《上海爱数》专题
-
Python-你是否应该始终偏爱xrange()而不是range()?
问题内容: 为什么或者为什么不? 问题答案: 对于性能而言,尤其是在较大范围内进行迭代时,通常会更好。但是,在某些情况下,你可能更喜欢: 在Python 3,range()做什么用做的,不存在。如果要编写可在Python 2和Python 3上运行的代码,则不能使用。 在某些情况下实际上可以更快-例如。如果多次重复相同的序列。 xrange()每次都必须重新构造整数对象,但是range()将拥有真
-
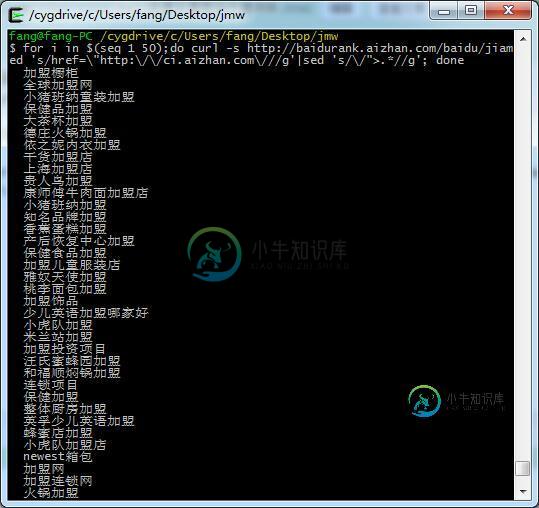 shell脚本实现批量采集爱站关键词库
shell脚本实现批量采集爱站关键词库本文向大家介绍shell脚本实现批量采集爱站关键词库,包括了shell脚本实现批量采集爱站关键词库的使用技巧和注意事项,需要的朋友参考一下 shell批量采集爱站关键词库,心血来潮写着玩的,还不完善,先放出来,后期慢慢更新,功能虽然简单,同类工具也很多现成的,但毕竟是自己写出来的工具,感觉还是很不一样滴! 效果截图:
-
gss名称在java中为爱尔兰fada字符损坏
windows xp将授权标头中的SPNEGO令牌发送到我们的服务器,该服务器了解kerberos协议。服务器应用程序是使用java提供的gss api实现的。 我们的代码从spnego令牌中提取upn名称,并使用LDAP存储对其进行验证。如果upn名称只包含ascii字符(小于127),则一切正常。 但是,如果用户名包含非ascii字符(例如爱尔兰fada),那么java gss api出于某种
-
 用爱普生热敏打印机C#打印长收据
用爱普生热敏打印机C#打印长收据我有一台爱普生热敏打印机,现在我要打印一些足够长的收据,我使用爱普生提供的代码样本。代码如下所示,现在的问题是,当收据超过一定长度(约30cm)时,打印机会停止并剪切收据,如下图所示。我如何打印长收据没有自动剪切。
-
爱普生打印机连接失败状态ERR\U CONN
我有一台爱普生打印机,我使用SDK提供的epos2_printer(示例项目)代码与我的应用程序集成。我复制了相同的代码,但似乎从来没有工作过! 然而,当我将示例项目连接到打印机时,同样的情况也会发生。 mPrinter.add馈线(2); 它总是给我例外ERR\u连接打印机。连接内部连接打印机功能。 我做错了什么? 此代码适用于示例应用程序。附注:我已尝试在连接示例应用程序之前连接此应用程序,以
-
 金山办公面试全流程!爱山信山等山!
