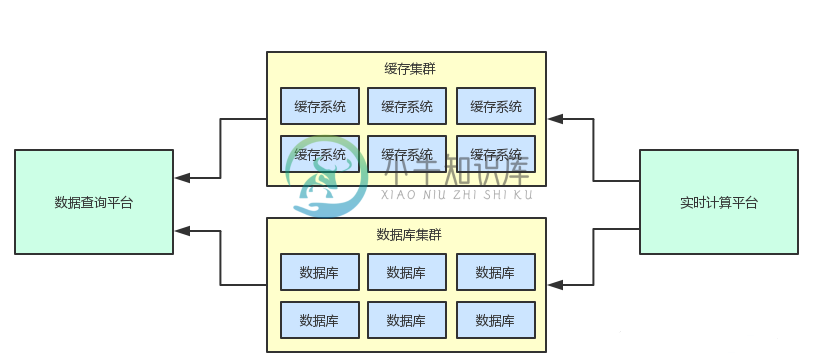 高并发+海量数据情况下如何实现系统解耦?【中】
高并发+海量数据情况下如何实现系统解耦?【中】主要内容:一、前情提示,二、清晰的划分系统边界,三、引入消息中间件解耦,四、利用消息中间件削峰填谷,五、手动流量开关配合数据库运维操作,六、支持多系统同时订阅数据,七、系统解耦后的感受一、前情提示 上一篇文章《高并发+海量数据下如何实现系统解耦?【上】》,给大家初步讲述了一套大规模复杂系统中,两个核心子系统之间一旦耦合,会发生哪些令人崩溃的场景。如果还没看上篇文章的,建议先看一下。 这篇文章,咱们就给大家来说一说通过MQ消息中间件的使用,如何重构系统之间的耦合,让系统具备高度的可扩展性。 首先来
-
在爱奥尼亚项目中升级到电容器3后,Android Studio build失败
我在Ionic项目中升级到电容器3。到目前为止,我所做的是:按照电容器页面上的升级说明进行操作。https://capacitorjs.com/docs/updating/3-0 Ionic-Build成功了,但是,当我尝试在Android Studio(最新版本)中为我的Android设备构建解决方案时,我遇到了以下错误:(抱歉,我现在不允许添加图片) 无法解析配置“:app:debugRunt
-
 如何将analytics中的图表定位为azure portal application insights资源中的最爱
如何将analytics中的图表定位为azure portal application insights资源中的最爱我正在研究Application Insights中的analytics概念,因为当我在analytics中运行查询时,我将以表格格式和图表格式获取数据,但这里我的问题是如何将analytics中的图表定位为azure portal Application Insights资源中的最爱。 这是chart application insights analytics仪表板。 我想将上面的图表固定到a