《北京仁科互动》专题
-
 网易互娱8.27游戏研发
网易互娱8.27游戏研发#网易互娱笔试# 这次笔试不难,我的AK代码如下,大佬勿喷 第一题 找规律,不多BB 第二题 矩形相交 第三题 二维数组哈希 #网易互娱##网易笔试#
-
 20220827网易互娱_后端笔试
20220827网易互娱_后端笔试第一题:完美对称图形 注意到奇数这个条件,所以图形必须是中间一个中心图案,然后向外层一圈一圈扩展 100% 第二题: 有效矩形覆盖面积 新建一个类用来记录矩形信息,和一个链表用来记录每个矩形 每次新的矩形,首先跟前面的矩形依次去比较是否有相交的,若有则取出之前那个矩形,计算覆盖面积 没有就放入链表 100% 第三题: 手势密码 由于点的个数是固定值,所以总共也就C92=36种线条情况 每种情况编号
-
 互娱C++岗 秋招笔试题
互娱C++岗 秋招笔试题互娱C++岗 秋招笔试题 第二题:
-
PCI ( 外设部件互连标准 )
Peripheral Component Interconnect ( PCI ),好像它的名字暗示的一样,是描述如何通过一个结构化和可控制的方式把系统中的外设组件连接起来的一个标准。标准的 PCI Local Bus 规范描述了系统组件电气连接的方法和它们行为的方法。本章探讨 Linux 核心如何初始化系统的 PCI 总线和设备。 图 6.1 是一个 PCI 基础的系统的逻辑图。 PCI 总线和
-
互联网是如何工作的?
本章内容衍生自Jessica McKellar的演讲“互联网是怎幺工作的” (http://web.mit.edu/jesstess/www/) 。 我们猜你每天在使用互联网。但是当你在浏览器里输入一个像 https://djangogirls.org 的地址并按 回车键的时候,你真的知道背后发生了什幺吗? 你需要了解的第一件事是一个网站只是一堆保存在硬盘上的文件。 就像你的电影、 音乐或图片一样
-
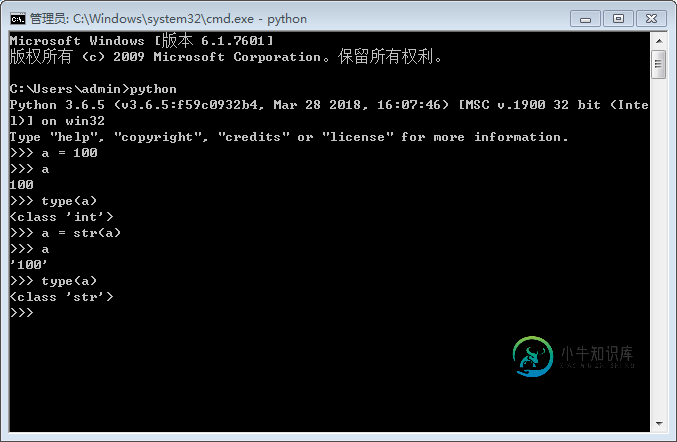 python中int与str互转方法
python中int与str互转方法本文向大家介绍python中int与str互转方法,包括了python中int与str互转方法的使用技巧和注意事项,需要的朋友参考一下 最近学习python中的数据类型时,难免联想到java中的基本型数据类型与引用型数据类型。于是对python中的int与str做了简单赋值输出,出现了意料之外的事情。 使用int(object)后,a与b的地址是一样的。 补充:python在给变量赋值时默认格式为
-
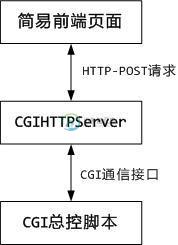 Python的CGIHTTPServer交互实现详解
Python的CGIHTTPServer交互实现详解本文向大家介绍Python的CGIHTTPServer交互实现详解,包括了Python的CGIHTTPServer交互实现详解的使用技巧和注意事项,需要的朋友参考一下 介绍 对于服务器后端开发者而言,有时候需要把自己的一些服务直接暴露给PM或者其他RD使用,这个时候需要搭建一套web服务可以和前端用户做简单交互,按照最常规的做法,一般是用Apache或者Nginx作为webserver后端使用cg
-
交互式Vim教程(例如vimtutor)
本文向大家介绍交互式Vim教程(例如vimtutor),包括了交互式Vim教程(例如vimtutor)的使用技巧和注意事项,需要的朋友参考一下 示例 vimtutor 是一个交互式教程,涵盖了文本编辑的最基本方面。 在类似UNIX的系统上,可以使用以下内容开始本教程: 在Windows上,可以在Windows菜单中“所有程序”下的“ Vim 7.x”目录中找到“ Vim tutor”。 有关:he
