《上海爱数》专题
-
 海康技术支持二面
海康技术支持二面压力了我40分钟,😭一直让我考虑开发(有这水平我去技术支持?) 不知道还有没有机会
-
 华为海思5.16技术面
华为海思5.16技术面#软件开发2024笔面经# 1.复盘机试 2.介绍学校里的项目 3.谈谈你对编程语言的了解 4.比如说C语言的函数指针,知道是怎么做的吗 5.介绍你做的最好的一个项目 手撕一道简单的全排列 秒过,等下一轮了
-
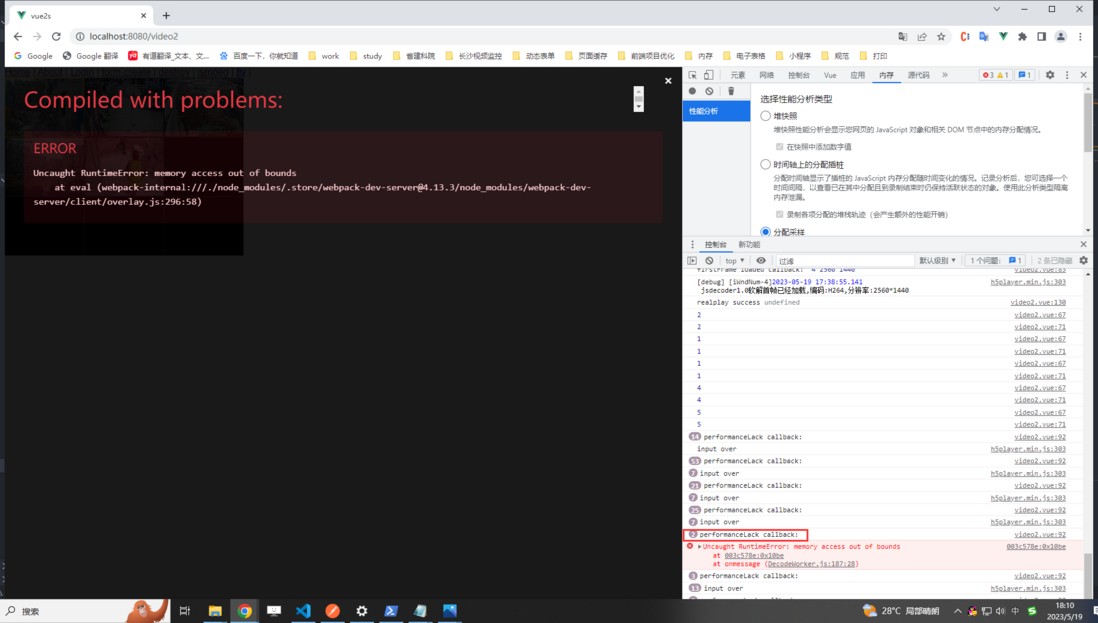 java - 海康h5player内存泄露?
java - 海康h5player内存泄露?问题 在使用海康h5player播放视频的时候,出现了内存泄露 版本2.12 链接 内存泄露监听,但是不知道怎么处理 期望 可以一直播放视频,但是不知道怎么处理监听的内存泄露(重新刷新也不行,内存依旧,不是很0开始) 代码
-
 海康一面 图像算法
海康一面 图像算法不管结果给xdm个参考吧,图像算法岗 一共半个小时左右,很简短的自我介绍,之后就是介绍项目我一直在说得说了有二十分钟,可能会问一些项目的细节不过问的不深,无手撕,最后还有个类似智力题之类的就结束了,面试官挺好的
-
 海康图像实习一面
海康图像实习一面开局自我介绍 项目论文介绍,面试官打断询问里面评价指标以及遇到的困难,核心难点在哪里 反问 共计半小时整,结束~ 慌张.jpg😂 #海康威视信息集散地#
-
 海康威视c++一面挂
海康威视c++一面挂说是c++,主要方向是医疗的,作为一个双非,简历能过是因为之前在医疗公司干过。不过我当时主要是负责后处理部分的。 面试的时候,侧重点则是我平常不注重的。比如我是对医学影像进行处理,他们主要问那种图像格式的生成,通信原理。 至于编程相关的,一些八股文,问了模板类,智能指针相关的。 整体上还是我太菜了。很多太底层的原理回答的不好。
-
PKIX路径构建无法在数字海洋上找到请求目标的有效认证路径
如有任何帮助,不胜感激
-
缺少Django Grappelli样式[数字海洋设置]
我部署了一个安装了Django admin的数字海洋水滴。当我安装Django Grappelli并尝试加载管理员时,Django Grappelli中的css和js文件丢失,导致页面显示纯HTML。当我检查元素时,所有必需的图形文件都丢失了,代码为404。 有什么想法吗?? 以下是我的ettings.py供参考: 这是我的NGINX配置: NGINX错误日志:
-
计算海量数据的中位数[重复]
我有大量的数据( 另外,是否是合适的数据结构?或者另一种数据结构会提供更好的复杂性 注意:我不能使用,因为如果使用,也可能存在重复项。查找中值将增加复杂性,因为我将从开始到中间循环以获取其值。
-
从 4D NetCDF 文件中提取海底数据
我有海洋pH、o2等的全球4D NetCDF文件。每个文件有1个变量和4个维度(时间、经度、纬度和深度)。我希望从不包含NA的每个单元格的最底部深度提取数据。我尝试使用带有负超实验室的NCO的nks: 但是,这只为我提供了最深的箱(即-5700米深度箱)的数据,输出了海洋中所有较浅区域的NaN。有没有办法以类似的方式提取数据,但指定我想要每个单元格最深的非 NaN 值? 我能够使用 R、CDO 或
-
'EntryPoint'对象没有属性'get'-数字海洋
我已经向Digital ocean表示歉意,在登台(Heroku服务器)上,应用程序运行良好,但Digitale ocean失败了,错误如下,可能是什么问题:
-
 渤海银行秋招数据分析师(凉)
渤海银行秋招数据分析师(凉)1.看板搭建项目 2.iv和woe原理 3.来天津原因 别的不记得了
-
第六章 海量数据处理 - 6.9 Trie树
方法介绍 1.1、什么是Trie树 Trie树,即字典树,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。 Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。 它有3个基本性质: 根节点不包含字符,除根节点外每
-
第六章 海量数据处理 - 6.8 Bloom filter
方法介绍 一、什么是Bloom Filter Bloom Filter,被译作称布隆过滤器,是一种空间效率很高的随机数据结构,Bloom filter可以看做是对bit-map的扩展,它的原理是: 当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位阵列(Bit array)中的K个点,把它们置为1**。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了: 如果这些
-
 面经|海亮集团-数据开发实习
面经|海亮集团-数据开发实习1.实习经历拷打 2.项目拷打 3.数仓分层 4.sql:连续登录 已OC