金山办公面试全流程!爱山信山等山!还记得约一面时就很坎坷了,当时金山打了几个电话我都阴差阳错地没有接到,还想着错过就错过了吧,后面国庆后又给我打了电话,感动+1。之后便是等待一面,还记得一面前一晚上到2点左右才睡着。金山的面试官都很好,一面安慰我让我不要紧张。在我秋招低谷的时候给我发了二面通知,感动+1;二面面试官给我讲学生进入职场的注意事项,指出我存在的问题,感动+1。二面后一直没有消息,慌得很,还好看到牛客其他bro主动去催,
-
 交互设计实习 面试经验( 北京 ) - 爱奇艺
交互设计实习 面试经验( 北京 ) - 爱奇艺面试形式:电话面试 1对1面试 问题记录: 1、自我介绍 2、作品集讲解,详细介绍每一个。就作品集的作品问 ,设计的创新点是什么 3、交互知识相关问题:如交互规范,为什么这样设计。 4、20分钟的一个小笔试。类似一个小需求,要求画低保真界面 5、自己的优缺点
-
 小药药前端面经(他家名字好可爱啊)
小药药前端面经(他家名字好可爱啊)他家技术栈好老啊,跟我说Vue2还有jQuery。。。。。。。。 写简历上重大减分项好吧,和低代码真是八斤八两 但是感觉知名度还可以,公司规模也相当不错的那种 面试问的也巨简单,20分钟结束战斗,简历一点不问,说让我等二面 北京,价位最高给200/天 总体来说极度不推荐吧,如果是base武汉这个价位其实还不错 但是说实话,我对他们的行业还是觉得挺有前景的 一个医药,一个殡葬,是我觉得现在最蒸蒸日上
-
海王星上的小精灵:如何从“选择”返回的边缘获得“outV”
我有一个有两个顶点的图:“a” “a”和“b”之间有一条边,标记为“Y” 小妖精 == 边缘具有属性“foo” 小妖精 == 我的问题是:为什么下面的陈述返回了优势?我希望有一个顶点。 小妖精 ==
-
Django静态无法访问(数字海洋)[重复]
我在数字海洋水滴上建立了一个Django站点,但是静态文件似乎无法访问。 环顾四周寻找解决方案,我认为问题在于服务器设置(Nginx),但由于这对我来说更为新,我想在弄糟它之前验证一下。 CSS被放置在中,该文件夹不能使用浏览器访问: IPadress/static/css/style。css在css上出现“404未找到”错误 我刚刚找到了Nginx错误日志,其中声明在中查找静态文件,但该日志不存
-
第六章 海量数据处理 - 6.10 数据库
方法介绍 当遇到大数据量的增删改查时,一般把数据装进数据库中,从而利用数据的设计实现方法,对海量数据的增删改查进行处理。
-
第六章 海量数据处理 - 6.4 外排序
方法介绍 所谓外排序,顾名思义,即是在内存外面的排序,因为当要处理的数据量很大,而不能一次装入内存时,此时只能放在读写较慢的外存储器(通常是硬盘)上。 外排序通常采用的是一种“排序-归并”的策略。 在排序阶段,先读入能放在内存中的数据量,将其排序输出到一个临时文件,依此进行,将待排序数据组织为多个有序的临时文件; 尔后在归并阶段将这些临时文件组合为一个大的有序文件,也即排序结果。 假定现在有20个
-
第六章 海量数据处理 - 6.3 simhash算法
方法介绍 背景 如果某一天,面试官问你如何设计一个比较两篇文章相似度的算法?可能你会回答几个比较传统点的思路: 一种方案是先将两篇文章分别进行分词,得到一系列特征向量,然后计算特征向量之间的距离(可以计算它们之间的欧氏距离、海明距离或者夹角余弦等等),从而通过距离的大小来判断两篇文章的相似度。 另外一种方案是传统hash,我们考虑为每一个web文档通过hash的方式生成一个指纹(finger pr
-
多线程海量文件读取
问题内容: 我仍在全神贯注地了解Java中并发的工作方式。我知道(如果您订购的是OO Java 5并发模型)则分别实现a 或with 或or 方法,并且它应该使您尽可能多地并行实现该方法。 但是我仍然不了解Java并发编程的内在知识: 一个是怎样的方法分配给执行工作的同时适量的? 作为一个具体的例子,如果我有一个I / O绑定的方法,该方法将从本地系统上的文件中读取Herman Melville的
-
 海信java后端开发一面
海信java后端开发一面(非信动力) 整体流程是:投简历-测评and英语口语测评-笔试-电话面试 英语口语三道题:1.跟读 2.英语题目,可以听两遍。我抽的是遇到的挫折以及怎么解决的(应该是,英语渣,听了个大概) 3.图片题。图里是一群人在开会。问题是会议进行到什么程度了,根据图片你想起了生活中的什么事。 整体词穷,支支吾吾回答完了,之后收到笔试通知,三天内完成。 笔试主要是10个选择两个编程,一个小时的考试时间