-
Django封装交互接口代码
本文向大家介绍Django封装交互接口代码,包括了Django封装交互接口代码的使用技巧和注意事项,需要的朋友参考一下 我就废话不多说了,大家还是直接看代码吧~ 补充知识:python部署galery集群 galery.py文件内容 以上这篇Django封装交互接口代码就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
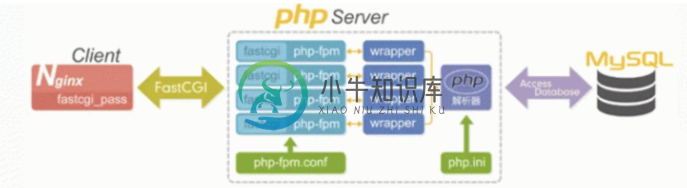 php和nginx交互实例讲解
php和nginx交互实例讲解本文向大家介绍php和nginx交互实例讲解,包括了php和nginx交互实例讲解的使用技巧和注意事项,需要的朋友参考一下 Nginx与PHP交互过程的7步走(用户对动态PHP网页访问过程) step1:用户将http请求发送给nginx服务器(用户和nginx服务器进行三次握手进行TCP连接)。 step2:nginx会根据用户访问的URL和后缀对请求进行判断。 step3:通过第二步可以看出,
-
AMQP RabbitMQ消费者相互封锁?
我编写了一个C(Rabbitmq-c)工作应用程序,它使用由Python脚本(pika)发布的队列。 我有以下奇怪的行为,我似乎无法解决: 在消息发布到队列之前启动所有工作人员按预期工作 队列发布后启动1个工作人员按预期工作 然而:在一个工作人员开始从队列中消费后启动其他工作人员意味着这些工作人员在队列中看不到任何消息(消息计数=0),因此只是等待(即使队列中还有许多消息)。杀死第一个工作人员会突
-
相互比较两个边界框
问题内容: 我有两个边界框的两个坐标,其中一个是地面坐标,另一个是我工作的结果。我想根据地雷来评估我的准确性。所以我问是否有人有任何建议 边框详细信息以这种格式保存 问题答案: 编辑:我已更正其他用户指出的错误。 我假设您正在检测某些对象,并且正在围绕它绘制一个边界框。这属于对象检测的广泛研究/研究领域。评估精度的最佳方法是计算并集交集。这是从PASCAL VOC挑战中获得的,这里。请参阅此处的视
-
通过Java与Django / Celery互操作
问题内容: 我们公司有一个基于Python的网站和一些基于Python的工作程序节点,它们通过Django / Celery和RabbitMQ进行通信。我有一个基于Java的应用程序,需要将任务提交给基于Celery的工作人员。我可以将作业从Java发送到RabbitMQ很好,但是基于Celery的工作人员从来没有接过工作。从查看两种类型的作业提交的数据包捕获来看,存在差异,但是我无法理解如何解释
-
MS Access互操作-数据导入
问题内容: 我正在开发一个将SQL导出到Access的exe,我们不想使用DTS,因为我们有多个客户端,每个客户端都导出不同的视图,并且设置和维护DTS包的开销太大。 *编辑:此过程每天晚上对许多客户都是自动化的,因此必须在存储过程中的游标中启动和控制整个过程。这是因为必须针对每个项目对数据进行过滤才能导出。 我尝试了多种方法将数据从SQL提取到Access中,最有前途的是使用Access互操作并
-
片段交互回调:onAttach()vs setter
我正在尝试实现一个好的、可重用的片段,我很难选择设置交互回调的模式。我当然熟悉这些文档,但我对其中描述的方法有一些疑问。 假设我们有一个带有回调接口的片段: 到目前为止,我遇到了两种为片段设置回调的方法。 Android开发指南中描述的方式。 编写的代码不多 mCallbacks永远不会为null(只要片段还活着) 如果我们在活动中使用多个片段,将会变得混乱 简单的侦听器模式。 可以在任何位置设置